Achieving Peak Performance for Large Language Models: A Systematic Review

0

Sign in to get full access
Overview
- This paper provides a systematic review of techniques to achieve peak performance for large language models (LLMs).
- Key topics covered include distributed training, GPU acceleration, optimization of LLM frameworks, and inference optimizations.
- The review aims to identify the state-of-the-art in LLM acceleration and optimization to help drive further advances in this rapidly evolving field.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can understand and generate human-like text. These models are incredibly powerful, but they also require a lot of computational resources to train and run efficiently.
This paper explores different techniques that researchers have developed to "supercharge" LLMs and help them run at their peak performance. Some of the key approaches include:
- Distributed Training: Breaking up the training of an LLM across multiple computers or GPUs to speed up the process.
- GPU Acceleration: Leveraging the specialized hardware in graphics processing units (GPUs) to run LLM computations much faster than on regular CPUs.
- LLM Framework Optimization: Improving the software libraries and frameworks used to build and run LLMs to make them more efficient.
- Inference Optimizations: Techniques to speed up the process of using a trained LLM to generate new text, which is a crucial part of deploying these models in real-world applications.
By exploring the state-of-the-art in these different areas, the paper aims to help researchers and engineers find new ways to unlock the full potential of large language models and enable their widespread adoption.
Technical Explanation
Distributed Training
Training large language models requires immense computational power, often exceeding what can be provided by a single machine. Distributed training techniques address this challenge by splitting the training process across multiple devices, such as GPUs or TPUs, allowing the workload to be parallelized. This includes approaches like data parallelism, model parallelism, and hybrid parallelism.
GPU Acceleration
Graphics processing units (GPUs) are particularly well-suited for the matrix operations and parallel computations required by LLMs. By offloading the computationally intensive parts of the LLM training and inference to GPUs, significant speedups can be achieved compared to running on traditional CPUs.
LLM Frameworks
The software frameworks used to build and run LLMs, such as PyTorch, TensorFlow, and Hugging Face Transformers, play a crucial role in their performance. Researchers have explored various optimizations to these frameworks, including efficient memory management, custom operator implementations, and integration with hardware accelerators.
Inference Optimizations
Inference, the process of using a trained LLM to generate new text, can be computationally expensive, especially for large models. Techniques like quantization, pruning, and distillation have been developed to reduce the memory footprint and computational requirements of inference, enabling faster and more efficient deployment of LLMs.
Critical Analysis
The paper provides a comprehensive overview of the state-of-the-art in LLM acceleration and optimization, covering a range of techniques across different aspects of the LLM pipeline. However, the authors acknowledge that there are still significant challenges and areas for further research:
- Scalability: As LLMs continue to grow in size and complexity, the scaling of distributed training and inference optimizations will become increasingly important.
- Hardware Limitations: Current hardware accelerators, such as GPUs, may not be able to keep up with the ever-increasing demands of LLMs, necessitating the development of specialized hardware.
- Energy Efficiency: The high energy consumption of training and running LLMs is a significant concern, and more research is needed to improve their energy efficiency.
Additionally, the review focuses primarily on technical aspects, and there may be opportunities to explore the societal and ethical implications of these performance optimization techniques, such as their impact on the accessibility and responsible deployment of LLMs.
Conclusion
This systematic review provides a comprehensive overview of the latest advancements in achieving peak performance for large language models. By exploring techniques for distributed training, GPU acceleration, LLM framework optimization, and inference optimizations, the paper highlights the significant progress that has been made in unlocking the full potential of these powerful AI models.
As LLMs continue to grow in scale and complexity, the optimizations discussed in this paper will play a crucial role in enabling their widespread adoption and deployment in real-world applications. However, the authors also identify key challenges, such as scalability, hardware limitations, and energy efficiency, that will require ongoing research and innovation to address.
