Explaining Explainability: Understanding Concept Activation Vectors
2404.03713
0
0
Abstract
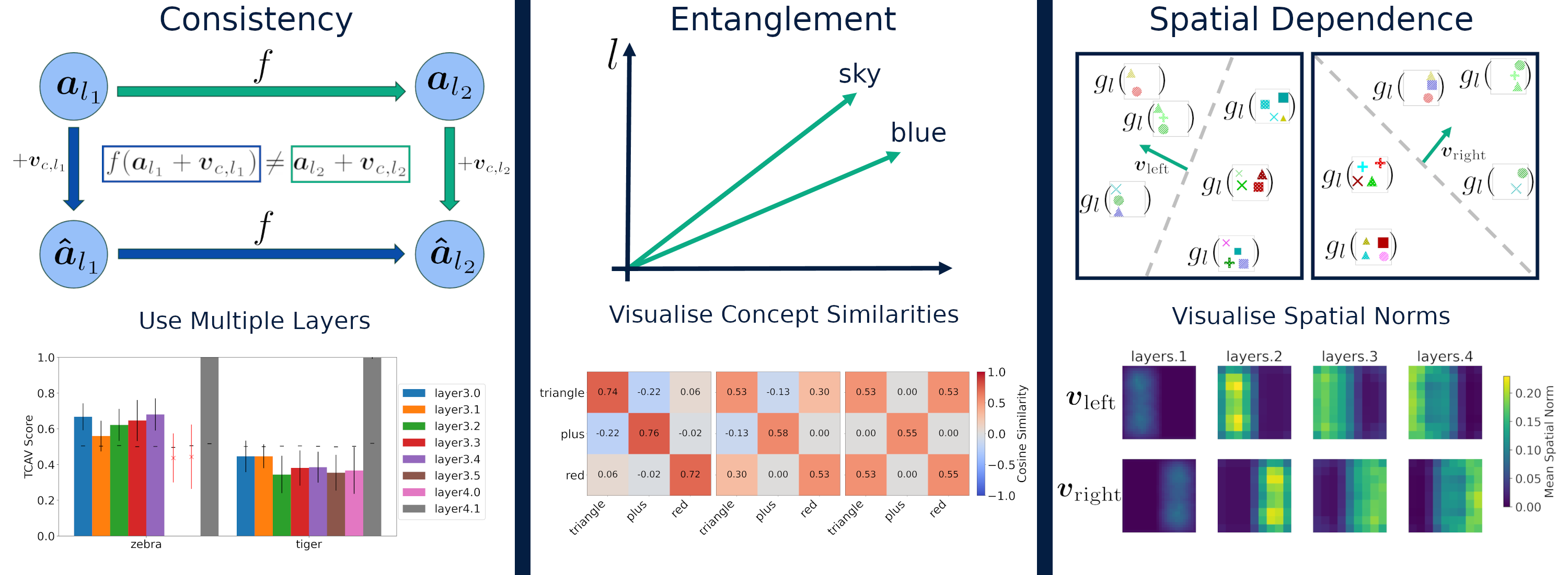
Recent interpretability methods propose using concept-based explanations to translate the internal representations of deep learning models into a language that humans are familiar with: concepts. This requires understanding which concepts are present in the representation space of a neural network. One popular method for finding concepts is Concept Activation Vectors (CAVs), which are learnt using a probe dataset of concept exemplars. In this work, we investigate three properties of CAVs. CAVs may be: (1) inconsistent between layers, (2) entangled with different concepts, and (3) spatially dependent. Each property provides both challenges and opportunities in interpreting models. We introduce tools designed to detect the presence of these properties, provide insight into how they affect the derived explanations, and provide recommendations to minimise their impact. Understanding these properties can be used to our advantage. For example, we introduce spatially dependent CAVs to test if a model is translation invariant with respect to a specific concept and class. Our experiments are performed on ImageNet and a new synthetic dataset, Elements. Elements is designed to capture a known ground truth relationship between concepts and classes. We release this dataset to facilitate further research in understanding and evaluating interpretability methods.
Create account to get full access
Overview
- This paper explores the concept of Concept Activation Vectors (CAVs), which are used to help explain the inner workings of machine learning models.
- CAVs aim to identify the specific concepts that a model has learned and uses to make predictions.
- The paper investigates several hypotheses about how CAVs can be used to better understand and explain model behavior.
