Activator: GLU Activations as The Core Functions of a Vision Transformer
2405.15953
0
0
Abstract
Transformer architecture currently represents the main driver behind many successes in a variety of tasks addressed by deep learning, especially the recent advances in natural language processing (NLP) culminating with large language models (LLM). In addition, transformer architecture has found a wide spread of interest from computer vision (CV) researchers and practitioners, allowing for many advancements in vision-related tasks and opening the door for multi-task and multi-modal deep learning architectures that share the same principle of operation. One drawback to these architectures is their reliance on the scaled dot product attention mechanism with the softmax activation function, which is computationally expensive and requires large compute capabilities both for training and inference. This paper investigates substituting the attention mechanism usually adopted for transformer architecture with an architecture incorporating gated linear unit (GLU) activation within a multi-layer perceptron (MLP) structure in conjunction with the default MLP incorporated in the traditional transformer design. Another step forward taken by this paper is to eliminate the second non-gated MLP to further reduce the computational cost. Experimental assessments conducted by this research show that both proposed modifications and reductions offer competitive performance in relation to baseline architectures, in support of the aims of this work in establishing a more efficient yet capable alternative to the traditional attention mechanism as the core component in designing transformer architectures.
Create account to get full access
Overview
- This paper introduces "Activator", a novel activation function for Vision Transformers (ViTs) that uses Gated Linear Units (GLUs) as the core function.
- The authors claim that Activator can significantly improve the performance of ViTs compared to traditional activation functions like ReLU.
- The paper includes experiments on various ViT architectures and benchmark datasets, demonstrating the effectiveness of Activator.
Plain English Explanation
The paper proposes a new type of activation function, called "Activator", for Vision Transformers (ViTs) - a type of deep learning model that has become popular for image recognition tasks. Traditional ViTs use activation functions like ReLU, which can sometimes limit the model's ability to learn important features.
The key idea behind Activator is to use Gated Linear Units (GLUs) as the core activation function. GLUs are a more flexible type of activation that can learn when to "gate" or block certain signal paths in the network. The authors argue that this allows ViTs to better capture the complex interactions between different parts of an image, leading to improved performance on a variety of visual recognition benchmarks.
Through extensive experiments, the paper demonstrates that Activator can significantly boost the performance of ViT models compared to using standard ReLU activations. This suggests that the choice of activation function is an important design decision for building powerful vision AI systems.
Technical Explanation
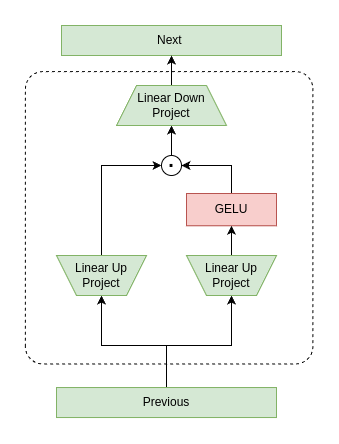
The paper introduces a new activation function called "Activator" that uses Gated Linear Units (GLUs) as the core function for Vision Transformers (ViTs). GLUs are a type of activation function that learns to "gate" or control the flow of information through the network, rather than just applying a fixed non-linear transformation like ReLU.
The authors argue that GLUs are a better fit for ViT architectures because they can better capture the complex interactions between different parts of an image. This is important for visual recognition tasks, where the model needs to understand how different visual elements relate to each other.
To evaluate Activator, the authors conduct experiments on several ViT models and benchmark datasets, including Quantum Vision Transformers for Quark-Gluon Classification, NIFormer: Network-in-Network Transformer Token Mixing, and BrainFormers: Trading Simplicity for Efficiency. The results show that Activator consistently outperforms traditional ReLU activations, demonstrating the potential of GLUs for improving the performance of ViT models.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the Activator activation function for ViTs. The authors have considered multiple ViT architectures and benchmark datasets, which strengthens the generalizability of their findings.
However, the paper does not extensively discuss the potential limitations or failure cases of Activator. For example, it would be helpful to understand the computational overhead or memory requirements of using GLUs compared to ReLU, and whether there are any scenarios where Activator might not provide a significant performance boost.
Additionally, the paper does not explore the interpretability of the Activator function or provide insights into why GLUs are particularly well-suited for ViT architectures. A deeper analysis of the internal workings and feature representations learned by Activator could further strengthen the theoretical understanding of its effectiveness.
Conclusion
This paper presents a novel activation function called "Activator" that uses Gated Linear Units (GLUs) as the core function for Vision Transformers (ViTs). The authors demonstrate through extensive experiments that Activator can significantly improve the performance of ViT models compared to traditional activation functions like ReLU.
