Accelerating the Surrogate Retraining for Poisoning Attacks against Recommender Systems

0
Sign in to get full access
Overview
- This technical paper explores methods for accelerating the training of surrogate models used in poisoning attacks against recommender systems.
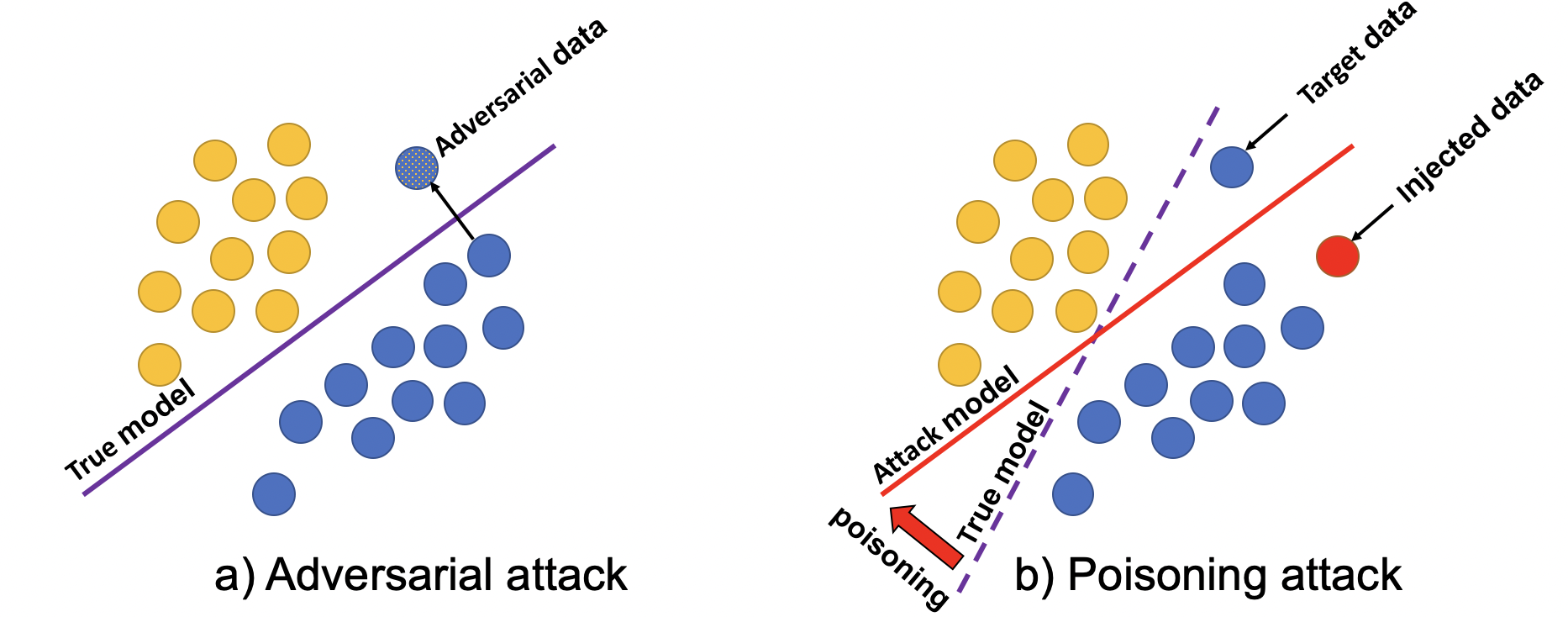
- Poisoning attacks involve injecting malicious data into a recommender system's training data to degrade its performance.
- The researchers propose techniques to speed up the retraining process for the surrogate model, which is a key component of these attacks.
Plain English Explanation
The paper focuses on a type of attack called a "poisoning attack" against recommender systems. Recommender systems are algorithms used by many online services to suggest products, content, or other items to users. Poisoning attacks try to trick these recommender systems by injecting misleading data into their training data. This can cause the recommender system to make worse suggestions.
