EE-LLM: Large-Scale Training and Inference of Early-Exit Large Language Models with 3D Parallelism

0
Sign in to get full access
Overview
- The paper presents a novel approach called EE-LLM (Early-Exit Large Language Models) that enables large-scale training and inference of large language models with early exits.
- EE-LLM leverages 3D parallelism, which combines model parallelism, data parallelism, and pipeline parallelism, to improve the training and inference efficiency of large language models.
- The authors demonstrate the effectiveness of EE-LLM on several benchmarks, showing improved performance and reduced computational costs compared to traditional large language models.
Plain English Explanation
The paper introduces a new way to train and use large language models, which are AI systems that can understand and generate human-like text. These models are getting increasingly powerful, but they also require a lot of computational resources to train and run.
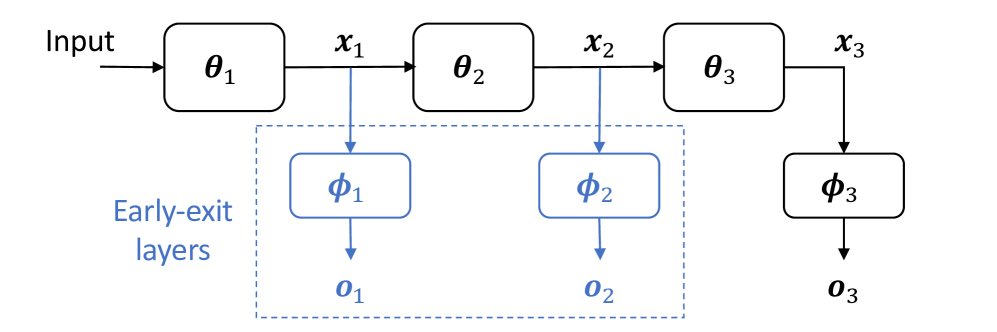
The key idea behind the researchers' approach, called EE-LLM, is to allow the language model to "exit" or finish its processing early, before it goes through all the model layers, if it is confident enough in its output. This can save a lot of computation time, especially for simple or straightforward inputs.
To make this early exit mechanism work efficiently, the researchers use a technique called 3D parallelism. This means they split up the work of training and running the language model across multiple data parallelism, model parallelism, and pipeline parallelism. This allows them to leverage the computational power of many different hardware devices at the same time.
The results show that EE-LLM can achieve better performance on various language tasks while using less computational power compared to traditional large language models. This could make it easier and more affordable to deploy these powerful AI systems in real-world applications.
Technical Explanation
The paper introduces a novel approach called EE-LLM (Early-Exit Large Language Models) that enables large-scale training and inference of large language models with early exits. EE-LLM leverages 3D parallelism, which combines model parallelism, data parallelism, and pipeline parallelism, to improve the training and inference efficiency of large language models.
The authors design an early-exit mechanism that allows the language model to exit the computation early if it is confident enough in its output, reducing the overall computational cost. To enable this early-exit mechanism, the authors propose a 3D parallelism scheme that divides the computation across multiple dimensions: model parallelism, data parallelism, and pipeline parallelism.
The model parallelism dimension splits the language model across multiple devices, the data parallelism dimension distributes the input data across multiple devices, and the pipeline parallelism dimension segments the language model into stages and processes the input in a pipelined fashion. This 3D parallelism approach allows for efficient utilization of hardware resources and enables large-scale training and inference of large language models with early exits.
The authors evaluate the effectiveness of EE-LLM on several benchmarks, including language modeling, question answering, and natural language inference tasks. The results demonstrate that EE-LLM can achieve improved performance and reduced computational costs compared to traditional large language models, making it a promising approach for deploying large language models in real-world applications.
Critical Analysis
The paper presents a well-designed and compelling approach to improving the efficiency of large language models through the use of early exits and 3D parallelism. The authors have clearly identified a significant challenge in training and deploying these large and computationally intensive models, and their solution offers a promising path forward.
One potential limitation of the EE-LLM approach is that the early-exit mechanism may not be equally effective for all types of language tasks or inputs. The authors acknowledge this and suggest that further research is needed to understand the factors that influence the effectiveness of early exits. Additionally, the 3D parallelism approach may require specialized hardware and infrastructure, which could limit its accessibility for some researchers and practitioners.
Furthermore, the paper does not delve deeply into the potential ethical implications of large language models, such as the risks of biased or misleading outputs, or the challenges of ensuring transparency and accountability in these systems. As these models become more powerful and widespread, it will be important for the research community to address these broader societal concerns.
Overall, the EE-LLM approach represents a significant advancement in the field of large language models, and the authors' work provides a solid foundation for future research and development in this area. By continuing to explore ways to improve the efficiency and effectiveness of these models, the research community can help to unlock their full potential for a wide range of applications.
