Unveiling Vulnerabilities of Contrastive Recommender Systems to Poisoning Attacks

0
🤷
Sign in to get full access
Overview
- Contrastive learning (CL) has become popular in recommender systems, but this paper identifies a vulnerability where CL-based recommender systems are more susceptible to poisoning attacks that promote individual items.
- The paper analyzes how the uniform spread of representations caused by the InfoNCE loss used in CL contributes to this vulnerability.
- The authors propose a dual-objective poisoning attack that exploits this vulnerability, including techniques to induce a smoother spectral value distribution and directly elevate the visibility of target items.
- The threat of this attack is validated through extensive experiments on four datasets.
Plain English Explanation
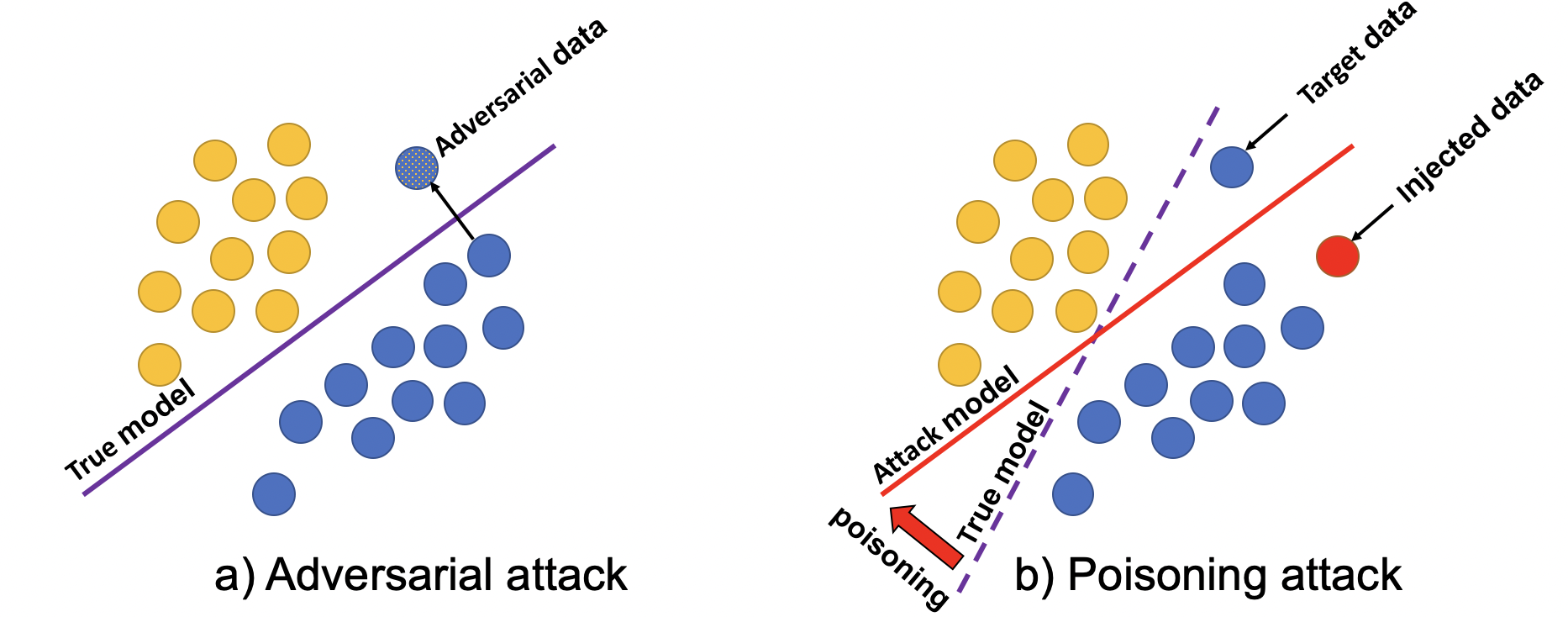
Contrastive learning (CL) is a technique that has become increasingly popular in recommender systems, as it can help improve the accuracy of recommendations and make the models more robust. However, this paper uncovers a weakness in CL-based recommender systems - they are more vulnerable to a type of attack called "poisoning attacks" that aim to promote specific items.
The key insight is that the way CL works, by trying to spread out the representations of items evenly, actually makes the system more susceptible to this kind of attack. Attackers can exploit this by manipulating the spectral properties of the item representations, essentially making them more uniform. This makes it easier for the attackers to boost the visibility of their target items.