Plain English Explanation
Machine learning models, like those used for image recognition or language understanding, can sometimes be "black boxes" - it's not always clear how they arrive at their predictions. Concept Activation Vectors (CAVs) are a technique that aims to open up these black boxes by identifying the specific concepts the model has learned and is using to make its decisions.
The idea is that a model doesn't just look at an image or text in a raw, unstructured way. Instead, it has learned to recognize higher-level "concepts" - things like specific objects, textures, emotions, or ideas. By analyzing which concepts a model activates the most when making a prediction, we can get a better sense of its internal reasoning.
This paper dives deeper into how CAVs work and proposes several hypotheses about how they can be used to improve model interpretability and explainability. For example, the authors suggest that CAVs could help identify biases in a model, or reveal which concepts a model is still struggling to learn. Overall, the goal is to make these powerful machine learning systems more transparent and understandable to the humans who use them.
Technical Explanation
The paper first provides background on the concept of Concept Activation Vectors (CAVs). CAVs are a way to identify the specific concepts that a machine learning model has learned to recognize and rely on when making predictions.
The key idea is to train a separate "concept model" that can detect the presence of particular concepts in an input. This concept model is then used to generate a vector that represents how strongly the main model activates each of these concepts. By analyzing this concept activation vector, researchers can gain insights into the model's internal reasoning.
The paper then proposes several hypotheses about how CAVs can be used to better understand and explain model behavior:
-
Concept Purity: The paper hypothesizes that models with higher "concept purity" - where a single concept strongly dominates the CAV - will be more interpretable and explainable.
-
Concept Uncertainty: The authors suggest that considering the uncertainty in CAV estimates could lead to more robust and reliable explanations.
-
Concept Generalization: The paper hypothesizes that models which learn more generalizable concepts will be more transparent and trustworthy.
-
Concept Compositionality: The authors propose that models which learn to combine concepts in more compositional ways will be more interpretable.
The paper then describes experiments designed to test these hypotheses, involving both neural network and symbolic AI models. The results provide evidence supporting some of the hypotheses, while also revealing areas for further research.
Critical Analysis
One key limitation of the CAV approach highlighted in the paper is the potential for "concept-washing" - where models learn to activate certain concepts in a superficial way, without truly understanding their meaning. The authors note that further research is needed to ensure CAVs are genuinely reflecting deep conceptual knowledge, rather than just surface-level associations.
Additionally, the paper acknowledges that the interpretability benefits of CAVs may be more pronounced for certain types of models or tasks. Applying these techniques to more complex, multi-modal models could present additional challenges that require further investigation.
While the paper provides a strong foundation for understanding CAVs, it also raises several thought-provoking questions. For example, how can we ensure the concept models themselves are unbiased and accurate? And what are the ethical implications of using CAVs to interpret high-stakes decision-making models?
Overall, this research represents an important step forward in making machine learning more transparent and accountable. By continuing to explore techniques like CAVs, the field of explainable AI can work towards building systems that are not only powerful, but also trustworthy and aligned with human values.
Conclusion
This paper offers a detailed exploration of Concept Activation Vectors (CAVs), a technique for opening up the "black box" of machine learning models and gaining a better understanding of their internal reasoning. The authors propose several hypotheses about how CAVs can be used to improve model interpretability and explainability, and present experimental results that provide evidence for some of these ideas.
While the CAV approach has promise, the paper also highlights important limitations and areas for further research. Ensuring CAVs genuinely reflect deep conceptual understanding, rather than surface-level associations, is a key challenge. Applying these techniques to more complex models and understanding their ethical implications will also be crucial as this field continues to evolve.
Overall, this work represents an important contribution to the growing field of explainable AI, which aims to make powerful machine learning systems more transparent and accountable. By continuing to develop techniques like CAVs, researchers can work towards building AI models that are not only highly capable, but also trustworthy and aligned with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Knowledge graphs for empirical concept retrieval
Lenka Tv{e}tkov'a, Teresa Karen Scheidt, Maria Mandrup Fogh, Ellen Marie Gaunby J{o}rgensen, Finn {AA}rup Nielsen, Lars Kai Hansen
0
0
Concept-based explainable AI is promising as a tool to improve the understanding of complex models at the premises of a given user, viz. as a tool for personalized explainability. An important class of concept-based explainability methods is constructed with empirically defined concepts, indirectly defined through a set of positive and negative examples, as in the TCAV approach (Kim et al., 2018). While it is appealing to the user to avoid formal definitions of concepts and their operationalization, it can be challenging to establish relevant concept datasets. Here, we address this challenge using general knowledge graphs (such as, e.g., Wikidata or WordNet) for comprehensive concept definition and present a workflow for user-driven data collection in both text and image domains. The concepts derived from knowledge graphs are defined interactively, providing an opportunity for personalization and ensuring that the concepts reflect the user's intentions. We test the retrieved concept datasets on two concept-based explainability methods, namely concept activation vectors (CAVs) and concept activation regions (CARs) (Crabbe and van der Schaar, 2022). We show that CAVs and CARs based on these empirical concept datasets provide robust and accurate explanations. Importantly, we also find good alignment between the models' representations of concepts and the structure of knowledge graphs, i.e., human representations. This supports our conclusion that knowledge graph-based concepts are relevant for XAI.
