Activations Through Extensions: A Framework To Boost Performance Of Neural Networks

0
🚀
Sign in to get full access
Overview
- This research paper proposes a framework that unifies several works on activation functions in neural networks.
- It introduces novel techniques that allow for "extensions" of neural networks by modifying the activation functions.
- The authors claim these "extensions" provide performance benefits compared to standard neural networks with minimal computational overhead.
- The benefits are demonstrated on standard test functions as well as real-world time-series datasets.
Plain English Explanation
Neural networks are a type of machine learning model inspired by the human brain. They learn complex relationships between inputs (like images or text) and outputs (like classifications or predictions) by adjusting the strengths of connections between artificial neurons.
A key part of neural networks is the activation function, which determines how each neuron responds to its inputs. Common activation functions include ReLU, Tanh, and Sigmoid. The choice of activation function can significantly impact a neural network's performance.
This paper proposes a general framework that explains the benefits of different activation functions and allows for the creation of "extended" neural networks with novel activation functions. These "extended" networks are shown to outperform standard neural networks on both test functions and real-world time-series data, with minimal additional computational cost.
The key idea is that by carefully designing the activation function, you can enhance the neural network's ability to learn complex patterns in the data. The authors provide both theoretical justification and empirical evidence for the effectiveness of this approach.
Technical Explanation
The paper first establishes a unifying mathematical framework for analyzing activation functions in neural networks. This framework allows the authors to derive theoretical performance bounds and understand the inductive biases introduced by different activation functions.
Building on this framework, the authors propose novel techniques for "extending" neural networks by modifying the activation functions. These "extensions" are shown to have greater expressive power than standard neural networks, meaning they can represent a broader class of functions.
The paper describes two main ways to create these "extended" neural networks:
-
Latent Assistance Networks: This approach introduces a "latent" activation function that is learned alongside the network weights, allowing for more flexibility.
-
Trainable Highly Expressive Activation Functions: Here, the activation function itself is parameterized and trained, rather than being a fixed function like ReLU or Tanh.
The authors demonstrate the effectiveness of these "extended" neural networks on both synthetic test functions and real-world time-series datasets. They show consistent performance improvements over standard neural networks, with only a modest increase in computational complexity.
Critical Analysis
The paper provides a strong theoretical foundation for understanding activation functions and their role in neural network performance. The proposed framework and techniques for "extending" neural networks are well-grounded and backed by empirical evidence.
However, the paper does not address some potential limitations or areas for further research:
- The experiments are limited to relatively small-scale datasets and problems. It would be helpful to see the performance of these "extended" neural networks on larger, more complex real-world tasks.
- The paper does not explore the sensitivity of the "extended" networks to hyperparameter choices, such as the specific parameterization of the activation function. This could be an important consideration for practical applications.
- While the computational overhead of the "extended" networks is claimed to be minimal, a more thorough analysis of the training and inference time complexity would help quantify the tradeoffs.
Overall, this paper makes a valuable contribution to the understanding and development of activation functions in neural networks. The proposed techniques show promise, but further research is needed to fully assess their practical impact and generalizability.
Conclusion
This research paper introduces a unifying framework for activation functions in neural networks and proposes novel techniques for "extending" neural networks by modifying the activation functions. The authors demonstrate that these "extended" neural networks can outperform standard neural networks on both synthetic and real-world datasets, with only a modest increase in computational complexity.
The theoretical and empirical results presented in this paper suggest that the choice of activation function is a crucial component in the design of effective neural networks. By carefully engineering the activation function, researchers and practitioners may be able to develop more powerful and efficient machine learning models for a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
Activations Through Extensions: A Framework To Boost Performance Of Neural Networks
Chandramouli Kamanchi, Sumanta Mukherjee, Kameshwaran Sampath, Pankaj Dayama, Arindam Jati, Vijay Ekambaram, Dzung Phan
Activation functions are non-linearities in neural networks that allow them to learn complex mapping between inputs and outputs. Typical choices for activation functions are ReLU, Tanh, Sigmoid etc., where the choice generally depends on the application domain. In this work, we propose a framework/strategy that unifies several works on activation functions and theoretically explains the performance benefits of these works. We also propose novel techniques that originate from the framework and allow us to obtain ``extensions'' (i.e. special generalizations of a given neural network) of neural networks through operations on activation functions. We theoretically and empirically show that ``extensions'' of neural networks have performance benefits compared to vanilla neural networks with insignificant space and time complexity costs on standard test functions. We also show the benefits of neural network ``extensions'' in the time-series domain on real-world datasets.
