Latent Assistance Networks: Rediscovering Hyperbolic Tangents in RL
2406.09079
0
0
Abstract
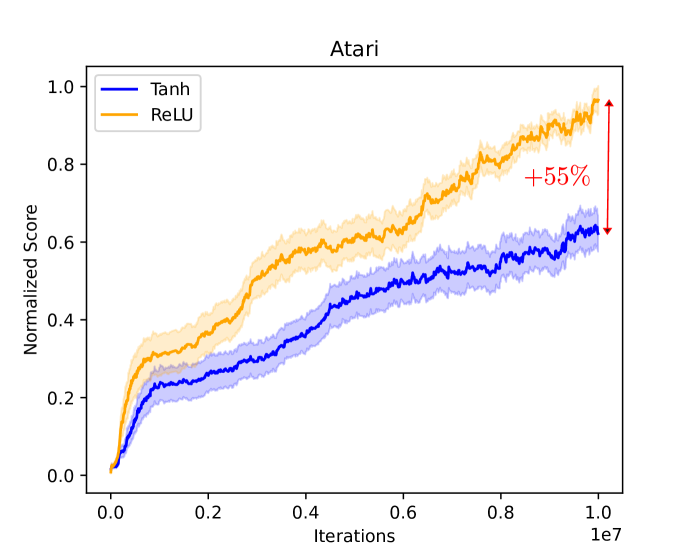
Activation functions are one of the key components of a neural network. The most commonly used activation functions can be classed into the category of continuously differentiable (e.g. tanh) and linear-unit functions (e.g. ReLU), both having their own strengths and drawbacks with respect to downstream performance and representation capacity through learning (e.g. measured by the number of dead neurons and the effective rank). In reinforcement learning, the performance of continuously differentiable activations often falls short as compared to linear-unit functions. From the perspective of the activations in the last hidden layer, this paper provides insights regarding this sub-optimality and explores how activation functions influence the occurrence of dead neurons and the magnitude of the effective rank. Additionally, a novel neural architecture is proposed that leverages the product of independent activation values. In the Atari domain, we show faster learning, a reduction in dead neurons and increased effective rank.
Create account to get full access
Overview
- Explores a new class of activation functions called Latent Assistance Networks (LANs) that can outperform traditional activation functions like ReLU in reinforcement learning tasks
- Introduces a novel training approach that discovers these specialized activation functions automatically
- Demonstrates the expressive power and Lipschitz continuity of LANs, showing they can be more expressive than typical neural networks
Plain English Explanation
Artificial neural networks, the building blocks of modern AI, use special functions called "activation functions" to process information. The most common activation function is the Rectified Linear Unit (ReLU), which has been widely used for its simplicity and effectiveness. However, researchers have been exploring ways to find better activation functions that can further improve the performance of neural networks.
In this paper, the authors introduce a new class of activation functions called "Latent Assistance Networks" (LANs). LANs are designed to be more expressive and flexible than ReLU, allowing neural networks to learn more complex patterns in data. The key insight is that by making the activation functions learnable, the network can discover specialized functions that are better suited for the specific problem it's trying to solve.
The researchers developed a novel training approach that allows neural networks to automatically discover these specialized activation functions, rather than using a fixed function like ReLU. They show that LANs can outperform traditional activation functions in reinforcement learning tasks, which involve an agent learning to take actions in an environment to maximize a reward.
One of the interesting properties of LANs is that they can be more expressive than typical neural networks, meaning they can represent a wider range of functions. This is because LANs are Lipschitz continuous, a mathematical property that allows them to be more flexible and adaptable.
Overall, this research introduces a promising new direction for improving the performance of neural networks by discovering better activation functions that are tailored to the specific problem at hand.
Technical Explanation
The authors propose a new class of activation functions called "Latent Assistance Networks" (LANs) that can outperform traditional activation functions like ReLU in reinforcement learning tasks. LANs are designed to be more expressive and flexible than ReLU by making the activation functions learnable, rather than using a fixed function.
The key idea is to parameterize the activation function using a neural network, which allows the network to automatically discover specialized functions that are well-suited for the specific problem it's trying to solve. The authors develop a novel training approach that enables this discovery process, where the activation function parameters are learned jointly with the other network weights.
Through experiments, the authors demonstrate that LANs can achieve significantly better performance than ReLU on various reinforcement learning benchmarks. They also analyze the theoretical properties of LANs, showing that they are Lipschitz continuous and can be more expressive than typical neural networks. This increased expressivity and adaptability is a key factor in their improved performance.
Critical Analysis
The authors present a compelling case for the use of Latent Assistance Networks as a powerful alternative to traditional activation functions. By making the activation functions learnable, the network can discover specialized functions that are better suited for the problem at hand, leading to improved performance on reinforcement learning tasks.
One potential limitation of the approach is the increased computational complexity and training time required to learn the activation function parameters in addition to the network weights. The authors acknowledge this trade-off and suggest that further research may be needed to optimize the training process and make LANs more practical for large-scale applications.
Additionally, while the authors demonstrate the theoretical advantages of LANs in terms of expressivity and Lipschitz continuity, it would be interesting to see more detailed analysis on the types of problems or domains where these properties confer the greatest benefits. Further research could explore the specific characteristics of tasks and environments where LANs excel compared to other activation functions.