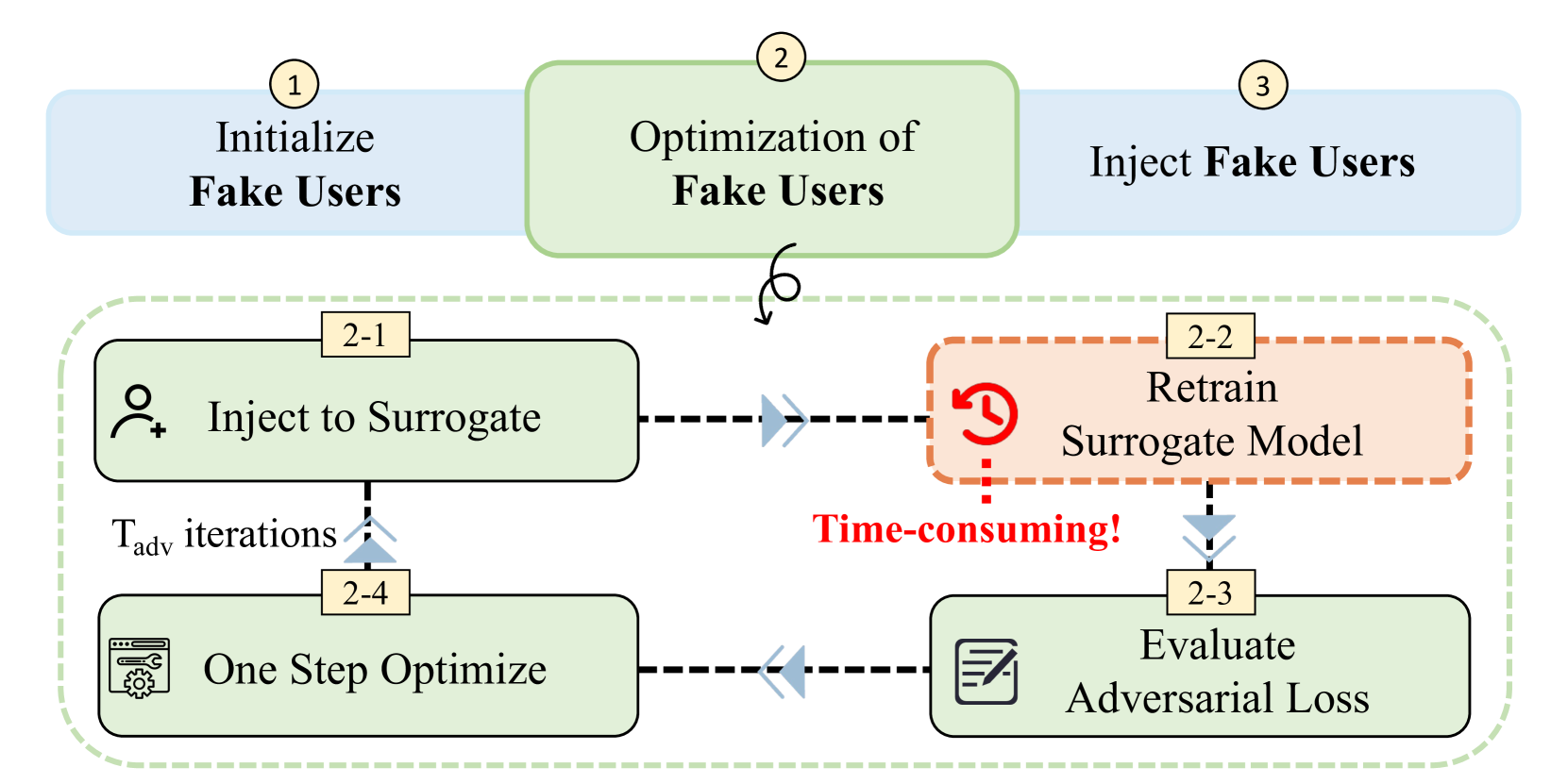
To carry out a poisoning attack, the attackers first create a "surrogate model" - a copy of the target recommender system that they can experiment on. They then have to repeatedly retrain this surrogate model as part of the attack process. The researchers in this paper looked at ways to make this retraining process faster and more efficient, which could make poisoning attacks more effective.
