Manipulating Recommender Systems: A Survey of Poisoning Attacks and Countermeasures
2404.14942
0
0
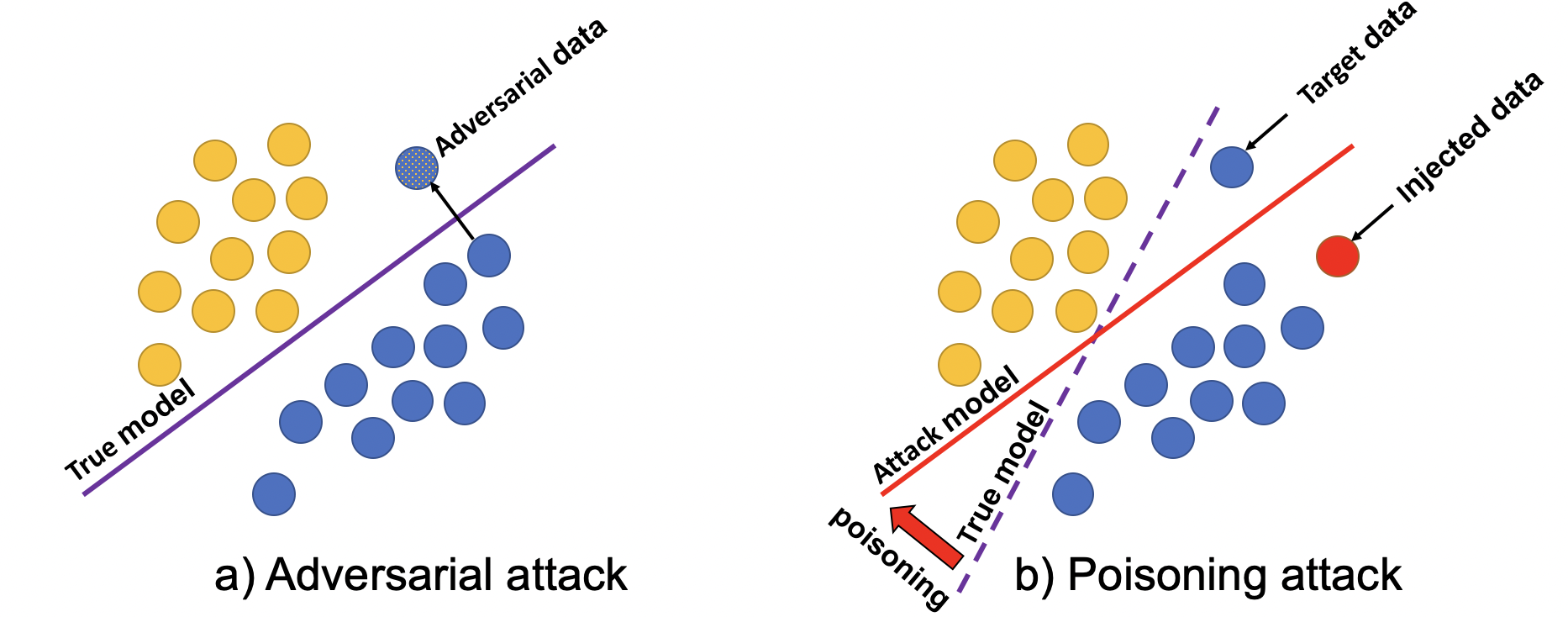
Abstract
Recommender systems have become an integral part of online services to help users locate specific information in a sea of data. However, existing studies show that some recommender systems are vulnerable to poisoning attacks, particularly those that involve learning schemes. A poisoning attack is where an adversary injects carefully crafted data into the process of training a model, with the goal of manipulating the system's final recommendations. Based on recent advancements in artificial intelligence, such attacks have gained importance recently. While numerous countermeasures to poisoning attacks have been developed, they have not yet been systematically linked to the properties of the attacks. Consequently, assessing the respective risks and potential success of mitigation strategies is difficult, if not impossible. This survey aims to fill this gap by primarily focusing on poisoning attacks and their countermeasures. This is in contrast to prior surveys that mainly focus on attacks and their detection methods. Through an exhaustive literature review, we provide a novel taxonomy for poisoning attacks, formalise its dimensions, and accordingly organise 30+ attacks described in the literature. Further, we review 40+ countermeasures to detect and/or prevent poisoning attacks, evaluating their effectiveness against specific types of attacks. This comprehensive survey should serve as a point of reference for protecting recommender systems against poisoning attacks. The article concludes with a discussion on open issues in the field and impactful directions for future research. A rich repository of resources associated with poisoning attacks is available at https://github.com/tamlhp/awesome-recsys-poisoning.
