LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning

12
💬
Sign in to get full access
Overview
- Proposes a memory-efficient approach for adapting pretrained language models
- Uses an iterative algorithm to decompose each pretrained matrix into a high-precision low-rank component and a memory-efficient quantized component
- Only the low-rank component is updated during finetuning, while the quantized component remains fixed
- Introduces an integer linear programming formulation for dynamic configuration of quantization parameters
- Explores a data-aware version that uses the Fisher information matrix to weight the reconstruction objective
- Demonstrates strong performance on finetuning RoBERTa and LLaMA-2 models with aggressive quantization
Plain English Explanation
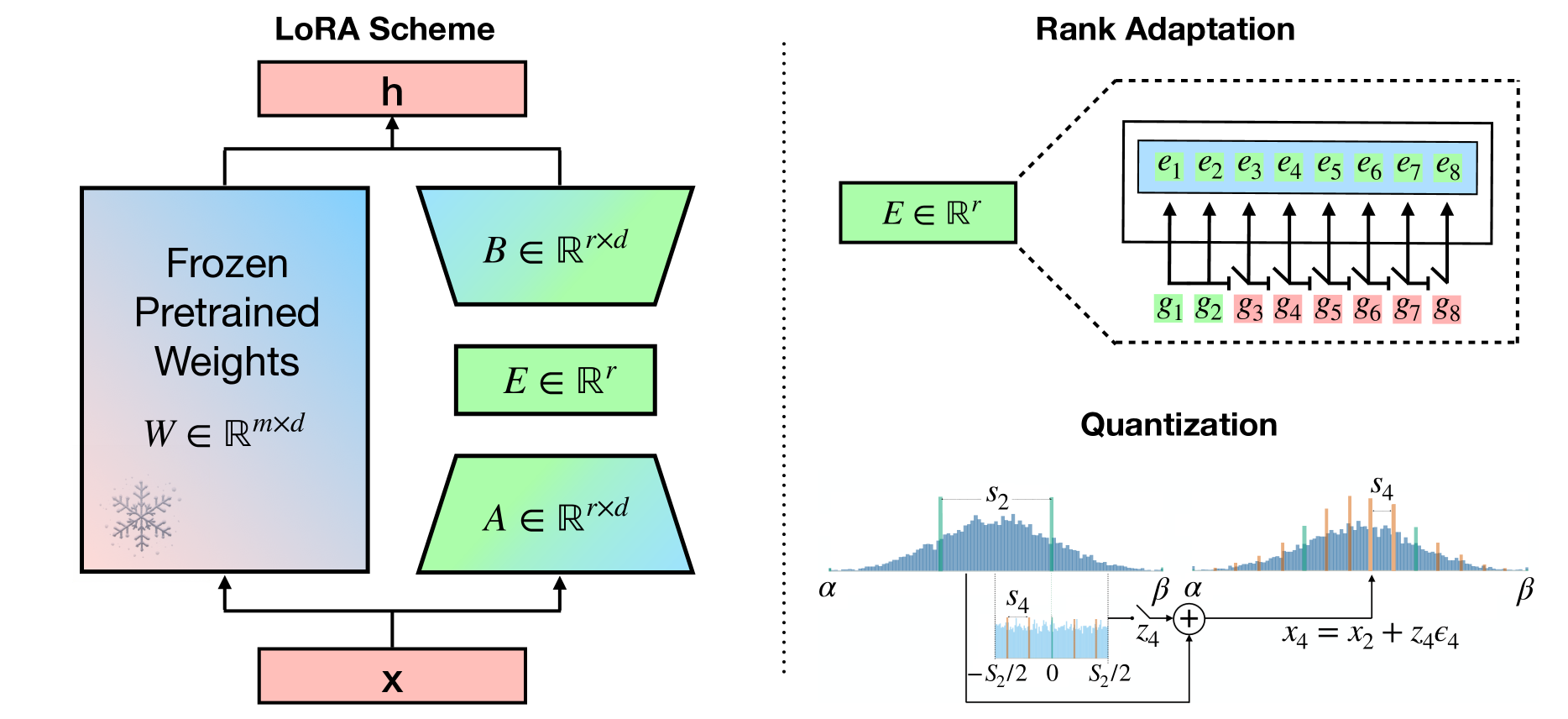
The paper introduces a novel technique called LQ-LoRA for efficiently adapting large pretrained language models to specific tasks. The key idea is to decompose each matrix in the pretrained model into two components: a high-precision low-rank part and a memory-efficient quantized part.
During finetuning, only the low-rank component is updated, while the quantized part remains fixed. This allows the model to be adapted with a much smaller memory footprint compared to fully finetuning the entire model. The authors also develop an optimization-based approach to dynamically configure the quantization parameters (e.g., bit-width, block size) for each matrix to meet a given memory budget.