By speeding up the surrogate model retraining, the attackers can try out more variations of their attack and find the most effective way to manipulate the recommender system. This is an important technical advance that could have real-world implications for the security and reliability of recommender systems used in many online services.
Technical Explanation
The paper proposes two key techniques to accelerate the surrogate model retraining process for poisoning attacks:
-
Warm-Starting the Surrogate Model: Instead of retraining the surrogate model from scratch each time, the researchers suggest "warm-starting" it by using the previous iteration's model parameters as the initial point for the next retraining. This can significantly reduce the number of training iterations required.
-
Targeted Updates to the Surrogate Model: The researchers introduce a method to selectively update only the parts of the surrogate model that are most relevant to the attack, rather than retraining the entire model. This "targeted update" approach further improves the efficiency of the retraining process.
The paper evaluates these techniques on several real-world recommender system datasets. The results show that the proposed methods can reduce the surrogate model retraining time by over 80% compared to a baseline approach, while maintaining the effectiveness of the poisoning attack.
Critical Analysis
The paper provides a valuable technical contribution to the field of security and robustness for recommender systems. By improving the efficiency of the surrogate model retraining process, the proposed techniques could make poisoning attacks more practical and dangerous in real-world settings.
However, the paper does not address some important caveats and limitations. For example, it does not consider defenses or countermeasures that the target recommender system could employ to detect and mitigate these types of attacks. The evaluation is also limited to a few specific datasets and recommender system models.
Further research is needed to understand the broader implications and potential impact of these attack techniques, as well as to develop more robust and secure recommender systems that can withstand such adversarial manipulation.
Conclusion
This paper presents novel methods to accelerate the retraining of surrogate models used in poisoning attacks against recommender systems. By significantly reducing the computational cost of the attack process, the proposed techniques could make these types of attacks more practical and concerning for real-world applications.
While the technical contributions are valuable, the paper does not fully address the broader security implications and potential countermeasures. Ongoing research and development in this area will be crucial to ensuring the reliability and trustworthiness of recommender systems in the face of evolving adversarial threats.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Accelerating the Surrogate Retraining for Poisoning Attacks against Recommender Systems
Yunfan Wu, Qi Cao, Shuchang Tao, Kaike Zhang, Fei Sun, Huawei Shen
Recent studies have demonstrated the vulnerability of recommender systems to data poisoning attacks, where adversaries inject carefully crafted fake user interactions into the training data of recommenders to promote target items. Current attack methods involve iteratively retraining a surrogate recommender on the poisoned data with the latest fake users to optimize the attack. However, this repetitive retraining is highly time-consuming, hindering the efficient assessment and optimization of fake users. To mitigate this computational bottleneck and develop a more effective attack in an affordable time, we analyze the retraining process and find that a change in the representation of one user/item will cause a cascading effect through the user-item interaction graph. Under theoretical guidance, we introduce emph{Gradient Passing} (GP), a novel technique that explicitly passes gradients between interacted user-item pairs during backpropagation, thereby approximating the cascading effect and accelerating retraining. With just a single update, GP can achieve effects comparable to multiple original training iterations. Under the same number of retraining epochs, GP enables a closer approximation of the surrogate recommender to the victim. This more accurate approximation provides better guidance for optimizing fake users, ultimately leading to enhanced data poisoning attacks. Extensive experiments on real-world datasets demonstrate the efficiency and effectiveness of our proposed GP.
