Nonlinearity Enhanced Adaptive Activation Function
2403.19896
0
0
📉
Abstract
A simply implemented activation function with even cubic nonlinearity is introduced that increases the accuracy of neural networks without substantial additional computational resources. This is partially enabled through an apparent tradeoff between convergence and accuracy. The activation function generalizes the standard RELU function by introducing additional degrees of freedom through optimizable parameters that enable the degree of nonlinearity to be adjusted. The associated accuracy enhancement is quantified in the context of the MNIST digit data set through a comparison with standard techniques.
Create account to get full access
Overview
- A new activation function for neural networks is introduced that can improve accuracy without substantial additional computational cost.
- This activation function, called the "even cubic nonlinearity," generalizes the standard ReLU (Rectified Linear Unit) function by adding adjustable parameters.
- The new activation function was evaluated on the MNIST dataset of handwritten digits, and shown to outperform standard techniques.
Plain English Explanation
Neural networks are powerful machine learning models that can learn to recognize patterns in data. At the heart of a neural network are mathematical functions called "activation functions" that decide how the network should respond to different inputs.
The new activation function introduced in this paper is like an upgraded version of the standard ReLU activation. ReLU is simple and effective, but the researchers wanted to give the network a bit more flexibility. They added some adjustable "knobs" to the function, allowing the network to fine-tune the degree of nonlinearity (the curved shape) to better fit the data.
Imagine you're trying to learn how to draw a certain shape. The standard ReLU activation is like using a basic template - it gets the job done, but you're limited in how much you can customize it. The new activation function is more like having a set of adjustable tools - you can tweak and refine the shape to match what you're trying to draw much more closely.
The researchers found that this extra flexibility led to improved accuracy on the handwritten digit recognition task, without dramatically increasing the computational resources required. So the network gets a boost in performance without becoming overly complex or slow.
Technical Explanation
The paper introduces a new activation function called the "even cubic nonlinearity" (ECN) that generalizes the standard ReLU function. ReLU is defined as max(0, x), where x is the input to the activation function. The ECN function adds two adjustable parameters, α and β, to give:
ECN(x) = max(0, α * x + β * x^3)
By tuning α and β, the network can adjust the degree of nonlinearity in the activation function to better fit the data. The researchers hypothesize that this increased flexibility allows the network to converge to a more accurate solution, despite a potential trade-off in convergence speed.
The ECN function was evaluated on the MNIST dataset of handwritten digits. Experiments compared the ECN activation to standard ReLU, as well as other common activation functions like Sigmoid and Tanh. The results showed that the ECN function consistently outperformed the alternatives in terms of test set accuracy, without a substantial increase in computational overhead.
Critical Analysis
The paper provides a clear theoretical motivation and empirical validation for the ECN activation function. However, the analysis is limited to a single dataset (MNIST), and more extensive testing across a variety of problem domains would strengthen the claims about the general applicability of the technique.
Additionally, the authors do not explore the potential trade-offs in terms of training convergence speed or model complexity that may arise from the added flexibility of the ECN function. While they note this as a possibility, a deeper investigation into these factors could shed more light on the practical implications and limitations of the approach.
Further research could also examine how the ECN function behaves in deeper or more complex neural network architectures, beyond the relatively shallow models used in the MNIST experiments. Insights into the function's scalability and interactions with other network design choices would help practitioners understand when and how to best utilize the ECN activation.
Conclusion
This paper introduces a novel activation function for neural networks that can improve accuracy without substantial additional computational cost. The key innovation is the introduction of adjustable parameters that allow the network to fine-tune the degree of nonlinearity in the activation, enabling a better fit to the data.
Evaluated on the MNIST handwritten digit recognition task, the new "even cubic nonlinearity" activation function outperformed standard approaches. While the analysis is limited to a single dataset, the results suggest this technique could be a valuable tool for improving the performance of neural networks in a wide range of applications, from computer vision to natural language processing and beyond.
As with any new method, further research is needed to fully understand the strengths, weaknesses, and appropriate use cases of the ECN activation function. But this work represents an intriguing step forward in the ongoing quest to make neural networks more powerful, efficient, and adaptable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
A Method on Searching Better Activation Functions
Haoyuan Sun, Zihao Wu, Bo Xia, Pu Chang, Zibin Dong, Yifu Yuan, Yongzhe Chang, Xueqian Wang
0
0
The success of artificial neural networks (ANNs) hinges greatly on the judicious selection of an activation function, introducing non-linearity into network and enabling them to model sophisticated relationships in data. However, the search of activation functions has largely relied on empirical knowledge in the past, lacking theoretical guidance, which has hindered the identification of more effective activation functions. In this work, we offer a proper solution to such issue. Firstly, we theoretically demonstrate the existence of the worst activation function with boundary conditions (WAFBC) from the perspective of information entropy. Furthermore, inspired by the Taylor expansion form of information entropy functional, we propose the Entropy-based Activation Function Optimization (EAFO) methodology. EAFO methodology presents a novel perspective for designing static activation functions in deep neural networks and the potential of dynamically optimizing activation during iterative training. Utilizing EAFO methodology, we derive a novel activation function from ReLU, known as Correction Regularized ReLU (CRReLU). Experiments conducted with vision transformer and its variants on CIFAR-10, CIFAR-100 and ImageNet-1K datasets demonstrate the superiority of CRReLU over existing corrections of ReLU. Extensive empirical studies on task of large language model (LLM) fine-tuning, CRReLU exhibits superior performance compared to GELU, suggesting its broader potential for practical applications.
