Accelerating Production LLMs with Combined Token/Embedding Speculators
2404.19124
0
0
Abstract
This technical report describes the design and training of novel speculative decoding draft models, for accelerating the inference speeds of large language models in a production environment. By conditioning draft predictions on both context vectors and sampled tokens, we can train our speculators to efficiently predict high-quality n-grams, which the base model then accepts or rejects. This allows us to effectively predict multiple tokens per inference forward pass, accelerating wall-clock inference speeds of highly optimized base model implementations by a factor of 2-3x. We explore these initial results and describe next steps for further improvements.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel technique called "combined token/embedding speculators" to accelerate the production of large language models (LLMs).
- The key idea is to leverage speculative execution to predict both the tokens and their embeddings, which can significantly speed up the inference process.
- The proposed approach is evaluated on several benchmark tasks and shows substantial performance improvements over existing methods.
Plain English Explanation
The paper introduces a new way to make large language models run faster. Large language models are powerful AI systems that can understand and generate human-like text, but they can be quite slow to use. The researchers' approach tries to predict both the words the model will generate and the numerical representations (called "embeddings") of those words, all at the same time.
By speculating about what the model will do before it actually does it, the system can run much more efficiently. This speculative decoding technique builds on prior work on speculative execution in large language models.
The authors test their method on several benchmark tasks and find that it significantly speeds up the model's performance, making large language models faster and more efficient to use in real-world applications. This could help enable parallel decoding and make large language models more practical to deploy.
Technical Explanation
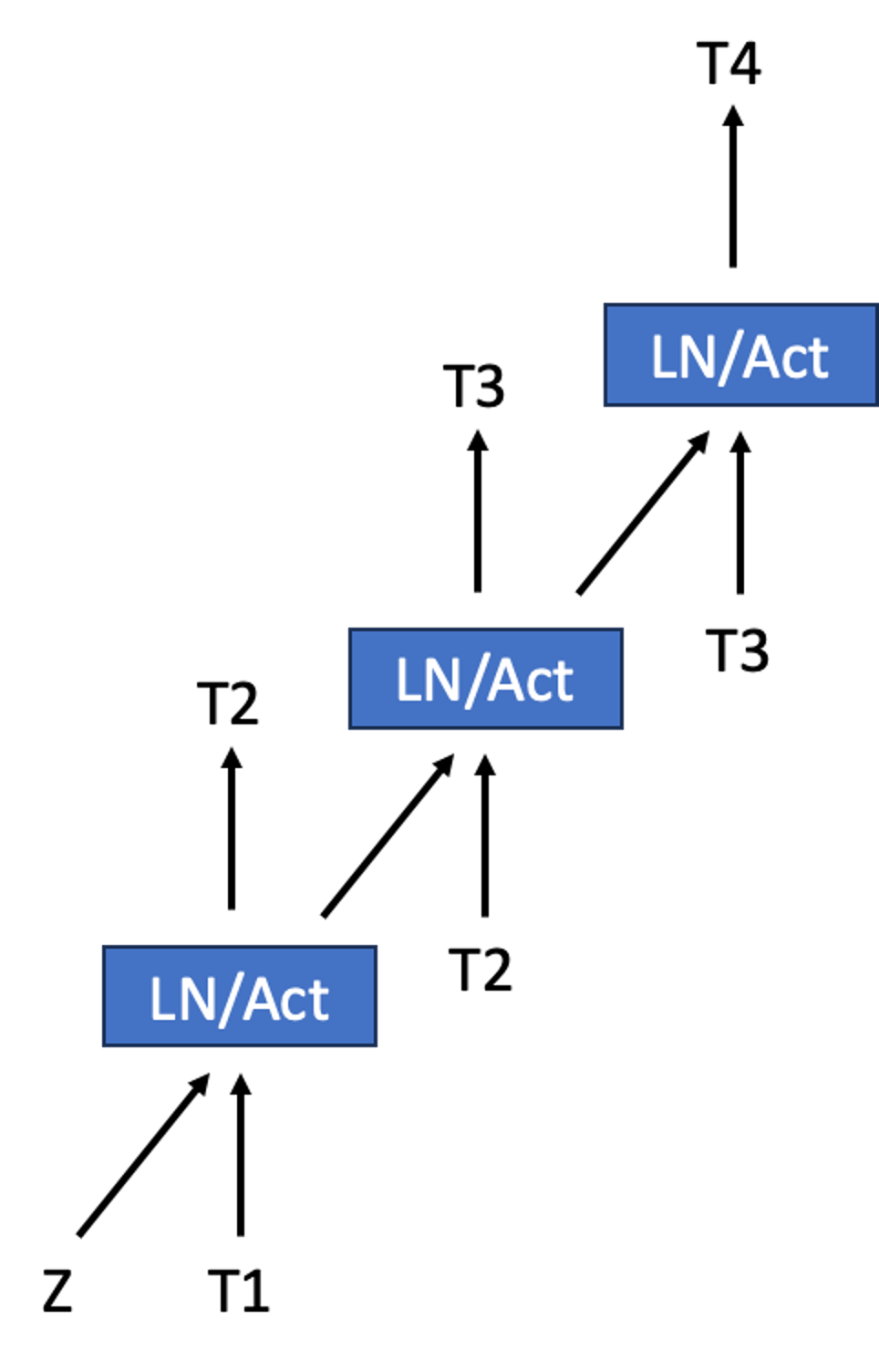
The key innovation in this paper is the "combined token/embedding speculator" module, which predicts both the next token and its associated embedding simultaneously. This builds on prior work in speculative decoding and parallel decoding for LLMs.