Additionally, the authors explore a "data-aware" version of their algorithm that uses an approximation of the Fisher information matrix to better preserve the most important information during the matrix decomposition. This helps maintain model performance even with aggressive quantization down to 2-3 bits.
The experimental results show that LQ-LoRA outperforms other quantization-based finetuning approaches like QLoRA and GPTQ-LoRA. It also enables significant model compression, with a 2.75-bit version of the LLaMA-2-70B model performing respectably compared to the full 16-bit version.
Technical Explanation
The paper proposes a memory-efficient approach for adapting pretrained language models called LQ-LoRA. The core idea is to decompose each pretrained matrix into a high-precision low-rank component and a memory-efficient quantized component. During finetuning, only the low-rank component is updated, while the quantized component remains fixed.
The authors introduce an integer linear programming formulation to dynamically configure the quantization parameters (bit-width, block size) for each matrix, given a target memory budget. This allows the model to be aggressively quantized while preserving performance.
Additionally, the authors explore a "data-aware" version of their algorithm that uses an approximation of the Fisher information matrix to weight the reconstruction objective during the matrix decomposition. This helps maintain the most important information from the original pretrained model.
Experiments on finetuning RoBERTa and LLaMA-2 (7B and 70B) models demonstrate that LQ-LoRA outperforms strong baselines like QLoRA and GPTQ-LoRA. The authors show that LQ-LoRA can achieve aggressive quantization down to sub-3 bits with only minor performance degradation.
When finetuned on a language modeling calibration dataset, LQ-LoRA can also be used for model compression. The authors demonstrate a 2.75-bit version of the LLaMA-2-70B model that performs respectably compared to the full 16-bit baseline, while requiring significantly less GPU memory.
Critical Analysis
The paper presents a compelling approach for memory-efficient adaptation of large language models. The use of low-rank plus quantized matrix decomposition is a clever way to balance model accuracy and memory footprint during finetuning.
One potential limitation is the computational overhead of the integer linear programming formulation used to configure the quantization parameters. This may limit the practical applicability of the method, especially for resource-constrained deployment scenarios. The authors acknowledge this and suggest exploring alternative optimization strategies in future work.
Additionally, the paper focuses primarily on language modeling tasks and could benefit from evaluating the LQ-LoRA approach on a wider range of downstream applications to better understand its generalizability.
Another area for further research could be exploring the tradeoffs between the low-rank and quantized components of the decomposition. For example, investigating methods to dynamically adjust the rank or quantization levels during finetuning could lead to additional performance and efficiency gains.
Overall, the LQ-LoRA technique is a promising step towards making large language models more memory-efficient and accessible, especially for edge and mobile applications.
Conclusion
The paper presents a novel memory-efficient approach called LQ-LoRA for adapting pretrained language models to specific tasks. By decomposing each pretrained matrix into a low-rank component and a quantized component, the method can achieve aggressive model compression while maintaining performance.
The authors' experiments demonstrate the effectiveness of LQ-LoRA on adapting large models like RoBERTa and LLaMA-2, outperforming other quantization-based approaches. The ability to achieve sub-3-bit quantization with minimal accuracy degradation is particularly noteworthy and has significant implications for deploying large language models on resource-constrained devices.
Overall, the LQ-LoRA technique represents an important advancement in the field of efficient model adaptation and compression, paving the way for more accessible and practical large language models in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
12
LQ-LoRA: Low-rank Plus Quantized Matrix Decomposition for Efficient Language Model Finetuning
Han Guo, Philip Greengard, Eric P. Xing, Yoon Kim
We propose a simple approach for memory-efficient adaptation of pretrained language models. Our approach uses an iterative algorithm to decompose each pretrained matrix into a high-precision low-rank component and a memory-efficient quantized component. During finetuning, the quantized component remains fixed and only the low-rank component is updated. We present an integer linear programming formulation of the quantization component which enables dynamic configuration of quantization parameters (e.g., bit-width, block size) for each matrix given an overall target memory budget. We further explore a data-aware version of the algorithm which uses an approximation of the Fisher information matrix to weight the reconstruction objective during matrix decomposition. Experiments on finetuning RoBERTa and LLaMA-2 (7B and 70B) demonstrate that our low-rank plus quantized matrix decomposition approach (LQ-LoRA) outperforms strong QLoRA and GPTQ-LoRA baselines and enables aggressive quantization to sub-3 bits with only minor performance degradations. When finetuned on a language modeling calibration dataset, LQ-LoRA can also be used for model compression; in this setting our 2.75-bit LLaMA-2-70B model (which has 2.85 bits on average when including the low-rank components and requires 27GB of GPU memory) performs respectably compared to the 16-bit baseline.
