Beyond the Speculative Game: A Survey of Speculative Execution in Large Language Models
2404.14897
0
0
💬
Abstract
With the increasingly giant scales of (causal) large language models (LLMs), the inference efficiency comes as one of the core concerns along the improved performance. In contrast to the memory footprint, the latency bottleneck seems to be of greater importance as there can be billions of requests to a LLM (e.g., GPT-4) per day. The bottleneck is mainly due to the autoregressive innateness of LLMs, where tokens can only be generated sequentially during decoding. To alleviate the bottleneck, the idea of speculative execution, which originates from the field of computer architecture, is introduced to LLM decoding in a textit{draft-then-verify} style. Under this regime, a sequence of tokens will be drafted in a fast pace by utilizing some heuristics, and then the tokens shall be verified in parallel by the LLM. As the costly sequential inference is parallelized, LLM decoding speed can be significantly boosted. Driven by the success of LLMs in recent couple of years, a growing literature in this direction has emerged. Yet, there lacks a position survey to summarize the current landscape and draw a roadmap for future development of this promising area. To meet this demand, we present the very first survey paper that reviews and unifies literature of speculative execution in LLMs (e.g., blockwise parallel decoding, speculative decoding, etc.) in a comprehensive framework and a systematic taxonomy. Based on the taxonomy, we present a critical review and comparative analysis of the current arts. Finally we highlight various key challenges and future directions to further develop the area.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Examines the challenge of improving the inference efficiency of large language models (LLMs) as they scale to massive sizes
- Introduces the concept of speculative execution, which can parallelize the costly sequential inference process of LLMs
- Provides a comprehensive survey of literature on speculative execution techniques for LLMs, including blockwise parallel decoding, speculative decoding, and more
- Presents a taxonomy to systematically analyze and compare the current state of the art
- Highlights key challenges and future research directions in this promising area
Plain English Explanation
As large language models (LLMs) like GPT-4 continue to grow in size and capability, the efficiency of running these models, known as "inference," becomes a critical concern. The main bottleneck is the way LLMs generate text - they do it one word at a time in a sequential process. This makes the process slow, especially when there are billions of requests for the LLM per day.
To address this, the researchers introduce the idea of "speculative execution," which is a technique used in computer architecture to speed up processing. The idea is to quickly generate a draft sequence of tokens, and then verify them in parallel. This allows the costly sequential inference to be performed in parallel, significantly boosting the decoding speed of the LLM.
The paper provides a comprehensive survey of the various speculative execution techniques that have been proposed for LLMs, such as blockwise parallel decoding and speculative decoding. It presents a taxonomy to systematically analyze and compare these different approaches.
The key ideas are to leverage heuristics to quickly generate a draft output, and then verify that output in parallel using the full LLM. This allows the slow sequential processing to be sped up, making LLM inference much more efficient at scale.
Technical Explanation
The paper examines the challenge of improving the inference efficiency of large language models (LLMs) as they scale to massive sizes. In contrast to the memory footprint, the latency bottleneck seems to be of greater importance, as there can be billions of requests to an LLM (e.g., GPT-4) per day.
This bottleneck is mainly due to the autoregressive innateness of LLMs, where tokens can only be generated sequentially during decoding. To alleviate this, the researchers introduce the idea of speculative execution, which originates from the field of computer architecture.
Under this regime, a sequence of tokens will be drafted in a fast pace by utilizing some heuristics, and then the tokens shall be verified in parallel by the LLM. As the costly sequential inference is parallelized, LLM decoding speed can be significantly boosted.
The paper provides a comprehensive survey of the literature in this direction, including techniques such as blockwise parallel decoding, speculative decoding, and more. It presents a systematic taxonomy to analyze and compare the current state of the art.
Critical Analysis
The paper provides a thorough and well-structured survey of the techniques for improving the inference efficiency of large language models through speculative execution. The taxonomy presented offers a clear framework for understanding and comparing the different approaches.
However, the paper does not delve deeply into the potential limitations or challenges of these techniques. For example, the accuracy and reliability of the heuristics used for the initial drafting process could be a concern, as poor heuristics could lead to substantial errors that require significant correction during the verification stage.
Additionally, the paper does not address the potential trade-offs between the performance gains achieved through speculative execution and the additional computational resources required. As discussed in related research, there is often a spectrum of efficiency-accuracy trade-offs that need to be carefully considered.
Further research is needed to investigate the practical implications and real-world performance of these speculative execution techniques, as well as to explore ways to combine them with other optimization strategies for large language models.
Conclusion
This survey paper provides a comprehensive and systematic review of the literature on speculative execution techniques for improving the inference efficiency of large language models. The introduction of the speculative execution concept, along with the presented taxonomy, offers a valuable framework for understanding and advancing this promising area of research.
