Accurate and Efficient Fine-Tuning of Quantized Large Language Models Through Optimal Balance

0
💬
Sign in to get full access
Overview
- The provided paper is a technical research paper on a new deep learning method.
- It presents a novel approach to parameter-efficient fine-tuning of large language models.
- The key ideas involve low-rank matrix factorization and quantization-aware training.
Plain English Explanation
The paper describes a new technique called Bayesian LoRA for fine-tuning large language models in a more efficient way. Large language models like GPT-3 are powerful but require a lot of computing power and memory to use.
The core idea is to use a low-rank matrix factorization approach to reduce the number of parameters that need to be trained when fine-tuning the model for a specific task. This makes the fine-tuning process much faster and requires less computing resources.
The paper also incorporates quantization-aware training, which further compresses the model by reducing the precision of the weights. This allows the fine-tuned model to be deployed on devices with limited memory and processing power, like mobile phones.
By combining these techniques, the researchers were able to achieve high performance on various language tasks while using a fraction of the parameters and computation required by standard fine-tuning approaches. This could enable the wider deployment of large language models in real-world applications.
Technical Explanation
The paper proposes a novel method called Bayesian LoRA for parameter-efficient fine-tuning of large language models. It builds on the LoRA technique, which uses low-rank matrix factorization to reduce the number of parameters that need to be fine-tuned.
The key idea is to decompose the weight matrices of the language model into a low-rank component and a residual component. During fine-tuning, only the low-rank component is updated, significantly reducing the number of trainable parameters. The residual component remains fixed, allowing the model to retain its original capabilities.
To further compress the fine-tuned model, the paper incorporates quantization-aware training. This reduces the precision of the weights, e.g., from 32-bit floating-point to 8-bit or even 2-bit, without significantly impacting model performance.
The researchers evaluated their approach on various language tasks and showed that it achieves comparable or better performance than standard fine-tuning, while using 10-100x fewer parameters. This makes the fine-tuned models much more efficient to deploy, especially on resource-constrained devices.
Critical Analysis
The paper presents a well-designed study that thoroughly evaluates the proposed Bayesian LoRA approach. The authors carefully compare it to other parameter-efficient fine-tuning methods, such as LQ-LoRA and Quanta, and demonstrate its superior performance.
One potential limitation of the approach is that it may not be as effective for tasks that require significant changes to the language model's structure or behavior. The low-rank factorization and quantization techniques are designed to preserve the model's core capabilities, which could limit its ability to adapt to more substantial changes.
Additionally, the paper does not explore the potential for further compression or acceleration beyond the quantization-aware training. There may be opportunities to combine Bayesian LoRA with other model compression techniques, such as Low-Rank Quantization-Aware Training, to achieve even more efficient model deployments.
Conclusion
The Bayesian LoRA method presented in this paper is a promising approach for parameter-efficient fine-tuning of large language models. By leveraging low-rank matrix factorization and quantization-aware training, the researchers were able to achieve high-performing fine-tuned models that are significantly more efficient in terms of parameter count and computational requirements.
