Breaking the Attention Bottleneck
2406.10906
0
0

Abstract
Attention-based transformers have become the standard architecture in many deep learning fields, primarily due to their ability to model long-range dependencies and handle variable-length input sequences. However, the attention mechanism with its quadratic complexity is a significant bottleneck in the transformer architecture. This algorithm is only uni-directional in the decoder and converges to a static pattern in over-parametrized decoder-only models. I address this issue by developing a generative function as attention or activation replacement. It still has the auto-regressive character by comparing each token with the previous one. In my test setting with nanoGPT this yields a smaller loss while having a smaller model. The loss further drops by incorporating an average context vector. This concept of attention replacement is distributed under the GNU AGPL v3 license at https://gitlab.com/Bachstelze/causal_generation.
Create account to get full access
Overview
- This paper explores a new attention mechanism called "Lean Attention" that aims to improve the efficiency and scalability of attention-based models.
- The authors propose several techniques to reduce the computational cost and memory footprint of attention, including Lean Attention, Attention as RNN, and Block Transformer.
- The paper presents experiments on various language modeling tasks to demonstrate the advantages of the proposed Lean Attention approach over standard attention mechanisms.
Plain English Explanation
Attention is a crucial component in many state-of-the-art machine learning models, particularly in areas like natural language processing and computer vision. However, the computational and memory requirements of attention can be quite high, which can limit the scalability and efficiency of these models.
The researchers in this paper set out to address this challenge by developing a new attention mechanism called "Lean Attention." The key idea behind Lean Attention is to find ways to reduce the amount of computation and memory needed for attention, without significantly compromising the model's performance.
To achieve this, the researchers propose several techniques, including Lean Attention, which uses a simplified attention calculation, Attention as RNN, which treats attention as a recurrent neural network, and Block Transformer, which divides the input into blocks and applies attention locally within each block.
By incorporating these techniques, the researchers were able to demonstrate that their Lean Attention approach can achieve comparable or even better performance than standard attention mechanisms, while using significantly less computational resources. This could have important implications for deploying attention-based models in real-world applications, especially on devices with limited computing power, such as smartphones or embedded systems.
Technical Explanation
The key innovation in this paper is the Lean Attention mechanism, which aims to reduce the computational and memory requirements of attention without sacrificing model performance.
The standard attention mechanism used in many transformer-based models involves computing a weighted sum of all the input elements, where the weights are determined by a series of matrix multiplications. This can be computationally expensive, especially for long input sequences.
To address this, the researchers propose several techniques:
-
Lean Attention: This simplifies the attention calculation by using a single matrix multiplication instead of the standard multi-step process. The authors show that this can achieve similar performance to standard attention while being more efficient.
-
Attention as RNN: Here, the attention mechanism is treated as a recurrent neural network, which allows for more efficient computation and can be easily integrated into existing RNN-based models.
-
Block Transformer: This divides the input into smaller blocks and applies attention locally within each block, rather than globally across the entire input. This reduces the computational complexity and can be particularly effective for long input sequences.
The researchers evaluate their Lean Attention approach on a variety of language modeling tasks, including small-E small, a lightweight language model that uses linear attention, and NInformer, a transformer-based model with a novel token mixing mechanism. They demonstrate that Lean Attention can achieve comparable or even better performance than standard attention, while using significantly less computational resources.
Critical Analysis
The researchers have made a compelling case for the importance of improving the efficiency of attention-based models, and the Lean Attention approach appears to be a promising step in that direction. The techniques they propose, such as simplified attention calculations and block-based attention, are both theoretically sound and empirically validated through the experiments.
One potential limitation of the work is that the evaluations are primarily focused on language modeling tasks, and it would be valuable to see how the Lean Attention approach performs on a wider range of applications, such as computer vision or other domains where attention-based models are commonly used.
Additionally, while the paper provides a thorough technical explanation of the Lean Attention mechanism and its various components, the practical implications for real-world deployment could be explored in more depth. For example, it would be interesting to see an analysis of the trade-offs between model performance, inference latency, and energy consumption on different hardware platforms.
Overall, this paper represents an important contribution to the ongoing effort to make attention-based models more efficient and scalable. The Lean Attention techniques introduced here could have significant implications for the future development of high-performance, resource-constrained machine learning applications.