Conclusion
The paper presents a novel approach called EE-LLM (Early-Exit Large Language Models) that enables large-scale training and inference of large language models with early exits. By leveraging 3D parallelism, which combines model parallelism, data parallelism, and pipeline parallelism, EE-LLM can improve the training and inference efficiency of large language models.
The authors demonstrate the effectiveness of EE-LLM on several benchmarks, showing improved performance and reduced computational costs compared to traditional large language models. This suggests that EE-LLM could be a valuable tool for deploying large language models in real-world applications, where computational resources and efficiency are critical.
While the paper offers a promising solution, it also highlights the need for further research to address the limitations and potential ethical concerns associated with large language models. As these powerful AI systems continue to evolve, it will be crucial for the research community to prioritize responsible development and deployment to ensure these technologies benefit society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EE-LLM: Large-Scale Training and Inference of Early-Exit Large Language Models with 3D Parallelism
Yanxi Chen, Xuchen Pan, Yaliang Li, Bolin Ding, Jingren Zhou
We present EE-LLM, a framework for large-scale training and inference of early-exit large language models (LLMs). While recent works have shown preliminary evidence for the efficacy of early exiting in accelerating LLM inference, EE-LLM makes a foundational step towards scaling up early-exit LLMs by supporting their training and inference with massive 3D parallelism. Built upon Megatron-LM, EE-LLM implements a variety of algorithmic innovations and performance optimizations tailored to early exiting, including a lightweight method that facilitates backpropagation for the early-exit training objective with pipeline parallelism, techniques of leveraging idle resources in the original pipeline schedule for computation related to early-exit layers, and two approaches of early-exit inference that are compatible with KV caching for autoregressive generation. Our analytical and empirical study shows that EE-LLM achieves great training efficiency with negligible computational overhead compared to standard LLM training, as well as outstanding inference speedup without compromising output quality. To facilitate further research and adoption, we release EE-LLM at https://github.com/pan-x-c/EE-LLM.
Read more6/18/2024

0
An Efficient Inference Framework for Early-exit Large Language Models
Ruijie Miao, Yihan Yan, Xinshuo Yao, Tong Yang
Building efficient inference framework has gained increasing interests for research community. Early-exit models, a variant of LLMs, improves the inference efficiency of LLMs by skipping rest layers and directly generate output tokens when they are confident enough. However, there is no work of LLM inference framework that takes early-exit models into consideration. This is non-trivial as prior art on LLM inference cannot be directly applied to early-exit models. In this work, we solves two key challenges in building efficient inference framework for early-exit models: (1) batch inference at iteration-level granularity; and (2) KV cache management. For the former, we propose to process the batch until all sequences surpass the early-exit confidence threshold. For the latter, we propose to fill the KV cache of rest layers before the iteration terminates. Our evaluation shows that, compared with the original vLLM operating at full layers, our solution achieves up to 1.25x speed up.
Read more7/31/2024
💬
0
Accelerating Large Language Model Inference with Self-Supervised Early Exits
Florian Valade
This paper presents a novel technique for accelerating inference in large, pre-trained language models (LLMs) by introducing early exits during inference. The computational demands of these models, used across a wide range of applications, can be substantial. By capitalizing on the inherent variability in token complexity, our approach enables selective acceleration of the inference process. Specifically, we propose the integration of early exit ''heads'' atop existing transformer layers, which facilitate conditional terminations based on a confidence metric. These heads are trained in a self-supervised manner using the model's own predictions as training data, thereby eliminating the need for additional annotated data. The confidence metric, established using a calibration set, ensures a desired level of accuracy while enabling early termination when confidence exceeds a predetermined threshold. Notably, our method preserves the original accuracy and reduces computational time on certain tasks, leveraging the existing knowledge of pre-trained LLMs without requiring extensive retraining. This lightweight, modular modification has the potential to greatly enhance the practical usability of LLMs, particularly in applications like real-time language processing in resource-constrained environments.
Read more8/1/2024
💬
0
Investigating the translation capabilities of Large Language Models trained on parallel data only
Javier Garc'ia Gilabert, Carlos Escolano, Aleix Sant Savall, Francesca De Luca Fornaciari, Audrey Mash, Xixian Liao, Maite Melero
In recent years, Large Language Models (LLMs) have demonstrated exceptional proficiency across a broad spectrum of Natural Language Processing (NLP) tasks, including Machine Translation. However, previous methods predominantly relied on iterative processes such as instruction fine-tuning or continual pre-training, leaving unexplored the challenges of training LLMs solely on parallel data. In this work, we introduce PLUME (Parallel Language Model), a collection of three 2B LLMs featuring varying vocabulary sizes (32k, 128k, and 256k) trained exclusively on Catalan-centric parallel examples. These models perform comparably to previous encoder-decoder architectures on 16 supervised translation directions and 56 zero-shot ones. Utilizing this set of models, we conduct a thorough investigation into the translation capabilities of LLMs, probing their performance, the impact of the different elements of the prompt, and their cross-lingual representation space.
Read more6/14/2024