Create account to get full access
Overview
- This paper provides a comprehensive survey of poisoning attacks and countermeasures in recommender systems.
- Poisoning attacks aim to manipulate the recommendations made by a system, either by injecting malicious data during the training process or by exploiting vulnerabilities in the recommender algorithm.
- The paper categorizes different types of poisoning attacks, discusses their potential impacts, and reviews various defense strategies that have been proposed to mitigate these threats.
Plain English Explanation
Recommender systems are algorithms that suggest products, services, or content to users based on their preferences and behaviors. These systems are widely used by companies to personalize the user experience and drive engagement. However, they can also be vulnerable to poisoning attacks, where malicious actors try to manipulate the recommendations for their own benefit.
In a poisoning attack, the attacker may inject fake or misleading data into the system during the training process, causing the recommender to learn biased or incorrect patterns. This can lead to suboptimal or even harmful recommendations being provided to users. Attackers may also exploit vulnerabilities in the recommender algorithm itself, for example, by injecting carefully crafted inputs that cause the system to output desired recommendations.
This paper surveys the different types of poisoning attacks that have been identified, as well as the various countermeasures that have been proposed to defend against them. The researchers categorize the attacks based on factors like the attacker's goal, the attack method, and the specific vulnerabilities being exploited. They also review a range of defense strategies, such as robust federated learning and toxicity prediction, that aim to make recommender systems more resilient to these types of manipulations.
By understanding the potential threats and countermeasures, researchers and practitioners can work towards building more trustworthy and secure recommender systems that better protect the interests of users and businesses.
Technical Explanation
The paper begins by providing an overview of prior classifications and surveys of recommender systems, highlighting the need for a more focused exploration of poisoning attacks and defenses.
The authors then define the threat model and categorize different types of poisoning attacks. They identify three main attack goals: influence the recommendations to promote certain items, degrade the system's performance, or extract sensitive information. The attacks can be carried out by injecting malicious data during training (data-level attacks) or by exploiting vulnerabilities in the recommender algorithm (model-level attacks).
The paper discusses the potential impacts of these attacks, including reduced user satisfaction, financial losses for businesses, and privacy violations. It then reviews a range of defense strategies that have been proposed, such as robust federated learning, toxicity prediction, and semantic stealth attacks. These defenses aim to detect and mitigate poisoning attempts, while maintaining the recommender's performance and user experience.
The technical analysis covers the key components of the defense strategies, including their underlying assumptions, algorithms, and evaluation metrics. The authors also discuss the strengths and limitations of these approaches, highlighting areas for further research and development.
Critical Analysis
The paper provides a comprehensive and well-structured survey of poisoning attacks and countermeasures in recommender systems. The researchers have done a thorough job of categorizing the different attack types and defense strategies, which helps to build a clear understanding of the problem domain.
One potential limitation of the paper is that it focuses primarily on theoretical attacks and defenses, with limited discussion of real-world case studies or empirical evaluations. While the technical details are valuable, it would be helpful to see more examples of how these attacks and defenses have played out in practical settings.
Additionally, the paper does not delve deeply into the ethical implications of these attacks and defenses. As recommender systems become more prevalent and influential in our lives, it is crucial to consider the societal impact of manipulating these systems, both in terms of individual privacy and the broader effects on consumer behavior and decision-making.
Overall, this paper provides a solid foundation for understanding the threats and countermeasures in recommender systems. However, further research is needed to bridge the gap between theory and practice, and to address the broader ethical considerations surrounding the security and trustworthiness of these systems.
Conclusion
This survey paper offers a comprehensive overview of poisoning attacks and countermeasures in recommender systems. By categorizing the different attack types and defense strategies, the researchers have provided a valuable resource for researchers and practitioners working to build more secure and trustworthy recommender systems.
The paper highlights the significant potential for malicious actors to manipulate recommender systems, with impacts ranging from reduced user satisfaction to financial losses and privacy violations. The proposed defense strategies, such as robust federated learning and toxicity prediction, offer promising approaches to mitigate these threats.
