Layer Skip: Enabling Early Exit Inference and Self-Speculative Decoding
2404.16710
0
0
🤯
Abstract
We present LayerSkip, an end-to-end solution to speed-up inference of large language models (LLMs). First, during training we apply layer dropout, with low dropout rates for earlier layers and higher dropout rates for later layers, and an early exit loss where all transformer layers share the same exit. Second, during inference, we show that this training recipe increases the accuracy of early exit at earlier layers, without adding any auxiliary layers or modules to the model. Third, we present a novel self-speculative decoding solution where we exit at early layers and verify and correct with remaining layers of the model. Our proposed self-speculative decoding approach has less memory footprint than other speculative decoding approaches and benefits from shared compute and activations of the draft and verification stages. We run experiments on different Llama model sizes on different types of training: pretraining from scratch, continual pretraining, finetuning on specific data domain, and finetuning on specific task. We implement our inference solution and show speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on TOPv2 semantic parsing task.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers present LayerSkip, a solution to speed up inference of large language models (LLMs)
- During training, they apply layer dropout and an early exit loss to improve the accuracy of early exits
- During inference, they use a novel self-speculative decoding approach to exit at early layers and verify/correct with remaining layers
- Experiments show speedups of up to 2.16x on summarization, 1.82x on coding, and 2.0x on semantic parsing tasks
Plain English Explanation
The paper introduces a technique called LayerSkip that can make large language models run faster during inference (when the model is actually being used, rather than during training). Large language models like GPT-3 are very powerful but also computationally expensive to run, which can limit their real-world applications.
The researchers address this by training the model in a special way. First, they apply layer dropout, where the model is more likely to skip later layers of the neural network during training. This encourages the earlier layers to become more accurate at producing useful outputs. They also add an early exit loss, which means the model is penalized if its outputs at earlier layers aren't good enough.
Then, during actual inference (when the model is being used), the researchers use a novel self-speculative decoding approach. This means the model first tries to produce an output using only the earlier layers. If it's not confident in that output, it then uses the remaining layers to verify and potentially correct it. This allows the model to skip a lot of computation in cases where the earlier layers are sufficient, leading to faster inference times.
The researchers tested this on different sizes of the LLaMA language model, in various training scenarios like pretraining from scratch, continual pretraining, and fine-tuning. They found speedups ranging from 1.82x to 2.16x on tasks like summarization, coding, and semantic parsing.
Technical Explanation
The researchers present LayerSkip, an end-to-end solution to speed up inference of large language models (LLMs). During the training phase, they apply layer dropout, where the dropout rate is lower for earlier layers and higher for later layers. This encourages the earlier layers to become more accurate at producing useful outputs. They also add an early exit loss, where all transformer layers share the same exit, further incentivizing the earlier layers to perform well.
During inference, the researchers' training recipe increases the accuracy of early exits at earlier layers, without adding any auxiliary layers or modules to the model. They then introduce a novel self-speculative decoding approach, where the model first tries to produce an output using only the earlier layers. If it's not confident in that output, it then uses the remaining layers to verify and correct it. This self-speculative decoding approach has a lower memory footprint than other speculative decoding approaches, and benefits from shared compute and activations of the draft and verification stages.
The researchers run experiments on different sizes of the LLaMA model, under various training conditions: pretraining from scratch, continual pretraining, fine-tuning on specific data domains, and fine-tuning on specific tasks. They implement their inference solution and report speedups of up to 2.16x on summarization for CNN/DM documents, 1.82x on coding, and 2.0x on the TOPv2 semantic parsing task.
Critical Analysis
The paper presents a thorough and well-designed study on improving the inference efficiency of large language models. The researchers' use of layer dropout and early exit loss during training, coupled with their novel self-speculative decoding approach during inference, appears to be an effective and practical solution for speeding up LLM inference.
One potential limitation is that the experiments were conducted on a specific family of models (LLaMA) and a limited set of tasks. It would be valuable to see how well the LayerSkip approach generalizes to other LLM architectures and a broader range of applications. Additionally, the paper does not provide detailed analysis on the trade-offs between inference speedup and potential accuracy degradation, which would be important for practitioners to understand.
