Accurate Explanation Model for Image Classifiers using Class Association Embedding

0
Sign in to get full access
Overview
- Introduces a new method called "Class Association Embedding" for explaining the decisions of image classifiers
- Aims to generate accurate and interpretable explanations for the predictions made by image classification models
- Leverages class-associated codes to capture the semantic relationships between image classes and generate counterfactual explanations
Plain English Explanation
The provided paper presents a novel approach called "Class Association Embedding" to explain the decisions made by image classification models. Image classification models are used to automatically identify the contents of images, such as recognizing that an image shows a dog or a cat. However, these models can be complex and difficult to understand, making it hard to know why they make the predictions they do.
The researchers behind this paper wanted to develop a way to generate accurate and interpretable explanations for the predictions made by image classification models. Their approach, Class Association Embedding, leverages the semantic relationships between different image classes to capture what the model has learned. This allows them to not only explain the model's predictions, but also generate "counterfactual" explanations - showing what would need to change in an image for the model to make a different prediction.
By using this class association embedding technique, the researchers were able to produce explanations that were more accurate and faithful to the inner workings of the image classification model, compared to other existing explanation methods. This can help users better understand how these powerful AI models arrive at their conclusions, which is important for building trust and ensuring the models are behaving as intended.
Technical Explanation
The key innovation in this paper is the introduction of "Class Association Embedding" (CAE), a novel technique for generating explanations for image classification models. The core idea is to leverage the semantic relationships between the different image classes that the model has been trained on.
The researchers first train a secondary "explanation" model in parallel with the main image classification model. This explanation model learns to associate each image class with a unique "code" vector that captures the semantic meaning and relationships between the classes. For example, the code for "dog" may be closer to "cat" than "airplane" in the embedding space, reflecting their real-world similarities and differences.
During inference, the researchers use these class-associated codes to generate counterfactual explanations. They identify the top features that the classification model used to make its prediction, and then show how manipulating those features could change the predicted class. For instance, they might highlight that adding more "dog-like" features to an image would cause the model to classify it as a dog instead of a cat.
Through extensive experiments, the authors demonstrate that their CAE approach produces more accurate and interpretable explanations compared to prior explanation methods. The class-associated codes allow the model to reason about the semantic relationships between classes, leading to more faithful and informative explanations of the classifier's decision-making process.
Critical Analysis
The paper makes a strong contribution by introducing a novel and effective approach for generating accurate and interpretable explanations for image classification models. By leveraging the semantic structure of the class taxonomy, the Class Association Embedding technique is able to produce more insightful and faithful explanations than prior methods.
However, one potential limitation is the overhead of training the secondary explanation model in parallel with the main classifier. This may increase the computational and memory requirements of the overall system, which could be a concern for deployment on resource-constrained devices. The authors do not provide a thorough analysis of the additional training and inference costs introduced by their approach.
Additionally, the paper focuses primarily on the technical details and evaluation of the CAE method, without much discussion of the broader implications and societal impact of improving model explanations. Advancing ante-hoc explainable models through generative techniques may provide additional context on the importance of explainable AI systems and the challenges involved.
Overall, the Class Association Embedding approach represents a promising step forward in the field of explainable artificial intelligence. Future research could explore ways to reduce the computational overhead, as well as investigate how these explanations might be used to test and validate model behavior in real-world applications.
Conclusion
The paper presents a novel "Class Association Embedding" technique for generating accurate and interpretable explanations of image classification models. By leveraging the semantic relationships between image classes, the approach is able to produce counterfactual explanations that better reflect the inner workings of the classifier.
This is an important development in the field of explainable AI, as it helps users better understand and trust the decisions made by powerful image classification models. The ability to generate faithful explanations and identify potential failure modes can be crucial for deploying these models in high-stakes applications, such as medical diagnosis or autonomous vehicle systems.
Overall, the Class Association Embedding method represents a significant step forward in making image classification models more transparent and accountable. As AI systems become increasingly integrated into our daily lives, continued research into explainable AI will be essential for ensuring these technologies are reliable, equitable, and aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Accurate Explanation Model for Image Classifiers using Class Association Embedding
Ruitao Xie, Jingbang Chen, Limai Jiang, Rui Xiao, Yi Pan, Yunpeng Cai
Image classification is a primary task in data analysis where explainable models are crucially demanded in various applications. Although amounts of methods have been proposed to obtain explainable knowledge from the black-box classifiers, these approaches lack the efficiency of extracting global knowledge regarding the classification task, thus is vulnerable to local traps and often leads to poor accuracy. In this study, we propose a generative explanation model that combines the advantages of global and local knowledge for explaining image classifiers. We develop a representation learning method called class association embedding (CAE), which encodes each sample into a pair of separated class-associated and individual codes. Recombining the individual code of a given sample with altered class-associated code leads to a synthetic real-looking sample with preserved individual characters but modified class-associated features and possibly flipped class assignments. A building-block coherency feature extraction algorithm is proposed that efficiently separates class-associated features from individual ones. The extracted feature space forms a low-dimensional manifold that visualizes the classification decision patterns. Explanation on each individual sample can be then achieved in a counter-factual generation manner which continuously modifies the sample in one direction, by shifting its class-associated code along a guided path, until its classification outcome is changed. We compare our method with state-of-the-art ones on explaining image classification tasks in the form of saliency maps, demonstrating that our method achieves higher accuracies. The code is available at https://github.com/xrt11/XAI-CODE.