As LLMs continue to grow in scale and importance, the need for efficient inference will only become more critical. The insights and future research directions outlined in this paper can help guide the development of more scalable and responsive LLM systems, with potential benefits across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
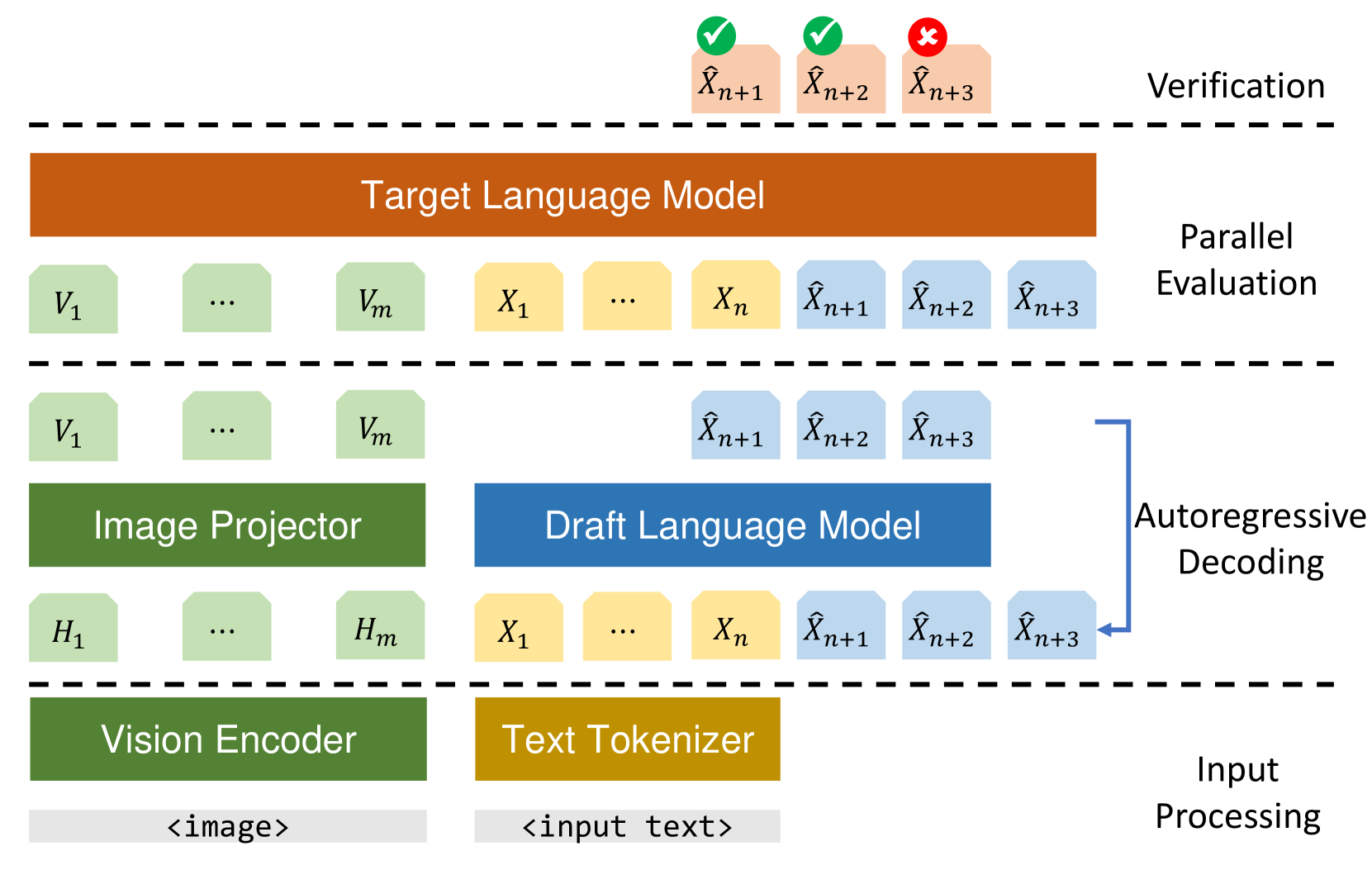
On Speculative Decoding for Multimodal Large Language Models
Mukul Gagrani, Raghavv Goel, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
0
0
Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
4/16/2024
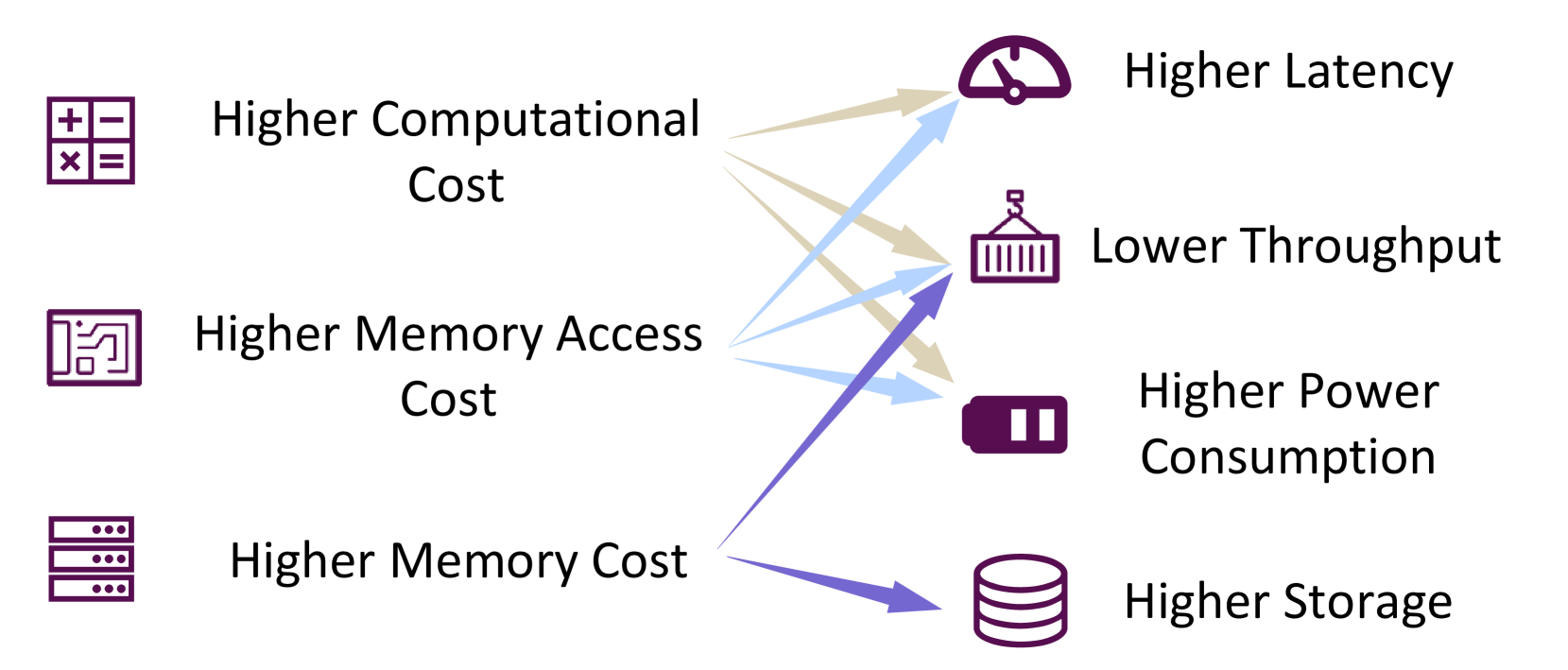
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang
0
0
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
4/23/2024
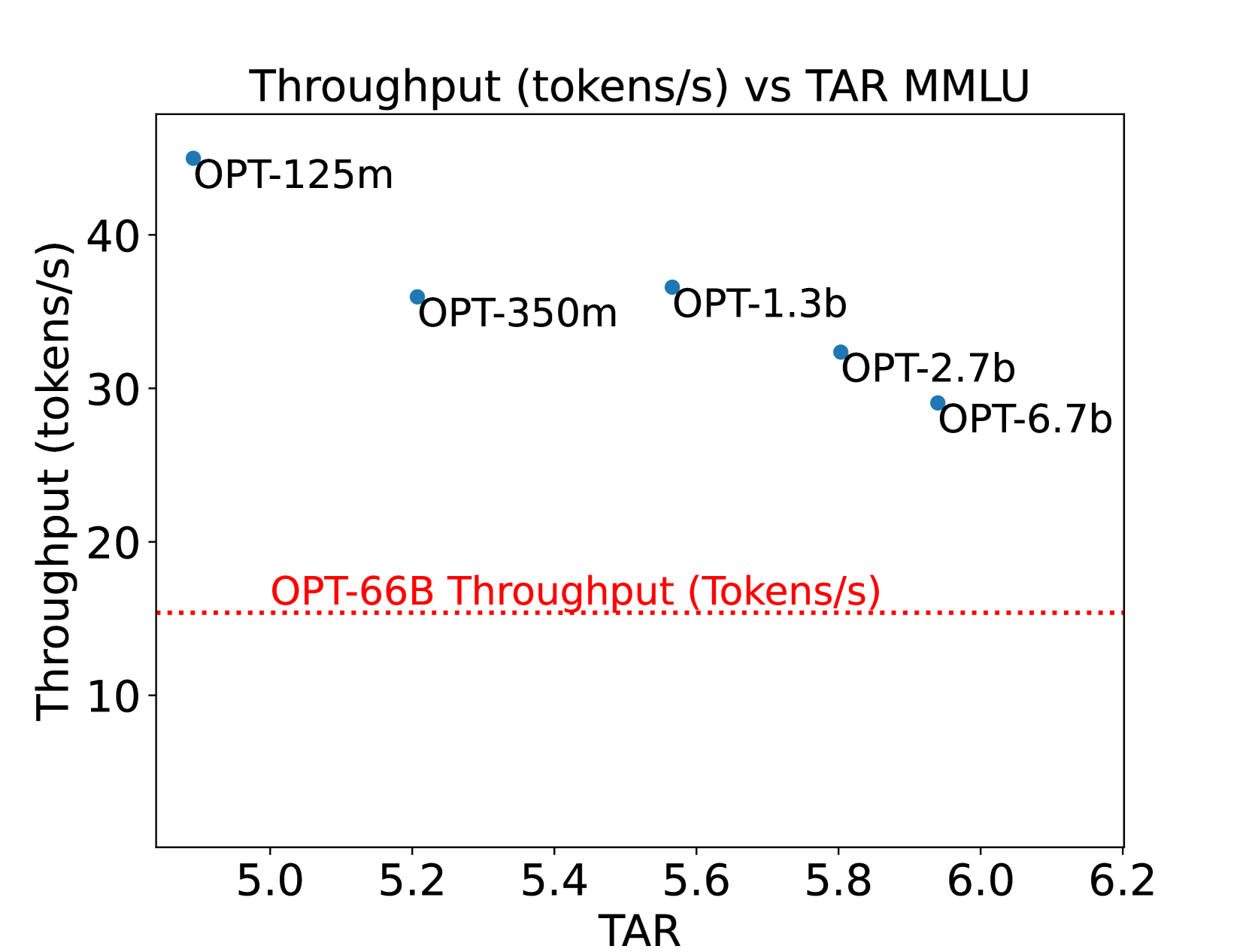
Decoding Speculative Decoding
Minghao Yan, Saurabh Agarwal, Shivaram Venkataraman
0
0
Speculative Decoding is a widely used technique to speed up inference for Large Language Models (LLMs) without sacrificing quality. When performing inference, speculative decoding uses a smaller draft model to generate speculative tokens and then uses the target LLM to verify those draft tokens. The