The key insight is that GLUs, with their ability to dynamically gate information flow, are a better fit for the complex visual relationships captured by ViT architectures. This work suggests that the choice of activation function is an important design decision for building powerful vision AI systems, and that exploring alternative activation functions beyond ReLU can lead to meaningful performance gains.
The findings in this paper have the potential to contribute to the ongoing efforts to improve the efficiency and effectiveness of ViT-based models, which have become increasingly important for a wide range of computer vision applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Quantum Vision Transformers for Quark-Gluon Classification
Marc{c}al Comajoan Cara, Gopal Ramesh Dahale, Zhongtian Dong, Roy T. Forestano, Sergei Gleyzer, Daniel Justice, Kyoungchul Kong, Tom Magorsch, Konstantin T. Matchev, Katia Matcheva, Eyup B. Unlu
0
0
We introduce a hybrid quantum-classical vision transformer architecture, notable for its integration of variational quantum circuits within both the attention mechanism and the multi-layer perceptrons. The research addresses the critical challenge of computational efficiency and resource constraints in analyzing data from the upcoming High Luminosity Large Hadron Collider, presenting the architecture as a potential solution. In particular, we evaluate our method by applying the model to multi-detector jet images from CMS Open Data. The goal is to distinguish quark-initiated from gluon-initiated jets. We successfully train the quantum model and evaluate it via numerical simulations. Using this approach, we achieve classification performance almost on par with the one obtained with the completely classical architecture, considering a similar number of parameters.
5/17/2024
NiNformer: A Network in Network Transformer with Token Mixing Generated Gating Function
Abdullah Nazhat Abdullah, Tarkan Aydin
0
0
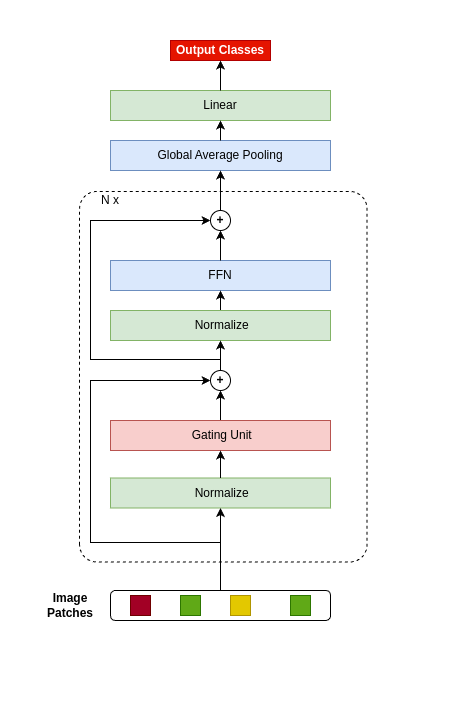
The attention mechanism is the main component of the transformer architecture, and since its introduction, it has led to significant advancements in deep learning that span many domains and multiple tasks. The attention mechanism was utilized in computer vision as the Vision Transformer ViT, and its usage has expanded into many tasks in the vision domain, such as classification, segmentation, object detection, and image generation. While this mechanism is very expressive and capable, it comes with the drawback of being computationally expensive and requiring datasets of considerable size for effective optimization. To address these shortcomings, many designs have been proposed in the literature to reduce the computational burden and alleviate the data size requirements. Examples of such attempts in the vision domain are the MLP-Mixer, the Conv-Mixer, the Perciver-IO, and many more. This paper introduces a new computational block as an alternative to the standard ViT block that reduces the compute burdens by replacing the normal attention layers with a Network in Network structure that enhances the static approach of the MLP-Mixer with a dynamic system of learning an element-wise gating function by a token mixing process. Extensive experimentation shows that the proposed design provides better performance than the baseline architectures on multiple datasets applied in the image classification task of the vision domain.
6/17/2024

Breaking the Attention Bottleneck
Kalle Hilsenbek
0
0
Attention-based transformers have become the standard architecture in many deep learning fields, primarily due to their ability to model long-range dependencies and handle variable-length input sequences. However, the attention mechanism with its quadratic complexity is a significant bottleneck in the transformer architecture. This algorithm is only uni-directional in the decoder and converges to a static pattern in over-parametrized decoder-only models. I address this issue by developing a generative function as attention or activation replacement. It still has the auto-regressive character by comparing each token with the previous one. In my test setting with nanoGPT this yields a smaller loss while having a smaller model. The loss further drops by incorporating an average context vector. This concept of attention replacement is distributed under the GNU AGPL v3 license at https://gitlab.com/Bachstelze/causal_generation.
