Accelerating Large Language Model Inference with Self-Supervised Early Exits

0
💬
Sign in to get full access
Overview
- This paper presents a technique for accelerating inference in large, pre-trained language models (LLMs)
- The technique introduces early exits during inference, which can reduce the computational demands of these models
- The approach enables selective acceleration of the inference process by capitalizing on the inherent variability in token complexity
Plain English Explanation
Large language models like GPT-3 are incredibly powerful, but running them can be computationally expensive. The researchers behind this paper have developed a technique to make these models run faster in certain situations.
The key idea is to add "early exit" points to the model. During inference (when the model is being used to generate text), the model can sometimes determine that it is confident enough in its output and can stop processing early, without needing to go through the full model. This allows the model to run faster, especially on simpler inputs that don't require the full power of the model.
The researchers train these early exit points using the model's own predictions as training data, so no additional data is needed. They also calibrate the exit thresholds to ensure the model maintains the desired level of accuracy, even when exiting early.
This lightweight modification to the model architecture has the potential to make large language models much more practical to use, especially in real-time applications or resource-constrained environments.
Technical Explanation
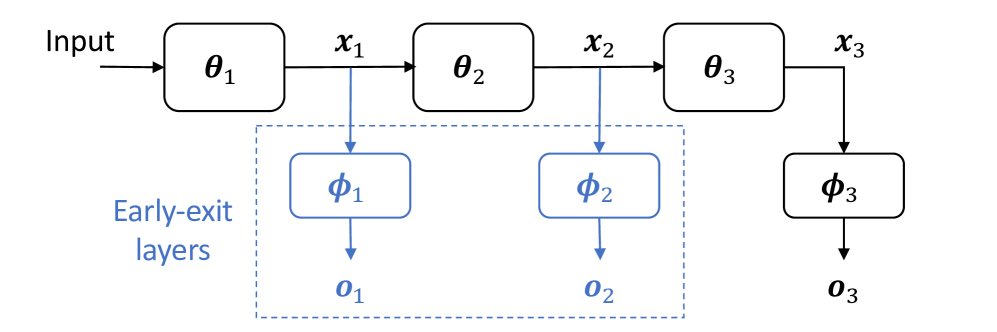
The key technical innovation in this paper is the integration of "early exit heads" atop the existing transformer layers in a pre-trained language model. These early exit heads provide a mechanism for the model to conditionally terminate the inference process based on a confidence metric, rather than always running the full model.
The researchers train these exit heads in a self-supervised manner, using the model's own predictions as the training data. This eliminates the need for any additional annotated data. The confidence metric is established using a calibration set, which ensures the desired level of accuracy is maintained even when the model exits early.
Notably, this approach preserves the original accuracy of the pre-trained model and simply reduces the computational time required for inference on certain tasks. It leverages the existing knowledge of the pre-trained model without requiring extensive retraining.
Critical Analysis
The paper provides a comprehensive evaluation of the proposed technique, demonstrating significant inference speedups across a variety of language tasks while maintaining model accuracy. However, the authors acknowledge that the effectiveness of the early exit mechanism may be task-dependent, and further research is needed to understand its limitations and generalization to other domains.
Additionally, the authors note that the calibration process to set the confidence thresholds may require careful tuning, as overly aggressive early exits could compromise model performance. Exploring more sophisticated confidence estimation techniques or adaptive thresholding approaches could be a fruitful area for future work.
Conclusion
This research presents a lightweight, modular approach to accelerating inference in large language models by introducing early exit points. By capitalizing on the inherent variability in token complexity, the technique enables selective acceleration of the inference process, reducing computational demands without compromising model accuracy.
This innovation has the potential to greatly enhance the practical usability of large language models, particularly in real-time applications and resource-constrained environments. As language models continue to grow in size and complexity, techniques like this will be crucial for unlocking their full potential and making them more accessible for a wide range of use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Accelerating Large Language Model Inference with Self-Supervised Early Exits
Florian Valade
This paper presents a novel technique for accelerating inference in large, pre-trained language models (LLMs) by introducing early exits during inference. The computational demands of these models, used across a wide range of applications, can be substantial. By capitalizing on the inherent variability in token complexity, our approach enables selective acceleration of the inference process. Specifically, we propose the integration of early exit ''heads'' atop existing transformer layers, which facilitate conditional terminations based on a confidence metric. These heads are trained in a self-supervised manner using the model's own predictions as training data, thereby eliminating the need for additional annotated data. The confidence metric, established using a calibration set, ensures a desired level of accuracy while enabling early termination when confidence exceeds a predetermined threshold. Notably, our method preserves the original accuracy and reduces computational time on certain tasks, leveraging the existing knowledge of pre-trained LLMs without requiring extensive retraining. This lightweight, modular modification has the potential to greatly enhance the practical usability of LLMs, particularly in applications like real-time language processing in resource-constrained environments.
Read more8/1/2024
🤯
0
Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed A Aly, Beidi Chen, Carole-Jean Wu
We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit. Second, during inference, we show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, we present a novel self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model. Our proposed self-speculative decoding approach has less memory footprint than other speculative decoding approaches and benefits from shared compute and activations of the draft and verification stages. We run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domain, and finetuning on specific task. We implement our inference solution and show speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on TOPv2 semantic parsing task.
Read more4/30/2024

0
An Efficient Inference Framework for Early-exit Large Language Models
Ruijie Miao, Yihan Yan, Xinshuo Yao, Tong Yang
Building efficient inference framework has gained increasing interests for research community. Early-exit models, a variant of LLMs, improves the inference efficiency of LLMs by skipping rest layers and directly generate output tokens when they are confident enough. However, there is no work of LLM inference framework that takes early-exit models into consideration. This is non-trivial as prior art on LLM inference cannot be directly applied to early-exit models. In this work, we solves two key challenges in building efficient inference framework for early-exit models: (1) batch inference at iteration-level granularity; and (2) KV cache management. For the former, we propose to process the batch until all sequences surpass the early-exit confidence threshold. For the latter, we propose to fill the KV cache of rest layers before the iteration terminates. Our evaluation shows that, compared with the original vLLM operating at full layers, our solution achieves up to 1.25x speed up.
Read more7/31/2024
0
EE-LLM: Large-Scale Training and Inference of Early-Exit Large Language Models with 3D Parallelism
Yanxi Chen, Xuchen Pan, Yaliang Li, Bolin Ding, Jingren Zhou
We present EE-LLM, a framework for large-scale training and inference of early-exit large language models (LLMs). While recent works have shown preliminary evidence for the efficacy of early exiting in accelerating LLM inference, EE-LLM makes a foundational step towards scaling up early-exit LLMs by supporting their training and inference with massive 3D parallelism. Built upon Megatron-LM, EE-LLM implements a variety of algorithmic innovations and performance optimizations tailored to early exiting, including a lightweight method that facilitates backpropagation for the early-exit training objective with pipeline parallelism, techniques of leveraging idle resources in the original pipeline schedule for computation related to early-exit layers, and two approaches of early-exit inference that are compatible with KV caching for autoregressive generation. Our analytical and empirical study shows that EE-LLM achieves great training efficiency with negligible computational overhead compared to standard LLM training, as well as outstanding inference speedup without compromising output quality. To facilitate further research and adoption, we release EE-LLM at https://github.com/pan-x-c/EE-LLM.
Read more6/18/2024