This work has the potential to enable the wider deployment of large language models in real-world applications, especially on resource-constrained devices. The techniques described in the paper could be further extended and combined with other compression methods to push the boundaries of efficient model fine-tuning even further.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Accurate and Efficient Fine-Tuning of Quantized Large Language Models Through Optimal Balance
Ao Shen, Qiang Wang, Zhiquan Lai, Xionglve Li, Dongsheng Li
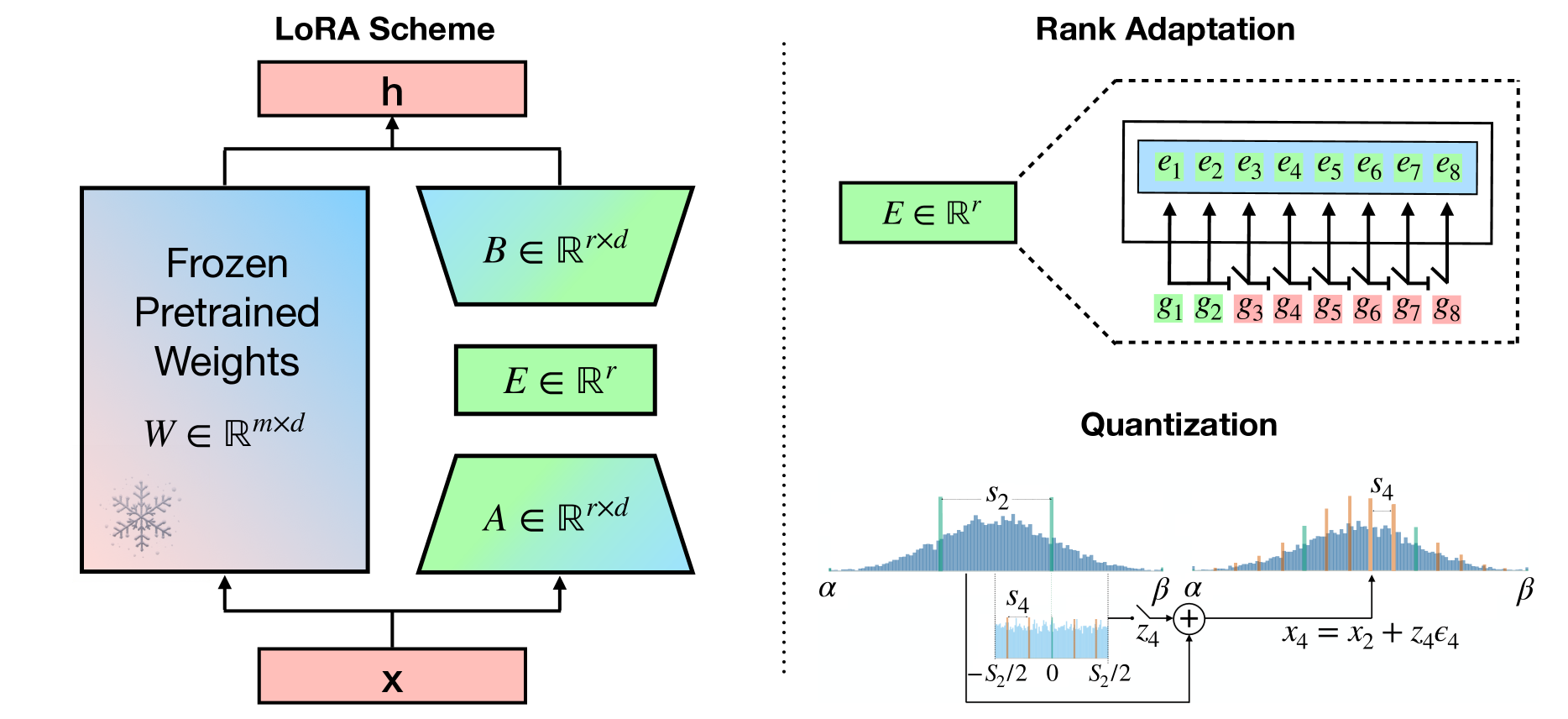
Large Language Models (LLMs) have demonstrated impressive performance across various domains. However, the enormous number of model parameters makes fine-tuning challenging, significantly limiting their application and deployment. Existing solutions combine parameter quantization with Low-Rank Adaptation (LoRA), greatly reducing memory usage but resulting in noticeable performance degradation. In this paper, we identify an imbalance in fine-tuning quantized pre-trained models: overly complex adapter inputs and outputs versus low effective trainability of the adaptation. We propose Quantized LLMs with Balanced-rank Adaptation (Q-BaRA), which simplifies the adapter inputs and outputs while increasing the adapter's rank to achieve a more suitable balance for fine-tuning quantized LLMs. Additionally, for scenarios where fine-tuned LLMs need to be deployed as low-precision inference models, we introduce Quantization-Aware Fine-tuning with Higher Rank Adaptation (QA-HiRA), which simplifies the adapter inputs and outputs to align with the pre-trained model's block-wise quantization while employing a single matrix to achieve a higher rank. Both Q-BaRA and QA-HiRA are easily implemented and offer the following optimizations: (i) Q-BaRA consistently achieves the highest accuracy compared to baselines and other variants, requiring the same number of trainable parameters and computational effort; (ii) QA-HiRA naturally merges adapter parameters into the block-wise quantized model after fine-tuning, achieving the highest accuracy compared to other methods. We apply our Q-BaRA and QA-HiRA to the LLaMA and LLaMA2 model families and validate their effectiveness across different fine-tuning datasets and downstream scenarios. Code will be made available at href{https://github.com/xiaocaigou/qbaraqahira}{https://github.com/xiaocaigou/qbaraqahira}
Read more7/25/2024
0
Bayesian-LoRA: LoRA based Parameter Efficient Fine-Tuning using Optimal Quantization levels and Rank Values trough Differentiable Bayesian Gates
Cristian Meo, Ksenia Sycheva, Anirudh Goyal, Justin Dauwels
It is a common practice in natural language processing to pre-train a single model on a general domain and then fine-tune it for downstream tasks. However, when it comes to Large Language Models, fine-tuning the entire model can be computationally expensive, resulting in very intensive energy consumption. As a result, several Parameter Efficient Fine-Tuning (PEFT) approaches were recently proposed. One of the most popular approaches is low-rank adaptation (LoRA), where the key insight is decomposing the update weights of the pre-trained model into two low-rank matrices. However, the proposed approaches either use the same rank value across all different weight matrices, which has been shown to be a sub-optimal choice, or do not use any quantization technique, one of the most important factors when it comes to a model's energy consumption. In this work, we propose Bayesian-LoRA which approaches low-rank adaptation and quantization from a Bayesian perspective by