The speculator module is trained alongside the main LLM using a multi-task objective that combines token prediction and embedding prediction losses. During inference, the speculator can generate token and embedding predictions ahead of time, allowing the main model to skip computation and run more efficiently.
The authors evaluate their approach on a range of benchmark tasks, including language modeling, question answering, and text generation. Compared to baseline LLM models, the combined token/embedding speculator demonstrates substantial speedups of up to 2.5x, with minimal accuracy degradation.
Critical Analysis
The paper presents a compelling approach for accelerating LLM inference, and the reported performance gains are impressive. However, the authors acknowledge several limitations and areas for future work.
One potential concern is the additional model complexity and training overhead introduced by the speculator module. It's not clear how this would scale as the underlying LLM grows in size and capability. The authors also note that the speculator's accuracy is heavily dependent on the quality of the LLM, so further improvements to the core model may be necessary.
Additionally, the paper focuses solely on single-task evaluation, whereas real-world applications often require LLMs to handle diverse inputs and outputs. It would be valuable to see how the combined token/embedding speculator performs in more realistic, multi-domain settings.
Finally, the authors do not explore potential fairness or safety implications of their approach. Speculative execution could amplify biases or other undesirable behaviors present in the underlying LLM, which would need to be carefully studied and mitigated.
Overall, this paper represents an important step forward in accelerating large language models, but further research is needed to fully understand the practical benefits and limitations of the combined token/embedding speculator approach.
Conclusion
This paper presents a novel technique called "combined token/embedding speculators" that can significantly speed up the inference of large language models. By predicting both the next token and its embedding simultaneously, the system can run more efficiently and provide substantial performance gains.
The authors demonstrate the effectiveness of their approach on several benchmark tasks, showing speedups of up to 2.5x with minimal accuracy degradation. This could help make large language models more practical and accessible for real-world applications.