As recommender systems become increasingly integral to our digital lives, it is crucial that researchers, developers, and policymakers work together to address the security and ethical challenges posed by poisoning attacks. By understanding the vulnerabilities and implementing effective countermeasures, we can strive to create recommender systems that are more reliable, transparent, and aligned with the interests of users and society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Poisoning Attacks and Defenses in Recommender Systems: A Survey
Zongwei Wang, Junliang Yu, Min Gao, Wei Yuan, Guanhua Ye, Shazia Sadiq, Hongzhi Yin
0
0
Modern recommender systems (RS) have profoundly enhanced user experience across digital platforms, yet they face significant threats from poisoning attacks. These attacks, aimed at manipulating recommendation outputs for unethical gains, exploit vulnerabilities in RS through injecting malicious data or intervening model training. This survey presents a unique perspective by examining these threats through the lens of an attacker, offering fresh insights into their mechanics and impacts. Concretely, we detail a systematic pipeline that encompasses four stages of a poisoning attack: setting attack goals, assessing attacker capabilities, analyzing victim architecture, and implementing poisoning strategies. The pipeline not only aligns with various attack tactics but also serves as a comprehensive taxonomy to pinpoint focuses of distinct poisoning attacks. Correspondingly, we further classify defensive strategies into two main categories: poisoning data filtering and robust training from the defender's perspective. Finally, we highlight existing limitations and suggest innovative directions for further exploration in this field.
6/6/2024
🤷
Unveiling Vulnerabilities of Contrastive Recommender Systems to Poisoning Attacks
Zongwei Wang, Junliang Yu, Min Gao, Hongzhi Yin, Bin Cui, Shazia Sadiq
0
0
Contrastive learning (CL) has recently gained prominence in the domain of recommender systems due to its great ability to enhance recommendation accuracy and improve model robustness. Despite its advantages, this paper identifies a vulnerability of CL-based recommender systems that they are more susceptible to poisoning attacks aiming to promote individual items. Our analysis indicates that this vulnerability is attributed to the uniform spread of representations caused by the InfoNCE loss. Furthermore, theoretical and empirical evidence shows that optimizing this loss favors smooth spectral values of representations. This finding suggests that attackers could facilitate this optimization process of CL by encouraging a more uniform distribution of spectral values, thereby enhancing the degree of representation dispersion. With these insights, we attempt to reveal a potential poisoning attack against CL-based recommender systems, which encompasses a dual-objective framework: one that induces a smoother spectral value distribution to amplify the InfoNCE loss's inherent dispersion effect, named dispersion promotion; and the other that directly elevates the visibility of target items, named rank promotion. We validate the threats of our attack model through extensive experimentation on four datasets. By shedding light on these vulnerabilities, our goal is to advance the development of more robust CL-based recommender systems. The code is available at url{https://github.com/CoderWZW/ARLib}.
5/28/2024
Transferable Availability Poisoning Attacks
Yiyong Liu, Michael Backes, Xiao Zhang
0
0
We consider availability data poisoning attacks, where an adversary aims to degrade the overall test accuracy of a machine learning model by crafting small perturbations to its training data. Existing poisoning strategies can achieve the attack goal but assume the victim to employ the same learning method as what the adversary uses to mount the attack. In this paper, we argue that this assumption is strong, since the victim may choose any learning algorithm to train the model as long as it can achieve some targeted performance on clean data. Empirically, we observe a large decrease in the effectiveness of prior poisoning attacks if the victim employs an alternative learning algorithm. To enhance the attack transferability, we propose Transferable Poisoning, which first leverages the intrinsic characteristics of alignment and uniformity to enable better unlearnability within contrastive learning, and then iteratively utilizes the gradient information from supervised and unsupervised contrastive learning paradigms to generate the poisoning perturbations. Through extensive experiments on image benchmarks, we show that our transferable poisoning attack can produce poisoned samples with significantly improved transferability, not only applicable to the two learners used to devise the attack but also to learning algorithms and even paradigms beyond.
6/7/2024
🏋️
Poisoning Web-Scale Training Datasets is Practical
Nicholas Carlini, Matthew Jagielski, Christopher A. Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, Florian Tram`er
0
0
Deep learning models are often trained on distributed, web-scale datasets crawled from the internet. In this paper, we introduce two new dataset poisoning attacks that intentionally introduce malicious examples to a model's performance. Our attacks are immediately practical and could, today, poison 10 popular datasets. Our first attack, split-view poisoning, exploits the mutable nature of internet content to ensure a dataset annotator's initial view of the dataset differs from the view downloaded by subsequent clients. By exploiting specific invalid trust assumptions, we show how we could have poisoned 0.01% of the LAION-400M or COYO-700M datasets for just $60 USD. Our second attack, frontrunning poisoning, targets web-scale datasets that periodically snapshot crowd-sourced content -- such as Wikipedia -- where an attacker only needs a time-limited window to inject malicious examples. In light of both attacks, we notify the maintainers of each affected dataset and recommended several low-overhead defenses.
5/7/2024