The paper proposes a two-part attack strategy to take advantage of this vulnerability. First, the attackers try to adjust the spectral distribution of the item representations to amplify the inherent dispersion effect of the CL approach. Then, they directly try to increase the rankings of their target items.
Through extensive experiments, the authors demonstrate the real-world threat posed by this attack approach. The goal in highlighting these vulnerabilities is to spur the development of more robust CL-based recommender systems that are better protected against such malicious manipulation.
Technical Explanation
The paper identifies a vulnerability in contrastive learning (CL)-based recommender systems that makes them more susceptible to poisoning attacks aimed at promoting individual items.
Their analysis indicates that this vulnerability is due to the uniform spread of representations caused by the InfoNCE loss function used in CL. Theoretical and empirical evidence shows that optimizing this loss function favors smooth spectral values of the representations. This suggests that attackers can facilitate this optimization process by encouraging a more uniform distribution of spectral values, thereby enhancing the degree of representation dispersion.
To exploit this vulnerability, the authors propose a dual-objective poisoning attack framework:
- Dispersion Promotion: This component induces a smoother spectral value distribution to amplify the inherent dispersion effect of the InfoNCE loss.
- Rank Promotion: This component directly elevates the visibility of target items.
The authors validate the threats of their attack model through extensive experimentation on four datasets. By shedding light on these vulnerabilities, the goal is to drive the development of more robust CL-based recommender systems that are better protected against such malicious data poisoning and shilling attacks.
Critical Analysis
The paper provides a comprehensive analysis of a vulnerability in CL-based recommender systems, but there are a few areas that could be explored further:
-
Robustness to Variations: The experiments focus on a specific attack scenario, but it would be valuable to understand how the proposed attack performs under different conditions, such as varying levels of attack intensity or when combined with other attack strategies.
-
Countermeasure Evaluation: While the paper identifies the vulnerability, it does not propose or evaluate potential countermeasures to mitigate the threat. Exploring defense mechanisms would be an important next step.
-
Real-World Implications: The paper demonstrates the attack in a controlled experimental setting, but more research is needed to understand the real-world prevalence and impact of such attacks on live recommender systems.
-
Broader Implications: The vulnerability identified in this paper may not be limited to CL-based recommender systems. It would be worth investigating if similar issues exist in other machine learning-powered recommendation approaches.
Overall, this paper makes a valuable contribution by shedding light on a critical vulnerability in CL-based recommender systems. However, further research is needed to fully understand the scope of the problem and develop effective countermeasures.
Conclusion
This paper uncovers a concerning vulnerability in contrastive learning (CL)-based recommender systems that makes them more susceptible to poisoning attacks aimed at promoting specific items. The analysis reveals that the uniform spread of representations caused by the InfoNCE loss function used in CL contributes to this weakness, as it allows attackers to manipulate the spectral properties of the item representations to boost the visibility of their target items.
To exploit this vulnerability, the authors propose a dual-objective poisoning attack framework that first induces a smoother spectral value distribution to amplify the inherent dispersion effect of the CL approach, and then directly elevates the rankings of the target items. Through extensive experiments, the paper demonstrates the real-world threat posed by this attack.
By shedding light on these vulnerabilities, the goal is to drive the development of more robust CL-based recommender systems that are better protected against malicious data poisoning and shilling attacks. As machine learning continues to shape the future of recommender systems, understanding and addressing such security challenges will be crucial to ensuring the integrity and trustworthiness of these crucial technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Unveiling Vulnerabilities of Contrastive Recommender Systems to Poisoning Attacks
Zongwei Wang, Junliang Yu, Min Gao, Hongzhi Yin, Bin Cui, Shazia Sadiq
Contrastive learning (CL) has recently gained prominence in the domain of recommender systems due to its great ability to enhance recommendation accuracy and improve model robustness. Despite its advantages, this paper identifies a vulnerability of CL-based recommender systems that they are more susceptible to poisoning attacks aiming to promote individual items. Our analysis indicates that this vulnerability is attributed to the uniform spread of representations caused by the InfoNCE loss. Furthermore, theoretical and empirical evidence shows that optimizing this loss favors smooth spectral values of representations. This finding suggests that attackers could facilitate this optimization process of CL by encouraging a more uniform distribution of spectral values, thereby enhancing the degree of representation dispersion. With these insights, we attempt to reveal a potential poisoning attack against CL-based recommender systems, which encompasses a dual-objective framework: one that induces a smoother spectral value distribution to amplify the InfoNCE loss's inherent dispersion effect, named dispersion promotion; and the other that directly elevates the visibility of target items, named rank promotion. We validate the threats of our attack model through extensive experimentation on four datasets. By shedding light on these vulnerabilities, our goal is to advance the development of more robust CL-based recommender systems. The code is available at url{https://github.com/CoderWZW/ARLib}.