Read more8/21/2024

0
Poisoning Attacks and Defenses in Recommender Systems: A Survey
Zongwei Wang, Junliang Yu, Min Gao, Wei Yuan, Guanhua Ye, Shazia Sadiq, Hongzhi Yin
Modern recommender systems (RS) have profoundly enhanced user experience across digital platforms, yet they face significant threats from poisoning attacks. These attacks, aimed at manipulating recommendation outputs for unethical gains, exploit vulnerabilities in RS through injecting malicious data or intervening model training. This survey presents a unique perspective by examining these threats through the lens of an attacker, offering fresh insights into their mechanics and impacts. Concretely, we detail a systematic pipeline that encompasses four stages of a poisoning attack: setting attack goals, assessing attacker capabilities, analyzing victim architecture, and implementing poisoning strategies. The pipeline not only aligns with various attack tactics but also serves as a comprehensive taxonomy to pinpoint focuses of distinct poisoning attacks. Correspondingly, we further classify defensive strategies into two main categories: poisoning data filtering and robust training from the defender's perspective. Finally, we highlight existing limitations and suggest innovative directions for further exploration in this field.
Read more6/6/2024
0
Manipulating Recommender Systems: A Survey of Poisoning Attacks and Countermeasures
Thanh Toan Nguyen, Quoc Viet Hung Nguyen, Thanh Tam Nguyen, Thanh Trung Huynh, Thanh Thi Nguyen, Matthias Weidlich, Hongzhi Yin
Recommender systems have become an integral part of online services to help users locate specific information in a sea of data. However, existing studies show that some recommender systems are vulnerable to poisoning attacks, particularly those that involve learning schemes. A poisoning attack is where an adversary injects carefully crafted data into the process of training a model, with the goal of manipulating the system's final recommendations. Based on recent advancements in artificial intelligence, such attacks have gained importance recently. While numerous countermeasures to poisoning attacks have been developed, they have not yet been systematically linked to the properties of the attacks. Consequently, assessing the respective risks and potential success of mitigation strategies is difficult, if not impossible. This survey aims to fill this gap by primarily focusing on poisoning attacks and their countermeasures. This is in contrast to prior surveys that mainly focus on attacks and their detection methods. Through an exhaustive literature review, we provide a novel taxonomy for poisoning attacks, formalise its dimensions, and accordingly organise 30+ attacks described in the literature. Further, we review 40+ countermeasures to detect and/or prevent poisoning attacks, evaluating their effectiveness against specific types of attacks. This comprehensive survey should serve as a point of reference for protecting recommender systems against poisoning attacks. The article concludes with a discussion on open issues in the field and impactful directions for future research. A rich repository of resources associated with poisoning attacks is available at https://github.com/tamlhp/awesome-recsys-poisoning.
Read more4/24/2024
🤷
0
Unveiling Vulnerabilities of Contrastive Recommender Systems to Poisoning Attacks
Zongwei Wang, Junliang Yu, Min Gao, Hongzhi Yin, Bin Cui, Shazia Sadiq
Contrastive learning (CL) has recently gained prominence in the domain of recommender systems due to its great ability to enhance recommendation accuracy and improve model robustness. Despite its advantages, this paper identifies a vulnerability of CL-based recommender systems that they are more susceptible to poisoning attacks aiming to promote individual items. Our analysis indicates that this vulnerability is attributed to the uniform spread of representations caused by the InfoNCE loss. Furthermore, theoretical and empirical evidence shows that optimizing this loss favors smooth spectral values of representations. This finding suggests that attackers could facilitate this optimization process of CL by encouraging a more uniform distribution of spectral values, thereby enhancing the degree of representation dispersion. With these insights, we attempt to reveal a potential poisoning attack against CL-based recommender systems, which encompasses a dual-objective framework: one that induces a smoother spectral value distribution to amplify the InfoNCE loss's inherent dispersion effect, named dispersion promotion; and the other that directly elevates the visibility of target items, named rank promotion. We validate the threats of our attack model through extensive experimentation on four datasets. By shedding light on these vulnerabilities, our goal is to advance the development of more robust CL-based recommender systems. The code is available at url{https://github.com/CoderWZW/ARLib}.
Read more5/28/2024