4/11/2024
From Neural Activations to Concepts: A Survey on Explaining Concepts in Neural Networks
Jae Hee Lee, Sergio Lanza, Stefan Wermter
0
0
In this paper, we review recent approaches for explaining concepts in neural networks. Concepts can act as a natural link between learning and reasoning: once the concepts are identified that a neural learning system uses, one can integrate those concepts with a reasoning system for inference or use a reasoning system to act upon them to improve or enhance the learning system. On the other hand, knowledge can not only be extracted from neural networks but concept knowledge can also be inserted into neural network architectures. Since integrating learning and reasoning is at the core of neuro-symbolic AI, the insights gained from this survey can serve as an important step towards realizing neuro-symbolic AI based on explainable concepts.
5/6/2024

On the Value of Labeled Data and Symbolic Methods for Hidden Neuron Activation Analysis
Abhilekha Dalal, Rushrukh Rayan, Adrita Barua, Eugene Y. Vasserman, Md Kamruzzaman Sarker, Pascal Hitzler
0
0
A major challenge in Explainable AI is in correctly interpreting activations of hidden neurons: accurate interpretations would help answer the question of what a deep learning system internally detects as relevant in the input, demystifying the otherwise black-box nature of deep learning systems. The state of the art indicates that hidden node activations can, in some cases, be interpretable in a way that makes sense to humans, but systematic automated methods that would be able to hypothesize and verify interpretations of hidden neuron activations are underexplored. This is particularly the case for approaches that can both draw explanations from substantial background knowledge, and that are based on inherently explainable (symbolic) methods. In this paper, we introduce a novel model-agnostic post-hoc Explainable AI method demonstrating that it provides meaningful interpretations. Our approach is based on using a Wikipedia-derived concept hierarchy with approximately 2 million classes as background knowledge, and utilizes OWL-reasoning-based Concept Induction for explanation generation. Additionally, we explore and compare the capabilities of off-the-shelf pre-trained multimodal-based explainable methods. Our results indicate that our approach can automatically attach meaningful class expressions as explanations to individual neurons in the dense layer of a Convolutional Neural Network. Evaluation through statistical analysis and degree of concept activation in the hidden layer show that our method provides a competitive edge in both quantitative and qualitative aspects compared to prior work.
4/23/2024
🧠
Disentangled Explanations of Neural Network Predictions by Finding Relevant Subspaces
Pattarawat Chormai, Jan Herrmann, Klaus-Robert Muller, Gr'egoire Montavon
0
0
Explainable AI aims to overcome the black-box nature of complex ML models like neural networks by generating explanations for their predictions. Explanations often take the form of a heatmap identifying input features (e.g. pixels) that are relevant to the model's decision. These explanations, however, entangle the potentially multiple factors that enter into the overall complex decision strategy. We propose to disentangle explanations by extracting at some intermediate layer of a neural network, subspaces that capture the multiple and distinct activation patterns (e.g. visual concepts) that are relevant to the prediction. To automatically extract these subspaces, we propose two new analyses, extending principles found in PCA or ICA to explanations. These novel analyses, which we call principal relevant component analysis (PRCA) and disentangled relevant subspace analysis (DRSA), maximize relevance instead of e.g. variance or kurtosis. This allows for a much stronger focus of the analysis on what the ML model actually uses for predicting, ignoring activations or concepts to which the model is invariant. Our approach is general enough to work alongside common attribution techniques such as Shapley Value, Integrated Gradients, or LRP. Our proposed methods show to be practically useful and compare favorably to the state of the art as demonstrated on benchmarks and three use cases.
4/16/2024