Inference Optimizations for Large Language Models: Effects, Challenges, and Practical Considerations

0
Sign in to get full access
Overview
- Explores the effects, challenges, and practical considerations of inference optimizations for large language models
- Covers techniques like quantization, pruning, and knowledge distillation
- Discusses the impact of these optimizations on model performance, efficiency, and quality
Plain English Explanation
Large language models, like GPT-3 and BERT, are incredibly powerful but also computationally intensive. This means they require a lot of computing power to run, which can be expensive and energy-intensive. Inference Optimizations for Large Language Models looks at different ways to make these models more efficient during the inference (or prediction) stage, without significantly degrading their performance.
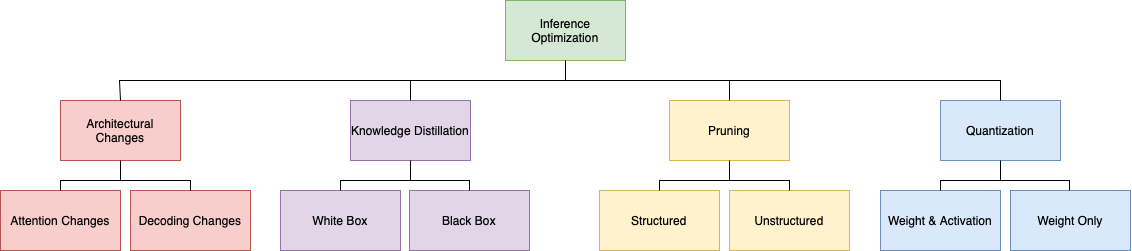
The paper explores techniques like quantization, which reduces the precision of the model's parameters, pruning, which removes less important parts of the model, and knowledge distillation, which trains a smaller, more efficient model to mimic the behavior of the larger one.
The researchers investigate how these optimizations affect the model's accuracy, speed, and memory usage. They also discuss the practical challenges of deploying these techniques, such as the need to balance performance and quality tradeoffs. Overall, the paper provides valuable insights for researchers and developers working on making large language models more accessible and practical for real-world applications.
Technical Explanation
Inference Optimizations for Large Language Models examines various techniques to improve the efficiency of running large language models during the inference stage, while minimizing the impact on model performance.
The paper covers several optimization methods, including quantization, which reduces the bit-width of model parameters; pruning, which selectively removes less important model components; and knowledge distillation, where a smaller, more efficient student model is trained to mimic the behavior of a larger, more complex teacher model.
The researchers analyze the impact of these optimizations on key metrics like model accuracy, inference latency, and memory usage. They also discuss the practical challenges of deploying these techniques, such as the need to balance performance and quality trade-offs, and the importance of carefully tuning hyperparameters to achieve the desired results.
Additionally, the paper explores optimization strategies for specific model components, such as the attention mechanism and the decoding process, which can significantly impact overall efficiency.
Overall, the technical insights provided in this paper are valuable for researchers and engineers working on making large language models more practical and accessible for real-world applications.
Critical Analysis
The paper provides a comprehensive overview of various inference optimization techniques for large language models, including their potential benefits and challenges. However, it's important to note that the effectiveness of these optimizations can be highly dependent on the specific model architecture, task, and deployment constraints.
While the paper discusses the trade-offs between performance and quality, it doesn't delve into the nuances of how these trade-offs may vary across different use cases. For example, some applications may prioritize inference speed over model accuracy, while others may have strict quality requirements that limit the extent of optimization.
Additionally, the paper doesn't address the potential impact of these optimizations on the model's robustness or fairness, which are crucial considerations for real-world deployments. Further research is needed to understand how these techniques may affect the model's behavior in diverse and potentially adversarial scenarios.
Finally, the paper focuses primarily on optimization at the model level, but it doesn't explore system-level optimizations, such as hardware acceleration or distributed inference, which can also play a significant role in improving the overall efficiency of large language models.
Conclusion
Inference Optimizations for Large Language Models provides valuable insights into the effects, challenges, and practical considerations of applying various optimization techniques to improve the efficiency of running large language models during the inference stage. The paper covers key methods like quantization, pruning, and knowledge distillation, and discusses their impact on model performance, latency, and memory usage.