6/18/2024
Expanded Gating Ranges Improve Activation Functions
Allen Hao Huang
0
0
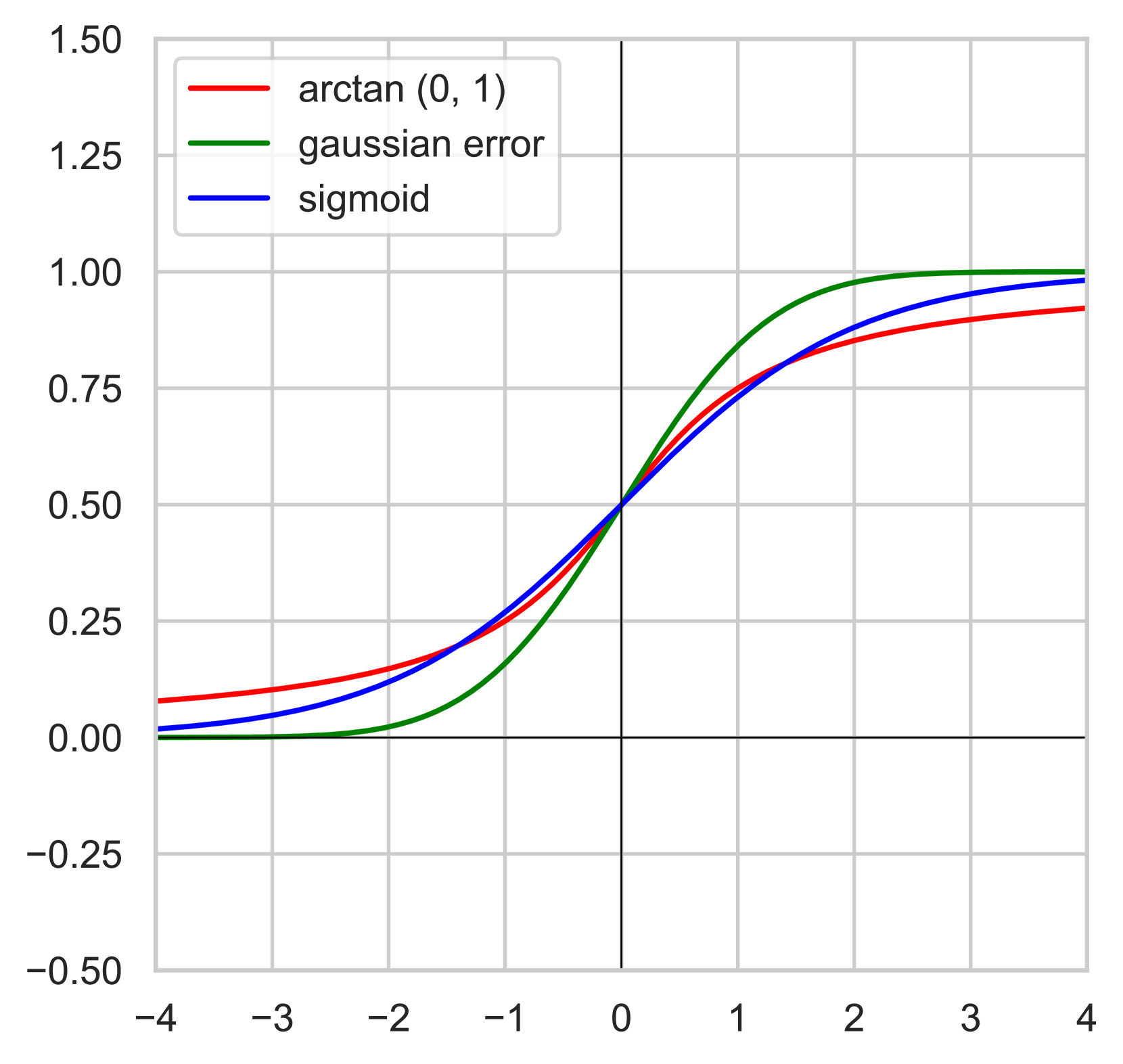
Activation functions are core components of all deep learning architectures. Currently, the most popular activation functions are smooth ReLU variants like GELU and SiLU. These are self-gated activation functions where the range of the gating function is between zero and one. In this paper, we explore the viability of using arctan as a gating mechanism. A self-gated activation function that uses arctan as its gating function has a monotonically increasing first derivative. To make this activation function competitive, it is necessary to introduce a trainable parameter for every MLP block to expand the range of the gating function beyond zero and one. We find that this technique also improves existing self-gated activation functions. We conduct an empirical evaluation of Expanded ArcTan Linear Unit (xATLU), Expanded GELU (xGELU), and Expanded SiLU (xSiLU) and show that they outperform existing activation functions within a transformer architecture. Additionally, expanded gating ranges show promising results in improving first-order Gated Linear Units (GLU).
6/3/2024