Read more5/28/2024
0
Manipulating Recommender Systems: A Survey of Poisoning Attacks and Countermeasures
Thanh Toan Nguyen, Quoc Viet Hung Nguyen, Thanh Tam Nguyen, Thanh Trung Huynh, Thanh Thi Nguyen, Matthias Weidlich, Hongzhi Yin
Recommender systems have become an integral part of online services to help users locate specific information in a sea of data. However, existing studies show that some recommender systems are vulnerable to poisoning attacks, particularly those that involve learning schemes. A poisoning attack is where an adversary injects carefully crafted data into the process of training a model, with the goal of manipulating the system's final recommendations. Based on recent advancements in artificial intelligence, such attacks have gained importance recently. While numerous countermeasures to poisoning attacks have been developed, they have not yet been systematically linked to the properties of the attacks. Consequently, assessing the respective risks and potential success of mitigation strategies is difficult, if not impossible. This survey aims to fill this gap by primarily focusing on poisoning attacks and their countermeasures. This is in contrast to prior surveys that mainly focus on attacks and their detection methods. Through an exhaustive literature review, we provide a novel taxonomy for poisoning attacks, formalise its dimensions, and accordingly organise 30+ attacks described in the literature. Further, we review 40+ countermeasures to detect and/or prevent poisoning attacks, evaluating their effectiveness against specific types of attacks. This comprehensive survey should serve as a point of reference for protecting recommender systems against poisoning attacks. The article concludes with a discussion on open issues in the field and impactful directions for future research. A rich repository of resources associated with poisoning attacks is available at https://github.com/tamlhp/awesome-recsys-poisoning.
Read more4/24/2024

0
Robust Federated Contrastive Recommender System against Model Poisoning Attack
Wei Yuan, Chaoqun Yang, Liang Qu, Guanhua Ye, Quoc Viet Hung Nguyen, Hongzhi Yin
Federated Recommender Systems (FedRecs) have garnered increasing attention recently, thanks to their privacy-preserving benefits. However, the decentralized and open characteristics of current FedRecs present two dilemmas. First, the performance of FedRecs is compromised due to highly sparse on-device data for each client. Second, the system's robustness is undermined by the vulnerability to model poisoning attacks launched by malicious users. In this paper, we introduce a novel contrastive learning framework designed to fully leverage the client's sparse data through embedding augmentation, referred to as CL4FedRec. Unlike previous contrastive learning approaches in FedRecs that necessitate clients to share their private parameters, our CL4FedRec aligns with the basic FedRec learning protocol, ensuring compatibility with most existing FedRec implementations. We then evaluate the robustness of FedRecs equipped with CL4FedRec by subjecting it to several state-of-the-art model poisoning attacks. Surprisingly, our observations reveal that contrastive learning tends to exacerbate the vulnerability of FedRecs to these attacks. This is attributed to the enhanced embedding uniformity, making the polluted target item embedding easily proximate to popular items. Based on this insight, we propose an enhanced and robust version of CL4FedRec (rCL4FedRec) by introducing a regularizer to maintain the distance among item embeddings with different popularity levels. Extensive experiments conducted on four commonly used recommendation datasets demonstrate that CL4FedRec significantly enhances both the model's performance and the robustness of FedRecs.
Read more4/1/2024

0
Poisoning Attacks and Defenses in Recommender Systems: A Survey
Zongwei Wang, Junliang Yu, Min Gao, Wei Yuan, Guanhua Ye, Shazia Sadiq, Hongzhi Yin
Modern recommender systems (RS) have profoundly enhanced user experience across digital platforms, yet they face significant threats from poisoning attacks. These attacks, aimed at manipulating recommendation outputs for unethical gains, exploit vulnerabilities in RS through injecting malicious data or intervening model training. This survey presents a unique perspective by examining these threats through the lens of an attacker, offering fresh insights into their mechanics and impacts. Concretely, we detail a systematic pipeline that encompasses four stages of a poisoning attack: setting attack goals, assessing attacker capabilities, analyzing victim architecture, and implementing poisoning strategies. The pipeline not only aligns with various attack tactics but also serves as a comprehensive taxonomy to pinpoint focuses of distinct poisoning attacks. Correspondingly, we further classify defensive strategies into two main categories: poisoning data filtering and robust training from the defender's perspective. Finally, we highlight existing limitations and suggest innovative directions for further exploration in this field.
Read more6/6/2024