Conclusion
This paper presents a novel attention mechanism called "Lean Attention" that aims to improve the efficiency and scalability of attention-based models. The key innovations include simplified attention calculations, treating attention as a recurrent neural network, and applying attention locally within blocks of the input.
Through experiments on various language modeling tasks, the researchers demonstrate that the Lean Attention approach can achieve comparable or even better performance than standard attention mechanisms, while using significantly less computational and memory resources. This could have important implications for deploying attention-based models in real-world applications, particularly on resource-constrained devices.
The Lean Attention techniques introduced in this paper represent an important step forward in the ongoing effort to make attention-based models more efficient and scalable. As machine learning continues to be applied to an ever-wider range of applications, innovations like this will be crucial for enabling the widespread deployment of powerful AI systems in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
0
0
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
5/20/2024
✅
Attention as an RNN
Leo Feng, Frederick Tung, Hossein Hajimirsadeghi, Mohamed Osama Ahmed, Yoshua Bengio, Greg Mori
0
0
The advent of Transformers marked a significant breakthrough in sequence modelling, providing a highly performant architecture capable of leveraging GPU parallelism. However, Transformers are computationally expensive at inference time, limiting their applications, particularly in low-resource settings (e.g., mobile and embedded devices). Addressing this, we (1) begin by showing that attention can be viewed as a special Recurrent Neural Network (RNN) with the ability to compute its textit{many-to-one} RNN output efficiently. We then (2) show that popular attention-based models such as Transformers can be viewed as RNN variants. However, unlike traditional RNNs (e.g., LSTMs), these models cannot be updated efficiently with new tokens, an important property in sequence modelling. Tackling this, we (3) introduce a new efficient method of computing attention's textit{many-to-many} RNN output based on the parallel prefix scan algorithm. Building on the new attention formulation, we (4) introduce textbf{Aaren}, an attention-based module that can not only (i) be trained in parallel (like Transformers) but also (ii) be updated efficiently with new tokens, requiring only constant memory for inferences (like traditional RNNs). Empirically, we show Aarens achieve comparable performance to Transformers on $38$ datasets spread across four popular sequential problem settings: reinforcement learning, event forecasting, time series classification, and time series forecasting tasks while being more time and memory-efficient.