While the technical details and trade-offs explored in this paper are important for researchers and developers working on large language models, it's crucial to consider the specific requirements and constraints of the target application when deploying these optimizations. Continued research and experimentation will be necessary to ensure that these techniques can be effectively and responsibly applied to make large language models more accessible and practical for a wide range of real-world use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Inference Optimizations for Large Language Models: Effects, Challenges, and Practical Considerations
Leo Donisch, Sigurd Schacht, Carsten Lanquillon
Large language models are ubiquitous in natural language processing because they can adapt to new tasks without retraining. However, their sheer scale and complexity present unique challenges and opportunities, prompting researchers and practitioners to explore novel model training, optimization, and deployment methods. This literature review focuses on various techniques for reducing resource requirements and compressing large language models, including quantization, pruning, knowledge distillation, and architectural optimizations. The primary objective is to explore each method in-depth and highlight its unique challenges and practical applications. The discussed methods are categorized into a taxonomy that presents an overview of the optimization landscape and helps navigate it to understand the research trajectory better.
Read more8/7/2024
🛠️
0
Efficiency optimization of large-scale language models based on deep learning in natural language processing tasks
Taiyuan Mei, Yun Zi, Xiaohan Cheng, Zijun Gao, Qi Wang, Haowei Yang
The internal structure and operation mechanism of large-scale language models are analyzed theoretically, especially how Transformer and its derivative architectures can restrict computing efficiency while capturing long-term dependencies. Further, we dig deep into the efficiency bottleneck of the training phase, and evaluate in detail the contribution of adaptive optimization algorithms (such as AdamW), massively parallel computing techniques, and mixed precision training strategies to accelerate convergence and reduce memory footprint. By analyzing the mathematical principles and implementation details of these algorithms, we reveal how they effectively improve training efficiency in practice. In terms of model deployment and inference optimization, this paper systematically reviews the latest advances in model compression techniques, focusing on strategies such as quantification, pruning, and knowledge distillation. By comparing the theoretical frameworks of these techniques and their effects in different application scenarios, we demonstrate their ability to significantly reduce model size and inference delay while maintaining model prediction accuracy. In addition, this paper critically examines the limitations of current efficiency optimization methods, such as the increased risk of overfitting, the control of performance loss after compression, and the problem of algorithm generality, and proposes some prospects for future research. In conclusion, this study provides a comprehensive theoretical framework for understanding the efficiency optimization of large-scale language models.
Read more5/21/2024
📈
0
A Survey on Model Compression for Large Language Models
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, Weiping Wang
Large Language Models (LLMs) have transformed natural language processing tasks successfully. Yet, their large size and high computational needs pose challenges for practical use, especially in resource-limited settings. Model compression has emerged as a key research area to address these challenges. This paper presents a survey of model compression techniques for LLMs. We cover methods like quantization, pruning, and knowledge distillation, highlighting recent advancements. We also discuss benchmarking strategies and evaluation metrics crucial for assessing compressed LLMs. This survey offers valuable insights for researchers and practitioners, aiming to enhance efficiency and real-world applicability of LLMs while laying a foundation for future advancements.
Read more7/31/2024
📈
0
Contemporary Model Compression on Large Language Models Inference
Dong Liu
Large Language Models (LLMs) have revolutionized natural language processing by achieving state-of-the-art results across a variety of tasks. However, the computational demands of LLM inference, including high memory consumption and slow processing speeds, pose significant challenges for real-world applications, particularly on resource-constrained devices. Efficient inference is crucial for scaling the deployment of LLMs to a broader range of platforms, including mobile and edge devices. This survey explores contemporary techniques in model compression that address these challenges by reducing the size and computational requirements of LLMs while maintaining their performance. We focus on model-level compression methods, including quantization, knowledge distillation, and pruning, as well as system-level optimizations like KV cache efficient design. Each of these methodologies offers a unique approach to optimizing LLMs, from reducing numerical precision to transferring knowledge between models and structurally simplifying neural networks. Additionally, we discuss emerging trends in system-level design that further enhance the efficiency of LLM inference. This survey aims to provide a comprehensive overview of current advancements in model compression and their potential to make LLMs more accessible and practical for diverse applications.
Read more9/4/2024