speedup provided by speculative decoding heavily depends on the choice of the draft model. In this work, we perform a detailed study comprising over 350 experiments with LLaMA-65B and OPT-66B using speculative decoding and delineate the factors that affect the performance gain provided by speculative decoding. Our experiments indicate that the performance of speculative decoding depends heavily on the latency of the draft model, and the draft model's capability in language modeling does not correlate strongly with its performance in speculative decoding. Based on these insights we explore a new design space for draft models and design hardware-efficient draft models for speculative decoding. Our newly designed draft model for LLaMA-65B can provide 60% higher throughput than existing draft models and can generalize further to the LLaMA-2 model family and supervised fine-tuned models.
4/29/2024
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
Tianyu Ding, Tianyi Chen, Haidong Zhu, Jiachen Jiang, Yiqi Zhong, Jinxin Zhou, Guangzhi Wang, Zhihui Zhu, Ilya Zharkov, Luming Liang
0
0
The rapid growth of Large Language Models (LLMs) has been a driving force in transforming various domains, reshaping the artificial general intelligence landscape. However, the increasing computational and memory demands of these models present substantial challenges, hindering both academic research and practical applications. To address these issues, a wide array of methods, including both algorithmic and hardware solutions, have been developed to enhance the efficiency of LLMs. This survey delivers a comprehensive review of algorithmic advancements aimed at improving LLM efficiency. Unlike other surveys that typically focus on specific areas such as training or model compression, this paper examines the multi-faceted dimensions of efficiency essential for the end-to-end algorithmic development of LLMs. Specifically, it covers various topics related to efficiency, including scaling laws, data utilization, architectural innovations, training and tuning strategies, and inference techniques. This paper aims to serve as a valuable resource for researchers and practitioners, laying the groundwork for future innovations in this critical research area. Our repository of relevant references is maintained at url{https://github.com/tding1/Efficient-LLM-Survey}.
4/22/2024