While the paper highlights some limitations and areas for future work, the combined token/embedding speculator represents an important advance in accelerating the deployment of powerful language models. As research in this area continues to progress, we can expect to see even more efficient and capable large language models emerge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
On Speculative Decoding for Multimodal Large Language Models
Mukul Gagrani, Raghavv Goel, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
0
0
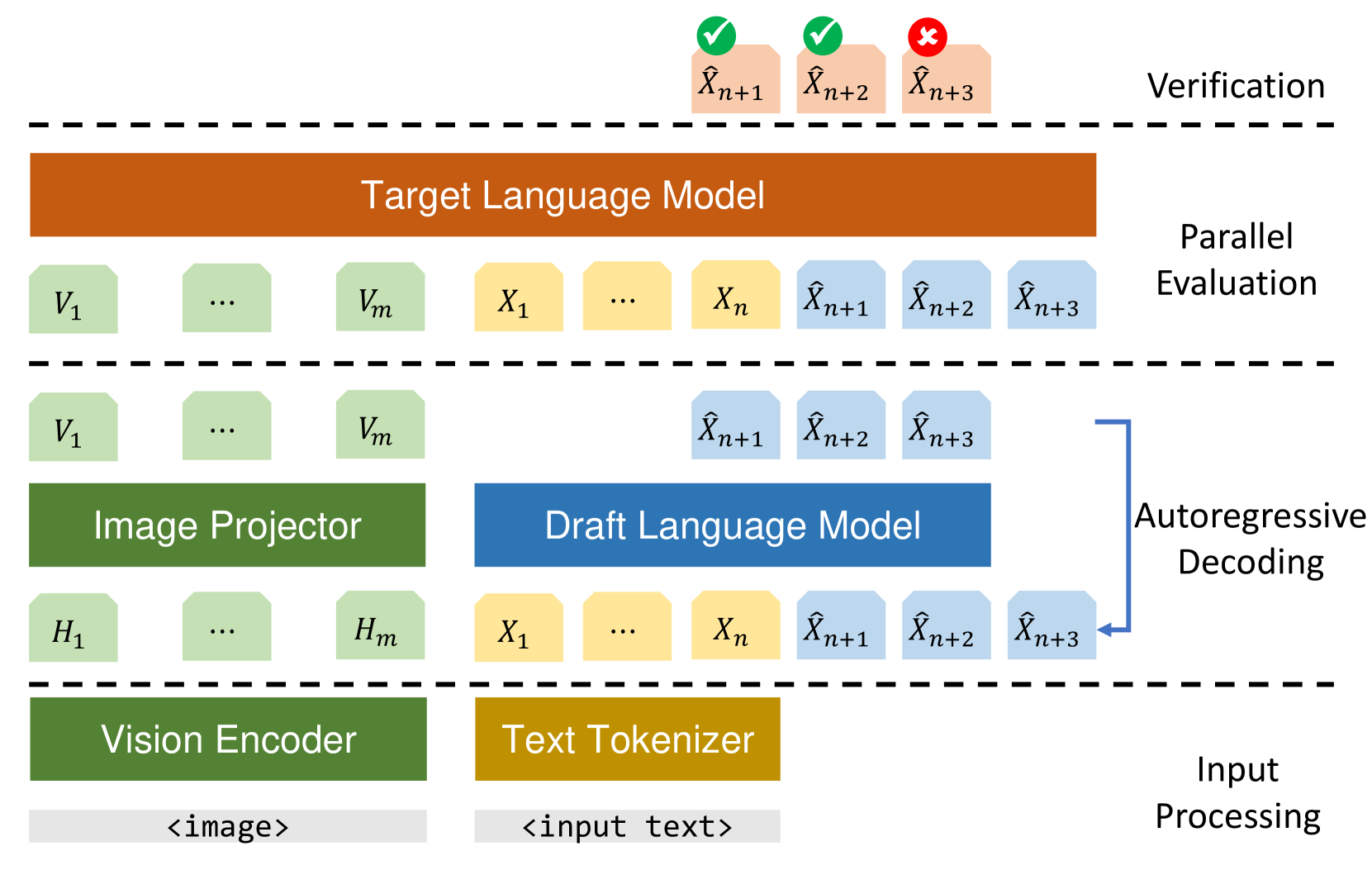
Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
4/16/2024
Decoding Speculative Decoding
Minghao Yan, Saurabh Agarwal, Shivaram Venkataraman
0
0
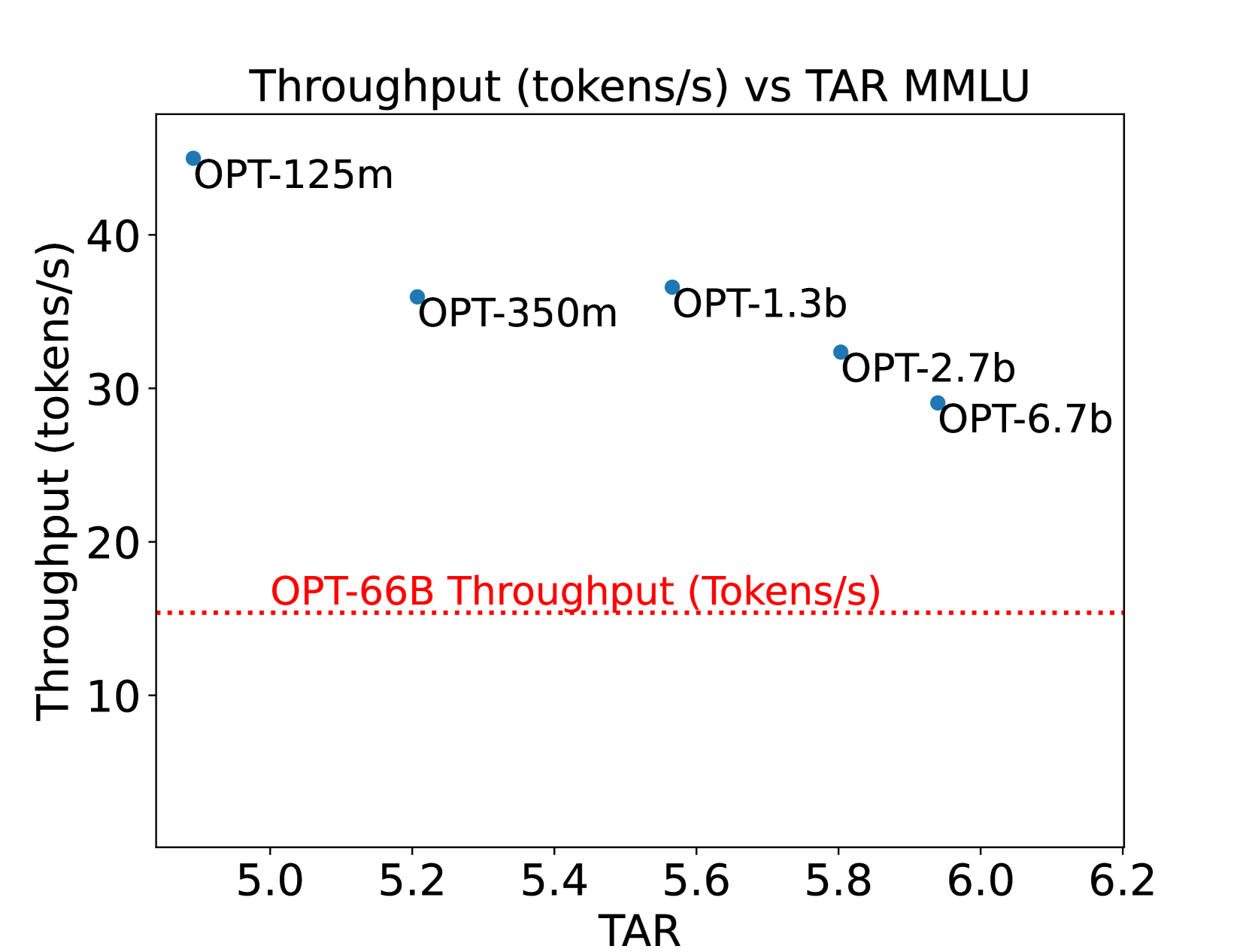
Speculative Decoding is a widely used technique to speed up inference for Large Language Models (LLMs) without sacrificing quality. When performing inference, speculative decoding uses a smaller draft model to generate speculative tokens and then uses the target LLM to verify those draft tokens. The speedup provided by speculative decoding heavily depends on the choice of the draft model. In this work, we perform a detailed study comprising over 350 experiments with LLaMA-65B and OPT-66B using speculative decoding and delineate the factors that affect the performance gain provided by speculative decoding. Our experiments indicate that the performance of speculative decoding depends heavily on the latency of the draft model, and the draft model's capability in language modeling does not correlate strongly with its performance in speculative decoding. Based on these insights we explore a new design space for draft models and design hardware-efficient draft models for speculative decoding. Our newly designed draft model for LLaMA-65B can provide 60% higher throughput than existing draft models and can generalize further to the LLaMA-2 model family and supervised fine-tuned models.