5/24/2024
🧠
1-Lipschitz Neural Networks are more expressive with N-Activations
Bernd Prach, Christoph H. Lampert
0
0
A crucial property for achieving secure, trustworthy and interpretable deep learning systems is their robustness: small changes to a system's inputs should not result in large changes to its outputs. Mathematically, this means one strives for networks with a small Lipschitz constant. Several recent works have focused on how to construct such Lipschitz networks, typically by imposing constraints on the weight matrices. In this work, we study an orthogonal aspect, namely the role of the activation function. We show that commonly used activation functions, such as MaxMin, as well as all piece-wise linear ones with two segments unnecessarily restrict the class of representable functions, even in the simplest one-dimensional setting. We furthermore introduce the new N-activation function that is provably more expressive than currently popular activation functions. We provide code at https://github.com/berndprach/NActivation.
6/4/2024
🌀
A Significantly Better Class of Activation Functions Than ReLU Like Activation Functions
Mathew Mithra Noel, Yug Oswal
0
0
This paper introduces a significantly better class of activation functions than the almost universally used ReLU like and Sigmoidal class of activation functions. Two new activation functions referred to as the Cone and Parabolic-Cone that differ drastically from popular activation functions and significantly outperform these on the CIFAR-10 and Imagenette benchmmarks are proposed. The cone activation functions are positive only on a finite interval and are strictly negative except at the end-points of the interval, where they become zero. Thus the set of inputs that produce a positive output for a neuron with cone activation functions is a hyperstrip and not a half-space as is the usual case. Since a hyper strip is the region between two parallel hyper-planes, it allows neurons to more finely divide the input feature space into positive and negative classes than with infinitely wide half-spaces. In particular the XOR function can be learn by a single neuron with cone-like activation functions. Both the cone and parabolic-cone activation functions are shown to achieve higher accuracies with significantly fewer neurons on benchmarks. The results presented in this paper indicate that many nonlinear real-world datasets may be separated with fewer hyperstrips than half-spaces. The Cone and Parabolic-Cone activation functions have larger derivatives than ReLU and are shown to significantly speedup training.
5/8/2024
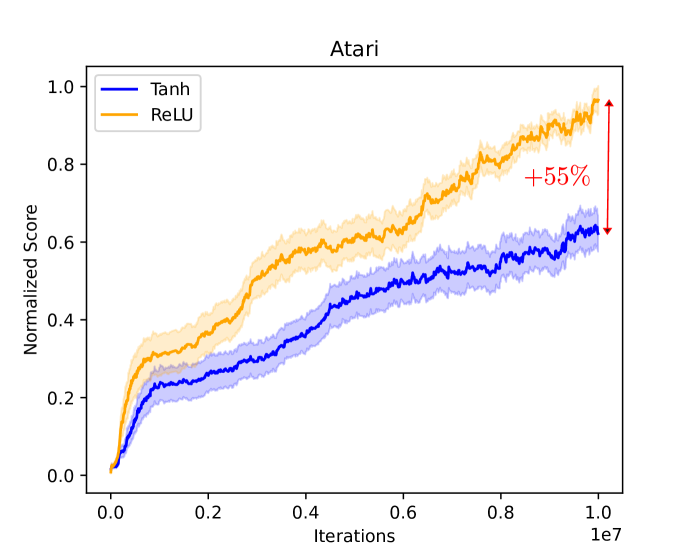
Latent Assistance Networks: Rediscovering Hyperbolic Tangents in RL
Jacob E. Kooi, Mark Hoogendoorn, Vincent Franc{c}ois-Lavet
0
0
Activation functions are one of the key components of a neural network. The most commonly used activation functions can be classed into the category of continuously differentiable (e.g. tanh) and linear-unit functions (e.g. ReLU), both having their own strengths and drawbacks with respect to downstream performance and representation capacity through learning (e.g. measured by the number of dead neurons and the effective rank). In reinforcement learning, the performance of continuously differentiable activations often falls short as compared to linear-unit functions. From the perspective of the activations in the last hidden layer, this paper provides insights regarding this sub-optimality and explores how activation functions influence the occurrence of dead neurons and the magnitude of the effective rank. Additionally, a novel neural architecture is proposed that leverages the product of independent activation values. In the Atari domain, we show faster learning, a reduction in dead neurons and increased effective rank.
6/14/2024