Further research could explore the underlying mechanisms and the extent to which the early layers are able to capture the necessary information for the tested tasks. Investigating the generalization of the self-speculative decoding approach to other types of LLMs, such as large-scale transformer-based models like GPT-3 or T5, would also be a valuable contribution to the field.
Overall, the LayerSkip technique presents an innovative and promising solution for accelerating LLM inference, with potential implications for improving the real-world applicability of these powerful models.
Conclusion
The researchers have presented LayerSkip, an end-to-end solution for speeding up the inference of large language models (LLMs). By applying layer dropout and an early exit loss during training, and using a novel self-speculative decoding approach during inference, they were able to achieve significant speedups of up to 2.16x on summarization tasks, 1.82x on coding, and 2.0x on semantic parsing.
This work is an important contribution to the field of efficient LLM inference, which is crucial for expanding the real-world applications of these powerful models. The LayerSkip technique demonstrates that it is possible to maintain high accuracy while dramatically reducing the computational cost of running large language models, opening up new possibilities for their deployment in resource-constrained environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
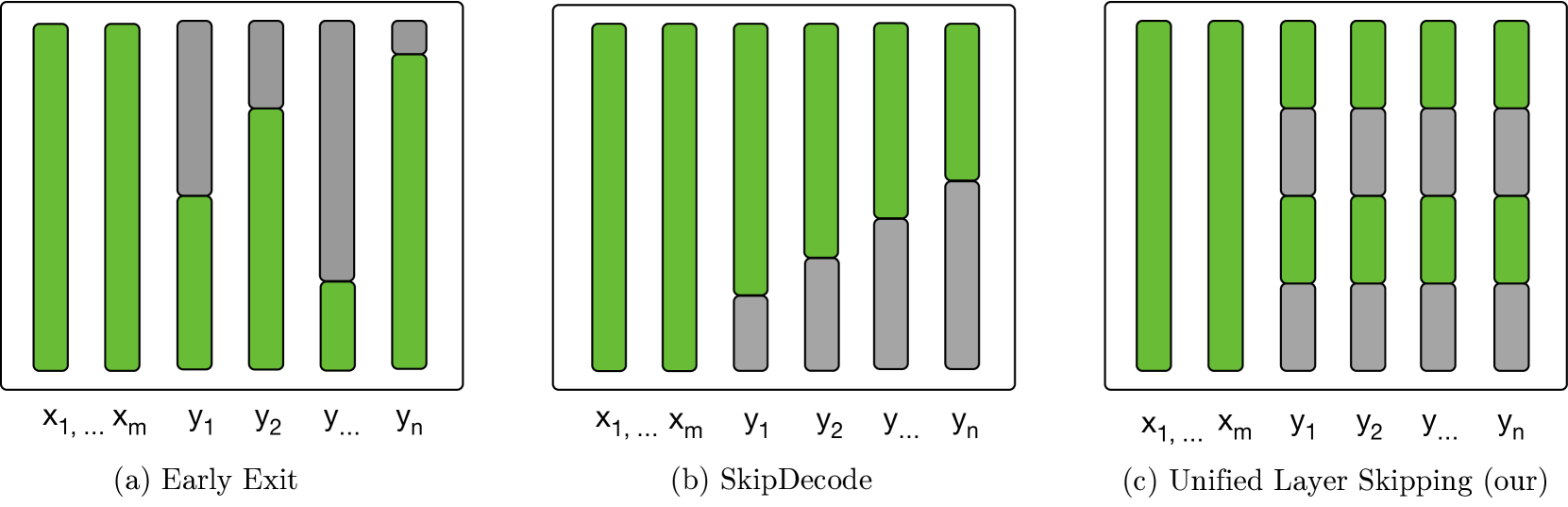
Accelerating Inference in Large Language Models with a Unified Layer Skipping Strategy
Yijin Liu, Fandong Meng, Jie Zhou
0
0
Recently, dynamic computation methods have shown notable acceleration for Large Language Models (LLMs) by skipping several layers of computations through elaborate heuristics or additional predictors. However, in the decoding process of existing approaches, different samples are assigned different computational budgets, which cannot guarantee a stable and precise acceleration effect. Furthermore, existing approaches generally skip multiple contiguous layers at the bottom or top of the layers, leading to a drastic change in the model's layer-wise representations, and thus a consequent performance degeneration. Therefore, we propose a Unified Layer Skipping strategy, which selects the number of layers to skip computation based solely on the target speedup ratio, and then skips the corresponding number of intermediate layer computations in a balanced manner. Since the Unified Layer Skipping strategy is independent of input samples, it naturally supports popular acceleration techniques such as batch decoding and KV caching, thus demonstrating more practicality for real-world applications. Experimental results on two common tasks, i.e., machine translation and text summarization, indicate that given a target speedup ratio, the Unified Layer Skipping strategy significantly enhances both the inference performance and the actual model throughput over existing dynamic approaches.