4/29/2024
Direct Alignment of Draft Model for Speculative Decoding with Chat-Fine-Tuned LLMs
Raghavv Goel, Mukul Gagrani, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
0
0
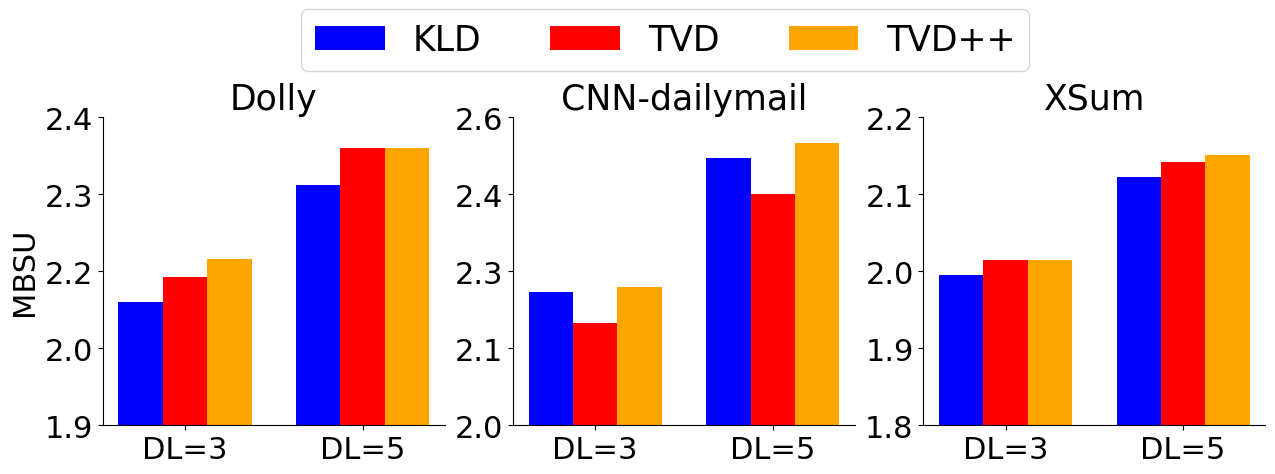
Text generation with Large Language Models (LLMs) is known to be memory bound due to the combination of their auto-regressive nature, huge parameter counts, and limited memory bandwidths, often resulting in low token rates. Speculative decoding has been proposed as a solution for LLM inference acceleration. However, since draft models are often unavailable in the modern open-source LLM families, e.g., for Llama 2 7B, training a high-quality draft model is required to enable inference acceleration via speculative decoding. In this paper, we propose a simple draft model training framework for direct alignment to chat-capable target models. With the proposed framework, we train Llama 2 Chat Drafter 115M, a draft model for Llama 2 Chat 7B or larger, with only 1.64% of the original size. Our training framework only consists of pretraining, distillation dataset generation, and finetuning with knowledge distillation, with no additional alignment procedure. For the finetuning step, we use instruction-response pairs generated by target model for distillation in plausible data distribution, and propose a new Total Variation Distance++ (TVD++) loss that incorporates variance reduction techniques inspired from the policy gradient method in reinforcement learning. Our empirical results show that Llama 2 Chat Drafter 115M with speculative decoding achieves up to 2.3 block efficiency and 2.4$times$ speed-up relative to autoregressive decoding on various tasks with no further task-specific fine-tuning.
5/15/2024
👀
Accelerating Speculative Decoding using Dynamic Speculation Length
Jonathan Mamou, Oren Pereg, Daniel Korat, Moshe Berchansky, Nadav Timor, Moshe Wasserblat, Roy Schwartz
0
0
Speculative decoding is a promising method for reducing the inference latency of large language models. The effectiveness of the method depends on the speculation length (SL) - the number of tokens generated by the draft model at each iteration. The vast majority of speculative decoding approaches use the same SL for all iterations. In this work, we show that this practice is suboptimal. We introduce DISCO, a DynamIc SpeCulation length Optimization method that uses a classifier to dynamically adjust the SL at each iteration, while provably preserving the decoding quality. Experiments with four benchmarks demonstrate average speedup gains of 10.3% relative to our best baselines.
5/8/2024