Read more8/28/2024
0
Bayesian-LoRA: LoRA based Parameter Efficient Fine-Tuning using Optimal Quantization levels and Rank Values trough Differentiable Bayesian Gates
Cristian Meo, Ksenia Sycheva, Anirudh Goyal, Justin Dauwels
It is a common practice in natural language processing to pre-train a single model on a general domain and then fine-tune it for downstream tasks. However, when it comes to Large Language Models, fine-tuning the entire model can be computationally expensive, resulting in very intensive energy consumption. As a result, several Parameter Efficient Fine-Tuning (PEFT) approaches were recently proposed. One of the most popular approaches is low-rank adaptation (LoRA), where the key insight is decomposing the update weights of the pre-trained model into two low-rank matrices. However, the proposed approaches either use the same rank value across all different weight matrices, which has been shown to be a sub-optimal choice, or do not use any quantization technique, one of the most important factors when it comes to a model's energy consumption. In this work, we propose Bayesian-LoRA which approaches low-rank adaptation and quantization from a Bayesian perspective by employing a prior distribution on both quantization levels and rank values. As a result, B-LoRA is able to fine-tune a pre-trained model on a specific downstream task, finding the optimal rank values and quantization levels for every low-rank matrix. We validate the proposed model by fine-tuning a pre-trained DeBERTaV3 on the GLUE benchmark. Moreover, we compare it to relevant baselines and present both qualitative and quantitative results, showing how the proposed approach is able to learn optimal-rank quantized matrices. B-LoRA performs on par with or better than the baselines while reducing the total number of bit operations by roughly 70% compared to the baseline methods.
Read more7/10/2024

0
Low-Rank Quantization-Aware Training for LLMs
Yelysei Bondarenko, Riccardo Del Chiaro, Markus Nagel
Large language models (LLMs) are omnipresent, however their practical deployment is challenging due to their ever increasing computational and memory demands. Quantization is one of the most effective ways to make them more compute and memory efficient. Quantization-aware training (QAT) methods, generally produce the best quantized performance, however it comes at the cost of potentially long training time and excessive memory usage, making it impractical when applying for LLMs. Inspired by parameter-efficient fine-tuning (PEFT) and low-rank adaptation (LoRA) literature, we propose LR-QAT -- a lightweight and memory-efficient QAT algorithm for LLMs. LR-QAT employs several components to save memory without sacrificing predictive performance: (a) low-rank auxiliary weights that are aware of the quantization grid; (b) a downcasting operator using fixed-point or double-packed integers and (c) checkpointing. Unlike most related work, our method (i) is inference-efficient, leading to no additional overhead compared to traditional PTQ; (ii) can be seen as a general extended pretraining framework, meaning that the resulting model can still be utilized for any downstream task afterwards; (iii) can be applied across a wide range of quantization settings, such as different choices quantization granularity, activation quantization, and seamlessly combined with many PTQ techniques. We apply LR-QAT to LLaMA-1/2/3 and Mistral model families and validate its effectiveness on several downstream tasks. Our method outperforms common post-training quantization (PTQ) approaches and reaches the same model performance as full-model QAT at the fraction of its memory usage. Specifically, we can train a 7B LLM on a single consumer grade GPU with 24GB of memory. Our source code is available at https://github.com/qualcomm-ai-research/LR-QAT
Read more9/4/2024
💬
0
Accurate and Efficient Fine-Tuning of Quantized Large Language Models Through Optimal Balance
Ao Shen, Qiang Wang, Zhiquan Lai, Xionglve Li, Dongsheng Li
Large Language Models (LLMs) have demonstrated impressive performance across various domains. However, the enormous number of model parameters makes fine-tuning challenging, significantly limiting their application and deployment. Existing solutions combine parameter quantization with Low-Rank Adaptation (LoRA), greatly reducing memory usage but resulting in noticeable performance degradation. In this paper, we identify an imbalance in fine-tuning quantized pre-trained models: overly complex adapter inputs and outputs versus low effective trainability of the adaptation. We propose Quantized LLMs with Balanced-rank Adaptation (Q-BaRA), which simplifies the adapter inputs and outputs while increasing the adapter's rank to achieve a more suitable balance for fine-tuning quantized LLMs. Additionally, for scenarios where fine-tuned LLMs need to be deployed as low-precision inference models, we introduce Quantization-Aware Fine-tuning with Higher Rank Adaptation (QA-HiRA), which simplifies the adapter inputs and outputs to align with the pre-trained model's block-wise quantization while employing a single matrix to achieve a higher rank. Both Q-BaRA and QA-HiRA are easily implemented and offer the following optimizations: (i) Q-BaRA consistently achieves the highest accuracy compared to baselines and other variants, requiring the same number of trainable parameters and computational effort; (ii) QA-HiRA naturally merges adapter parameters into the block-wise quantized model after fine-tuning, achieving the highest accuracy compared to other methods. We apply our Q-BaRA and QA-HiRA to the LLaMA and LLaMA2 model families and validate their effectiveness across different fine-tuning datasets and downstream scenarios. Code will be made available at href{https://github.com/xiaocaigou/qbaraqahira}{https://github.com/xiaocaigou/qbaraqahira}
Read more7/25/2024