employing a prior distribution on both quantization levels and rank values. As a result, B-LoRA is able to fine-tune a pre-trained model on a specific downstream task, finding the optimal rank values and quantization levels for every low-rank matrix. We validate the proposed model by fine-tuning a pre-trained DeBERTaV3 on the GLUE benchmark. Moreover, we compare it to relevant baselines and present both qualitative and quantitative results, showing how the proposed approach is able to learn optimal-rank quantized matrices. B-LoRA performs on par with or better than the baselines while reducing the total number of bit operations by roughly 70% compared to the baseline methods.
Read more7/10/2024

0
ApiQ: Finetuning of 2-Bit Quantized Large Language Model
Baohao Liao, Christian Herold, Shahram Khadivi, Christof Monz
Memory-efficient finetuning of large language models (LLMs) has recently attracted huge attention with the increasing size of LLMs, primarily due to the constraints posed by GPU memory limitations and the effectiveness of these methods compared to full finetuning. Despite the advancements, current strategies for memory-efficient finetuning, such as QLoRA, exhibit inconsistent performance across diverse bit-width quantizations and multifaceted tasks. This inconsistency largely stems from the detrimental impact of the quantization process on preserved knowledge, leading to catastrophic forgetting and undermining the utilization of pretrained models for finetuning purposes. In this work, we introduce a novel quantization framework, ApiQ, designed to restore the lost information from quantization by concurrently initializing the LoRA components and quantizing the weights of LLMs. This approach ensures the maintenance of the original LLM's activation precision while mitigating the error propagation from shallower into deeper layers. Through comprehensive evaluations conducted on a spectrum of language tasks with various LLMs, ApiQ demonstrably minimizes activation error during quantization. Consequently, it consistently achieves superior finetuning results across various bit-widths.
Read more6/24/2024
💬
12
LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning
Han Guo, Philip Greengard, Eric P. Xing, Yoon Kim
We propose a simple approach for memory-efficient adaptation of pretrained language models. Our approach uses an iterative algorithm to decompose each pretrained matrix into a high-precision low-rank component and a memory-efficient quantized component. During finetuning, the quantized component remains fixed and only the low-rank component is updated. We present an integer linear programming formulation of the quantization component which enables dynamic configuration of quantization parameters (e.g., bit-width, block size) for each matrix given an overall target memory budget. We further explore a data-aware version of the algorithm which uses an approximation of the Fisher information matrix to weight the reconstruction objective during matrix decomposition. Experiments on finetuning RoBERTa and LLaMA-2 (7B and 70B) demonstrate that our low-rank plus quantized matrix decomposition approach (LQ-LoRA) outperforms strong QLoRA and GPTQ-LoRA baselines and enables aggressive quantization to sub-3 bits with only minor performance degradations. When finetuned on a language modeling calibration dataset, LQ-LoRA can also be used for model compression; in this setting our 2.75-bit LLaMA-2-70B model (which has 2.85 bits on average when including the low-rank components and requires 27GB of GPU memory) performs respectably compared to the 16-bit baseline.
Read more8/28/2024