5/29/2024
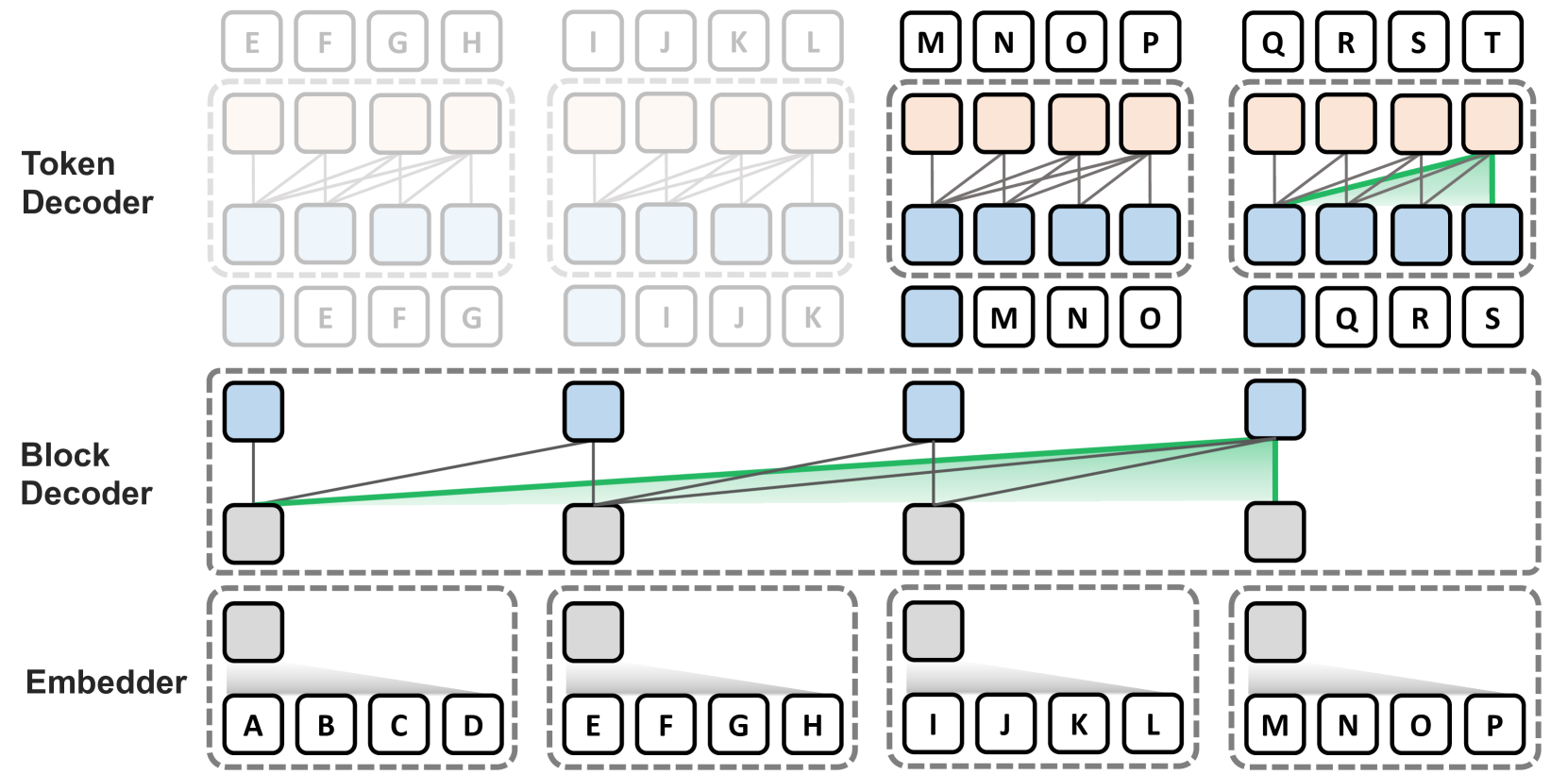
Block Transformer: Global-to-Local Language Modeling for Fast Inference
Namgyu Ho, Sangmin Bae, Taehyeon Kim, Hyunjik Jo, Yireun Kim, Tal Schuster, Adam Fisch, James Thorne, Se-Young Yun
0
0
This paper presents the Block Transformer architecture which adopts hierarchical global-to-local modeling to autoregressive transformers to mitigate the inference bottlenecks of self-attention. To apply self-attention, the key-value (KV) cache of all previous sequences must be retrieved from memory at every decoding step. Thereby, this KV cache IO becomes a significant bottleneck in batch inference. We notice that these costs stem from applying self-attention on the global context, therefore we isolate the expensive bottlenecks of global modeling to lower layers and apply fast local modeling in upper layers. To mitigate the remaining costs in the lower layers, we aggregate input tokens into fixed size blocks and then apply self-attention at this coarse level. Context information is aggregated into a single embedding to enable upper layers to decode the next block of tokens, without global attention. Free of global attention bottlenecks, the upper layers can fully utilize the compute hardware to maximize inference throughput. By leveraging global and local modules, the Block Transformer architecture demonstrates 10-20x gains in inference throughput compared to vanilla transformers with equivalent perplexity. Our work introduces a new approach to optimize language model inference through novel application of global-to-local modeling. Code is available at https://github.com/itsnamgyu/block-transformer.
6/6/2024

Small-E: Small Language Model with Linear Attention for Efficient Speech Synthesis
Th'eodor Lemerle, Nicolas Obin, Axel Roebel
0
0
Recent advancements in text-to-speech (TTS) powered by language models have showcased remarkable capabilities in achieving naturalness and zero-shot voice cloning. Notably, the decoder-only transformer is the prominent architecture in this domain. However, transformers face challenges stemming from their quadratic complexity in sequence length, impeding training on lengthy sequences and resource-constrained hardware. Moreover they lack specific inductive bias with regards to the monotonic nature of TTS alignments. In response, we propose to replace transformers with emerging recurrent architectures and introduce specialized cross-attention mechanisms for reducing repeating and skipping issues. Consequently our architecture can be efficiently trained on long samples and achieve state-of-the-art zero-shot voice cloning against baselines of comparable size. Our implementation and demos are available at https://github.com/theodorblackbird/lina-speech.
6/12/2024