Overall, the introduction of Latent Assistance Networks represents an exciting advancement in the search for better activation functions and highlights the potential for neural networks to automatically discover specialized components that can enhance their performance.
Conclusion
This research paper presents a novel class of activation functions called Latent Assistance Networks (LANs) that can outperform traditional activation functions like ReLU in reinforcement learning tasks. By making the activation functions learnable, the network can discover specialized functions that are better suited for the specific problem it's trying to solve.
The authors demonstrate the expressive power and Lipschitz continuity of LANs, showing that they can be more flexible and adaptable than typical neural networks. While the increased computational complexity is a potential limitation, the improvements in reinforcement learning performance suggest that LANs could be a valuable tool for advancing the state-of-the-art in AI and machine learning.
This research opens up new avenues for exploring more expressive and adaptive activation functions that can unlock the full potential of neural networks, and it encourages researchers to continue searching for better activation functions that can lead to significant advancements in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
A Method on Searching Better Activation Functions
Haoyuan Sun, Zihao Wu, Bo Xia, Pu Chang, Zibin Dong, Yifu Yuan, Yongzhe Chang, Xueqian Wang
0
0
The success of artificial neural networks (ANNs) hinges greatly on the judicious selection of an activation function, introducing non-linearity into network and enabling them to model sophisticated relationships in data. However, the search of activation functions has largely relied on empirical knowledge in the past, lacking theoretical guidance, which has hindered the identification of more effective activation functions. In this work, we offer a proper solution to such issue. Firstly, we theoretically demonstrate the existence of the worst activation function with boundary conditions (WAFBC) from the perspective of information entropy. Furthermore, inspired by the Taylor expansion form of information entropy functional, we propose the Entropy-based Activation Function Optimization (EAFO) methodology. EAFO methodology presents a novel perspective for designing static activation functions in deep neural networks and the potential of dynamically optimizing activation during iterative training. Utilizing EAFO methodology, we derive a novel activation function from ReLU, known as Correction Regularized ReLU (CRReLU). Experiments conducted with vision transformer and its variants on CIFAR-10, CIFAR-100 and ImageNet-1K datasets demonstrate the superiority of CRReLU over existing corrections of ReLU. Extensive empirical studies on task of large language model (LLM) fine-tuning, CRReLU exhibits superior performance compared to GELU, suggesting its broader potential for practical applications.
5/24/2024
🧠
1-Lipschitz Neural Networks are more expressive with N-Activations
Bernd Prach, Christoph H. Lampert
0
0
A crucial property for achieving secure, trustworthy and interpretable deep learning systems is their robustness: small changes to a system's inputs should not result in large changes to its outputs. Mathematically, this means one strives for networks with a small Lipschitz constant. Several recent works have focused on how to construct such Lipschitz networks, typically by imposing constraints on the weight matrices. In this work, we study an orthogonal aspect, namely the role of the activation function. We show that commonly used activation functions, such as MaxMin, as well as all piece-wise linear ones with two segments unnecessarily restrict the class of representable functions, even in the simplest one-dimensional setting. We furthermore introduce the new N-activation function that is provably more expressive than currently popular activation functions. We provide code at https://github.com/berndprach/NActivation.
6/4/2024
📉
Nonlinearity Enhanced Adaptive Activation Function
David Yevick
0
0
A simply implemented activation function with even cubic nonlinearity is introduced that increases the accuracy of neural networks without substantial additional computational resources. This is partially enabled through an apparent tradeoff between convergence and accuracy. The activation function generalizes the standard RELU function by introducing additional degrees of freedom through optimizable parameters that enable the degree of nonlinearity to be adjusted. The associated accuracy enhancement is quantified in the context of the MNIST digit data set through a comparison with standard techniques.
4/1/2024

Your Network May Need to Be Rewritten: Network Adversarial Based on High-Dimensional Function Graph Decomposition
Xiaoyan Su, Yinghao Zhu, Run Li
0
0
In the past, research on a single low dimensional activation function in networks has led to internal covariate shift and gradient deviation problems. A relatively small research area is how to use function combinations to provide property completion for a single activation function application. We propose a network adversarial method to address the aforementioned challenges. This is the first method to use different activation functions in a network. Based on the existing activation functions in the current network, an adversarial function with opposite derivative image properties is constructed, and the two are alternately used as activation functions for different network layers. For complex situations, we propose a method of high-dimensional function graph decomposition(HD-FGD), which divides it into different parts and then passes through a linear layer. After integrating the inverse of the partial derivatives of each decomposed term, we obtain its adversarial function by referring to the computational rules of the decomposition process. The use of network adversarial methods or the use of HD-FGD alone can effectively replace the traditional MLP+activation function mode. Through the above methods, we have achieved a substantial improvement over standard activation functions regarding both training efficiency and predictive accuracy. The article addresses the adversarial issues associated with several prevalent activation functions, presenting alternatives that can be seamlessly integrated into existing models without any adverse effects. We will release the code as open source after the conference review process is completed.
5/8/2024