4/11/2024
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
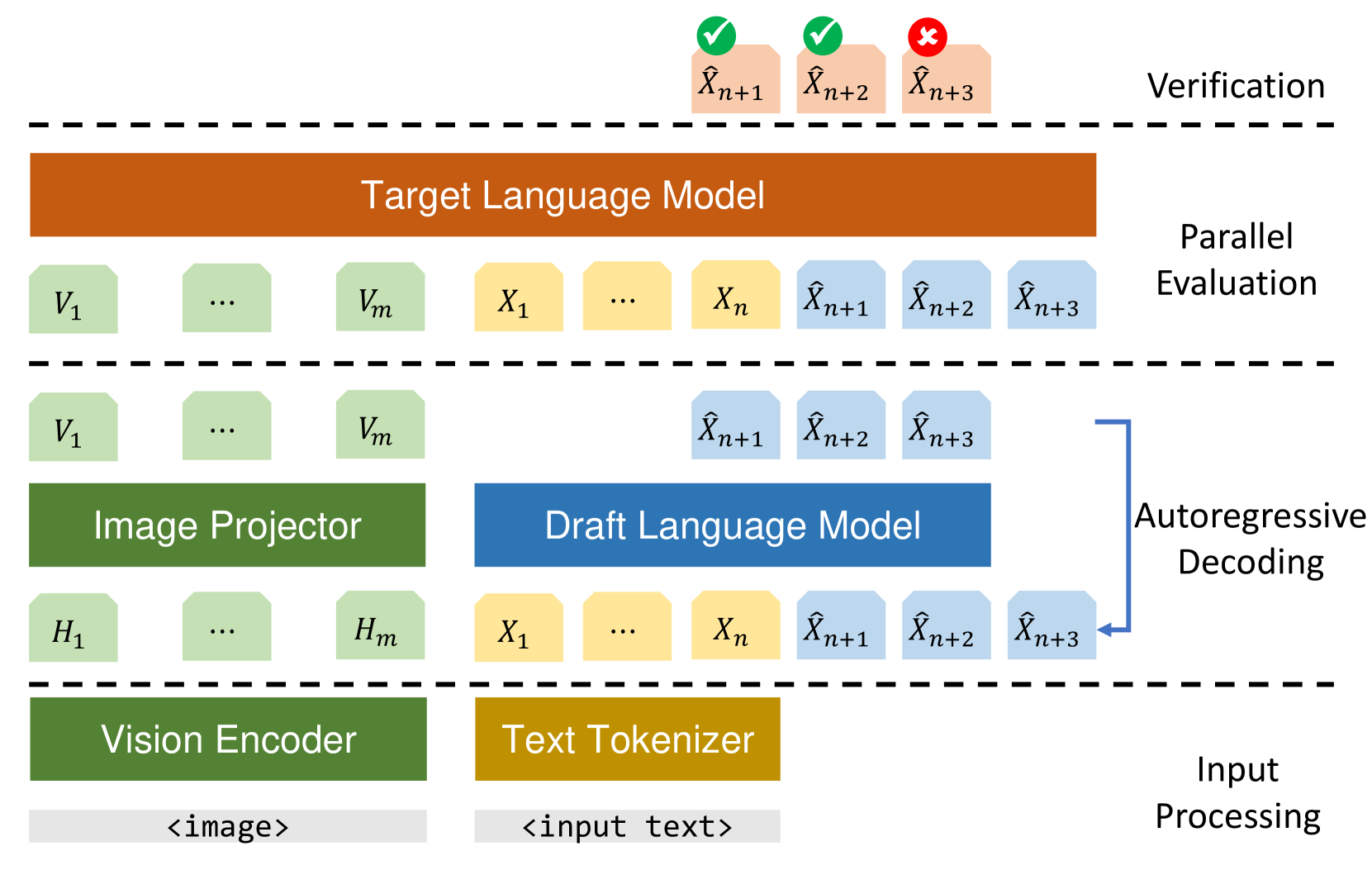
On Speculative Decoding for Multimodal Large Language Models
Mukul Gagrani, Raghavv Goel, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
0
0
Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
4/16/2024
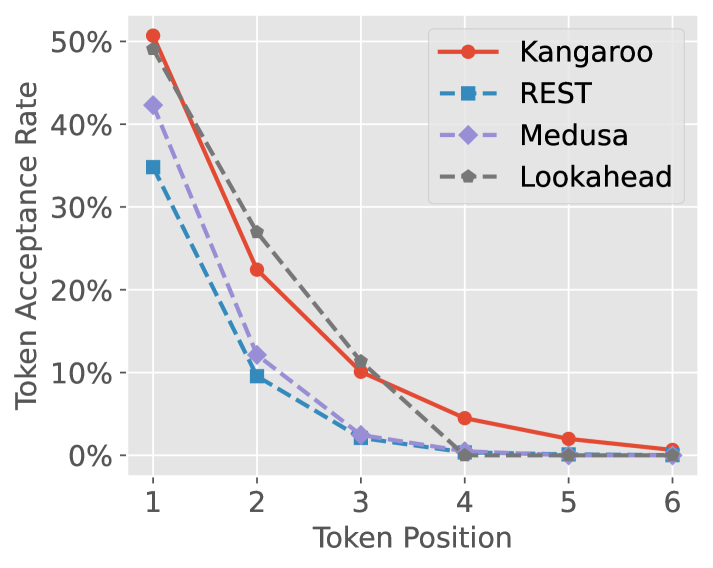
Kangaroo: Lossless Self-Speculative Decoding via Double Early Exiting
Fangcheng Liu, Yehui Tang, Zhenhua Liu, Yunsheng Ni, Kai Han, Yunhe Wang
0
0
Speculative decoding has demonstrated its effectiveness in accelerating the inference of large language models while maintaining a consistent sampling distribution. However, the conventional approach of training a separate draft model to achieve a satisfactory token acceptance rate can be costly. Drawing inspiration from early exiting, we propose a novel self-speculative decoding framework emph{Kangaroo}, which uses a fixed shallow sub-network as a self-draft model, with the remaining layers serving as the larger target model. We train a lightweight and efficient adapter module on top of the sub-network to bridge the gap between the sub-network and the full model's representation ability. It is noteworthy that the inference latency of the self-draft model may no longer be negligible compared to the large model, necessitating strategies to increase the token acceptance rate while minimizing the drafting steps of the small model. To address this challenge, we introduce an additional early exiting mechanism for generating draft tokens. Specifically, we halt the small model's subsequent prediction during the drafting phase once the confidence level for the current token falls below a certain threshold. Extensive experiments on the Spec-Bench demonstrate the effectiveness of Kangaroo. Under single-sequence verification, Kangaroo achieves speedups up to $1.68times$ on Spec-Bench, outperforming Medusa-1 with 88.7% fewer additional parameters (67M compared to 591M). The code for Kangaroo is available at https://github.com/Equationliu/Kangaroo.
4/30/2024