Read more8/26/2024
🗣️
0
Causality-Aware Local Interpretable Model-Agnostic Explanations
Martina Cinquini, Riccardo Guidotti
A main drawback of eXplainable Artificial Intelligence (XAI) approaches is the feature independence assumption, hindering the study of potential variable dependencies. This leads to approximating black box behaviors by analyzing the effects on randomly generated feature values that may rarely occur in the original samples. This paper addresses this issue by integrating causal knowledge in an XAI method to enhance transparency and enable users to assess the quality of the generated explanations. Specifically, we propose a novel extension to a widely used local and model-agnostic explainer, which encodes explicit causal relationships within the data surrounding the instance being explained. Extensive experiments show that our approach overcomes the original method in terms of faithfully replicating the black-box model's mechanism and the consistency and reliability of the generated explanations.
Read more4/16/2024

0
CNN-based explanation ensembling for dataset, representation and explanations evaluation
Weronika Hryniewska-Guzik, Luca Longo, Przemys{l}aw Biecek
Explainable Artificial Intelligence has gained significant attention due to the widespread use of complex deep learning models in high-stake domains such as medicine, finance, and autonomous cars. However, different explanations often present different aspects of the model's behavior. In this research manuscript, we explore the potential of ensembling explanations generated by deep classification models using convolutional model. Through experimentation and analysis, we aim to investigate the implications of combining explanations to uncover a more coherent and reliable patterns of the model's behavior, leading to the possibility of evaluating the representation learned by the model. With our method, we can uncover problems of under-representation of images in a certain class. Moreover, we discuss other side benefits like features' reduction by replacing the original image with its explanations resulting in the removal of some sensitive information. Through the use of carefully selected evaluation metrics from the Quantus library, we demonstrated the method's superior performance in terms of Localisation and Faithfulness, compared to individual explanations.
Read more4/17/2024
0
Explaining Explainability: Understanding Concept Activation Vectors
Angus Nicolson, Lisa Schut, J. Alison Noble, Yarin Gal
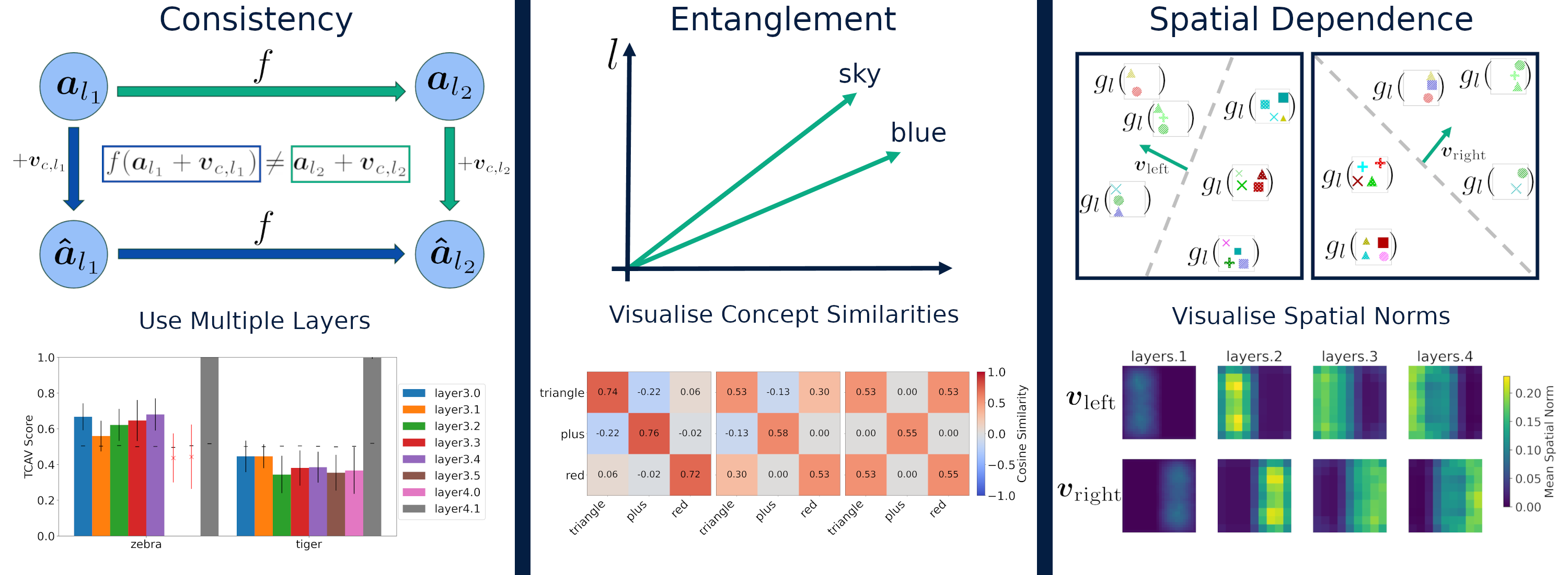
Recent interpretability methods propose using concept-based explanations to translate the internal representations of deep learning models into a language that humans are familiar with: concepts. This requires understanding which concepts are present in the representation space of a neural network. One popular method for finding concepts is Concept Activation Vectors (CAVs), which are learnt using a probe dataset of concept exemplars. In this work, we investigate three properties of CAVs. CAVs may be: (1) inconsistent between layers, (2) entangled with different concepts, and (3) spatially dependent. Each property provides both challenges and opportunities in interpreting models. We introduce tools designed to detect the presence of these properties, provide insight into how they affect the derived explanations, and provide recommendations to minimise their impact. Understanding these properties can be used to our advantage. For example, we introduce spatially dependent CAVs to test if a model is translation invariant with respect to a specific concept and class. Our experiments are performed on ImageNet and a new synthetic dataset, Elements. Elements is designed to capture a known ground truth relationship between concepts and classes. We release this dataset to facilitate further research in understanding and evaluating interpretability methods.
Read more4/8/2024