Read more8/19/2024
📉
0
Nonlinearity Enhanced Adaptive Activation Function
David Yevick
A simply implemented activation function with even cubic nonlinearity is introduced that increases the accuracy of neural networks without substantial additional computational resources. This is partially enabled through an apparent tradeoff between convergence and accuracy. The activation function generalizes the standard RELU function by introducing additional degrees of freedom through optimizable parameters that enable the degree of nonlinearity to be adjusted. The associated accuracy enhancement is quantified in the context of the MNIST digit data set through a comparison with standard techniques.
Read more4/1/2024
🛠️
0
Activation Function Optimization Scheme for Image Classification
Abdur Rahman, Lu He, Haifeng Wang
Activation function has a significant impact on the dynamics, convergence, and performance of deep neural networks. The search for a consistent and high-performing activation function has always been a pursuit during deep learning model development. Existing state-of-the-art activation functions are manually designed with human expertise except for Swish. Swish was developed using a reinforcement learning-based search strategy. In this study, we propose an evolutionary approach for optimizing activation functions specifically for image classification tasks, aiming to discover functions that outperform current state-of-the-art options. Through this optimization framework, we obtain a series of high-performing activation functions denoted as Exponential Error Linear Unit (EELU). The developed activation functions are evaluated for image classification tasks from two perspectives: (1) five state-of-the-art neural network architectures, such as ResNet50, AlexNet, VGG16, MobileNet, and Compact Convolutional Transformer which cover computationally heavy to light neural networks, and (2) eight standard datasets, including CIFAR10, Imagenette, MNIST, Fashion MNIST, Beans, Colorectal Histology, CottonWeedID15, and TinyImageNet which cover from typical machine vision benchmark, agricultural image applications to medical image applications. Finally, we statistically investigate the generalization of the resultant activation functions developed through the optimization scheme. With a Friedman test, we conclude that the optimization scheme is able to generate activation functions that outperform the existing standard ones in 92.8% cases among 28 different cases studied, and $-xcdot erf(e^{-x})$ is found to be the best activation function for image classification generated by the optimization scheme.
Read more9/10/2024
0
Latent Assistance Networks: Rediscovering Hyperbolic Tangents in RL
Jacob E. Kooi, Mark Hoogendoorn, Vincent Franc{c}ois-Lavet
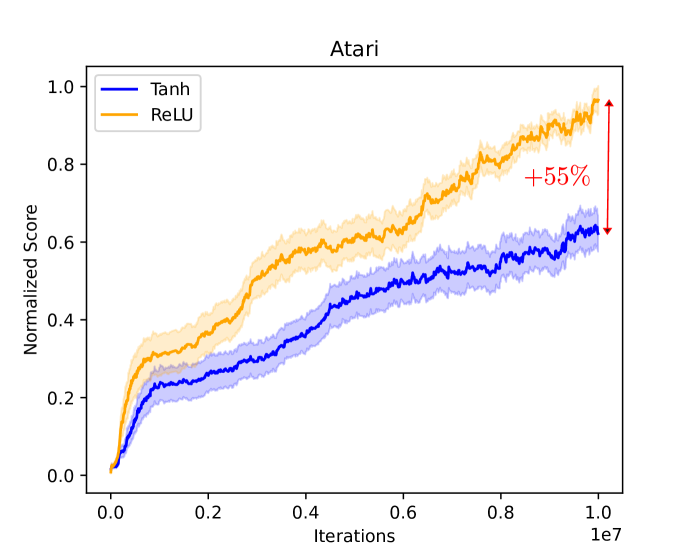
Activation functions are one of the key components of a neural network. The most commonly used activation functions can be classed into the category of continuously differentiable (e.g. tanh) and linear-unit functions (e.g. ReLU), both having their own strengths and drawbacks with respect to downstream performance and representation capacity through learning (e.g. measured by the number of dead neurons and the effective rank). In reinforcement learning, the performance of continuously differentiable activations often falls short as compared to linear-unit functions. From the perspective of the activations in the last hidden layer, this paper provides insights regarding this sub-optimality and explores how activation functions influence the occurrence of dead neurons and the magnitude of the effective rank. Additionally, a novel neural architecture is proposed that leverages the product of independent activation values. In the Atari domain, we show faster learning, a reduction in dead neurons and increased effective rank.
Read more6/14/2024