By synthesizing the state-of-the-art in LLM acceleration and optimization, this review serves as a valuable resource for researchers, engineers, and practitioners working to advance the field of large language models and drive the next generation of AI-powered applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Achieving Peak Performance for Large Language Models: A Systematic Review
Zhyar Rzgar K Rostam, S'andor Sz'en'asi, G'abor Kert'esz
In recent years, large language models (LLMs) have achieved remarkable success in natural language processing (NLP). LLMs require an extreme amount of parameters to attain high performance. As models grow into the trillion-parameter range, computational and memory costs increase significantly. This makes it difficult for many researchers to access the resources needed to train or apply these models. Optimizing LLM performance involves two main approaches: fine-tuning pre-trained models for specific tasks to achieve state-of-the-art performance, and reducing costs or improving training time while maintaining similar performance. This paper presents a systematic literature review (SLR) following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) statement. We reviewed 65 publications out of 983 from 2017 to December 2023, retrieved from 5 databases. The study presents methods to optimize and accelerate LLMs while achieving cutting-edge results without sacrificing accuracy. We begin with an overview of the development of language modeling, followed by a detailed explanation of commonly used frameworks and libraries, and a taxonomy for improving and speeding up LLMs based on three classes: LLM training, LLM inference, and system serving. We then delve into recent optimization and acceleration strategies such as training optimization, hardware optimization, scalability and reliability, accompanied by the taxonomy and categorization of these strategies. Finally, we provide an in-depth comparison of each class and strategy, with two case studies on optimizing model training and enhancing inference efficiency. These case studies showcase practical approaches to address LLM resource limitations while maintaining performance.
Read more9/10/2024
0
Towards Efficient Large Language Models for Scientific Text: A Review
Huy Quoc To, Ming Liu, Guangyan Huang
Large language models (LLMs) have ushered in a new era for processing complex information in various fields, including science. The increasing amount of scientific literature allows these models to acquire and understand scientific knowledge effectively, thus improving their performance in a wide range of tasks. Due to the power of LLMs, they require extremely expensive computational resources, intense amounts of data, and training time. Therefore, in recent years, researchers have proposed various methodologies to make scientific LLMs more affordable. The most well-known approaches align in two directions. It can be either focusing on the size of the models or enhancing the quality of data. To date, a comprehensive review of these two families of methods has not yet been undertaken. In this paper, we (I) summarize the current advances in the emerging abilities of LLMs into more accessible AI solutions for science, and (II) investigate the challenges and opportunities of developing affordable solutions for scientific domains using LLMs.
Read more8/21/2024
0
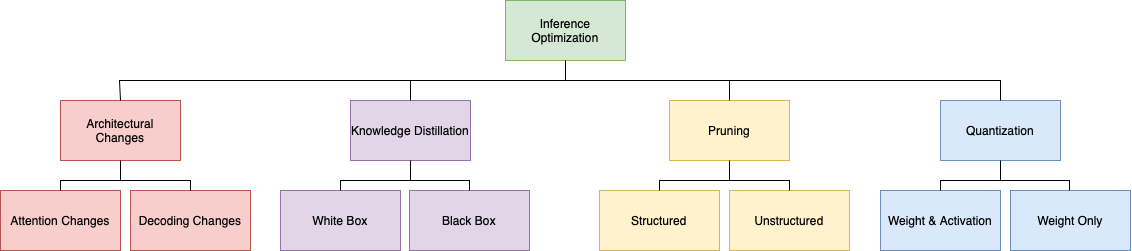
Inference Optimizations for Large Language Models: Effects, Challenges, and Practical Considerations
Leo Donisch, Sigurd Schacht, Carsten Lanquillon
Large language models are ubiquitous in natural language processing because they can adapt to new tasks without retraining. However, their sheer scale and complexity present unique challenges and opportunities, prompting researchers and practitioners to explore novel model training, optimization, and deployment methods. This literature review focuses on various techniques for reducing resource requirements and compressing large language models, including quantization, pruning, knowledge distillation, and architectural optimizations. The primary objective is to explore each method in-depth and highlight its unique challenges and practical applications. The discussed methods are categorized into a taxonomy that presents an overview of the optimization landscape and helps navigate it to understand the research trajectory better.
Read more8/7/2024
💬
0
Efficient Large Language Models: A Survey
Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, Mi Zhang
Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding and language generation, and thus have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we organize the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey. We will actively maintain the repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of efficient LLMs research and inspire them to contribute to this important and exciting field.
Read more5/24/2024