Quantum Vision Transformers for Quark-Gluon Classification
2405.10284
0
0

Abstract
We introduce a hybrid quantum-classical vision transformer architecture, notable for its integration of variational quantum circuits within both the attention mechanism and the multi-layer perceptrons. The research addresses the critical challenge of computational efficiency and resource constraints in analyzing data from the upcoming High Luminosity Large Hadron Collider, presenting the architecture as a potential solution. In particular, we evaluate our method by applying the model to multi-detector jet images from CMS Open Data. The goal is to distinguish quark-initiated from gluon-initiated jets. We successfully train the quantum model and evaluate it via numerical simulations. Using this approach, we achieve classification performance almost on par with the one obtained with the completely classical architecture, considering a similar number of parameters.
Create account to get full access
Overview
- Introduces a novel approach to quantum convolutional neural networks (QCNNs) for multi-class classification tasks
- Explores the use of hybrid quantum-classical transfer learning to enhance the performance of QCNNs
- Provides a comprehensive analysis of model quantization techniques for accelerating Vision Transformers on hardware
- Introduces the Camera-LiDAR Fusion Transformer (CLFT) for semantic segmentation in autonomous driving
- Compares the efficiency and performance of various Transformer architectures for different applications
Plain English Explanation
This research covers several exciting advancements in the field of machine learning and artificial intelligence. The Multi-Class Quantum Convolutional Neural Networks paper introduces a new way of using quantum computers to solve complex classification problems. By combining the power of quantum computing with traditional neural networks, the researchers were able to create more accurate and efficient models.
The Expanding the Horizon: Enabling Hybrid Quantum Transfer Learning work explores how to use transfer learning techniques to quickly adapt these quantum models to new tasks, without having to train them from scratch. This can save a lot of time and computing resources.
The Model Quantization for Hardware Acceleration of Vision Transformers: A Comprehensive Study paper looks at ways to make powerful AI models, like Vision Transformers, run faster on real-world hardware. By compressing the models, they can be deployed on devices with limited computing power, like smartphones or self-driving car computers.
The CLFT: Camera-LiDAR Fusion Transformer for Semantic Segmentation introduces a new way to combine data from cameras and laser scanners (LiDAR) to help self-driving cars understand their surroundings better. This fusion of sensor data can lead to more reliable and safer autonomous driving.
Finally, the Which Transformer to Favor? A Comparative Analysis of Efficiency paper provides a detailed comparison of different Transformer architectures, helping researchers and engineers choose the best model for their specific needs and applications.
Technical Explanation
The Multi-Class Quantum Convolutional Neural Networks paper introduces a novel quantum-classical hybrid approach for multi-class classification tasks. The authors propose a QCNN architecture that leverages quantum convolutional layers to extract features from input data, followed by classical fully connected layers for classification. They demonstrate the effectiveness of their QCNN model on several benchmark datasets, showing improved performance compared to classical CNNs.
The Expanding the Horizon: Enabling Hybrid Quantum Transfer Learning work explores the use of hybrid quantum-classical transfer learning to enhance the performance of QCNNs. By pre-training the quantum layers on a related task and fine-tuning the classical layers on the target task, the researchers were able to achieve higher accuracy with fewer training samples.
The Model Quantization for Hardware Acceleration of Vision Transformers: A Comprehensive Study paper presents a thorough investigation of various model quantization techniques to accelerate Vision Transformers on hardware. The authors evaluate the impact of different quantization methods, precision levels, and hardware platforms on the performance and efficiency of Vision Transformers, providing valuable insights for deploying these models on resource-constrained devices.
The CLFT: Camera-LiDAR Fusion Transformer for Semantic Segmentation introduces the Camera-LiDAR Fusion Transformer (CLFT), a novel architecture that leverages the complementary information from camera and LiDAR sensors for semantic segmentation in autonomous driving. The CLFT model utilizes a Transformer-based fusion mechanism to effectively integrate the multi-modal sensor data, leading to improved segmentation performance compared to previous sensor fusion approaches.
The Which Transformer to Favor? A Comparative Analysis of Efficiency paper provides a comprehensive analysis of the efficiency and performance trade-offs of various Transformer architectures, including the original Transformer, the Vision Transformer, and the Swin Transformer. The authors evaluate these models across different tasks and datasets, offering guidance on selecting the most appropriate Transformer model for specific applications.
Critical Analysis
The research presented in these papers addresses important challenges and opportunities in the field of machine learning and AI. The Multi-Class Quantum Convolutional Neural Networks paper demonstrates the potential of quantum computing to enhance the performance of traditional neural networks, but the authors acknowledge the limited availability and accessibility of quantum hardware, which may hinder the widespread adoption of their approach.
The Expanding the Horizon: Enabling Hybrid Quantum Transfer Learning work highlights the benefits of transfer learning in the context of QCNNs, but the authors note that the efficacy of this approach may depend on the similarity between the source and target tasks, as well as the availability of suitable pre-trained models.
The Model Quantization for Hardware Acceleration of Vision Transformers: A Comprehensive Study paper provides valuable insights into the trade-offs between model performance and hardware efficiency, but the specific quantization techniques and hardware platforms evaluated may need to be updated as the field continues to evolve.
The CLFT: Camera-LiDAR Fusion Transformer for Semantic Segmentation presents an innovative approach to sensor fusion for autonomous driving, but the authors acknowledge the need for further evaluation on larger and more diverse datasets to validate the generalizability of their CLFT model.
The Which Transformer to Favor? A Comparative Analysis of Efficiency paper offers a comprehensive comparison of Transformer architectures, but the authors note that the efficiency and performance of these models may vary depending on the specific hardware and software environments in which they are deployed.
Overall, these research papers make valuable contributions to the field of AI and machine learning, but as with any scientific research, there are always opportunities for further exploration, refinement, and validation of the proposed techniques and findings.
Conclusion
This series of research papers showcases several exciting advancements in the fields of quantum computing, model optimization, sensor fusion, and Transformer architectures. The Multi-Class Quantum Convolutional Neural Networks and Expanding the Horizon: Enabling Hybrid Quantum Transfer Learning papers demonstrate the potential of quantum computing to enhance the performance of traditional machine learning models, while the Model Quantization for Hardware Acceleration of Vision Transformers: A Comprehensive Study and CLFT: Camera-LiDAR Fusion Transformer for Semantic Segmentation papers address the challenges of deploying powerful AI models on real-world hardware and sensors.
The Which Transformer to Favor? A Comparative Analysis of Efficiency paper provides a valuable resource for researchers and engineers, helping them navigate the increasingly diverse landscape of Transformer architectures and select the most appropriate model for their specific applications.
Together, these papers showcase the rapid advancements and emerging trends in the world of machine learning and AI, offering insights that can drive innovation and shape the future of technology in fields ranging from autonomous vehicles to healthcare and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
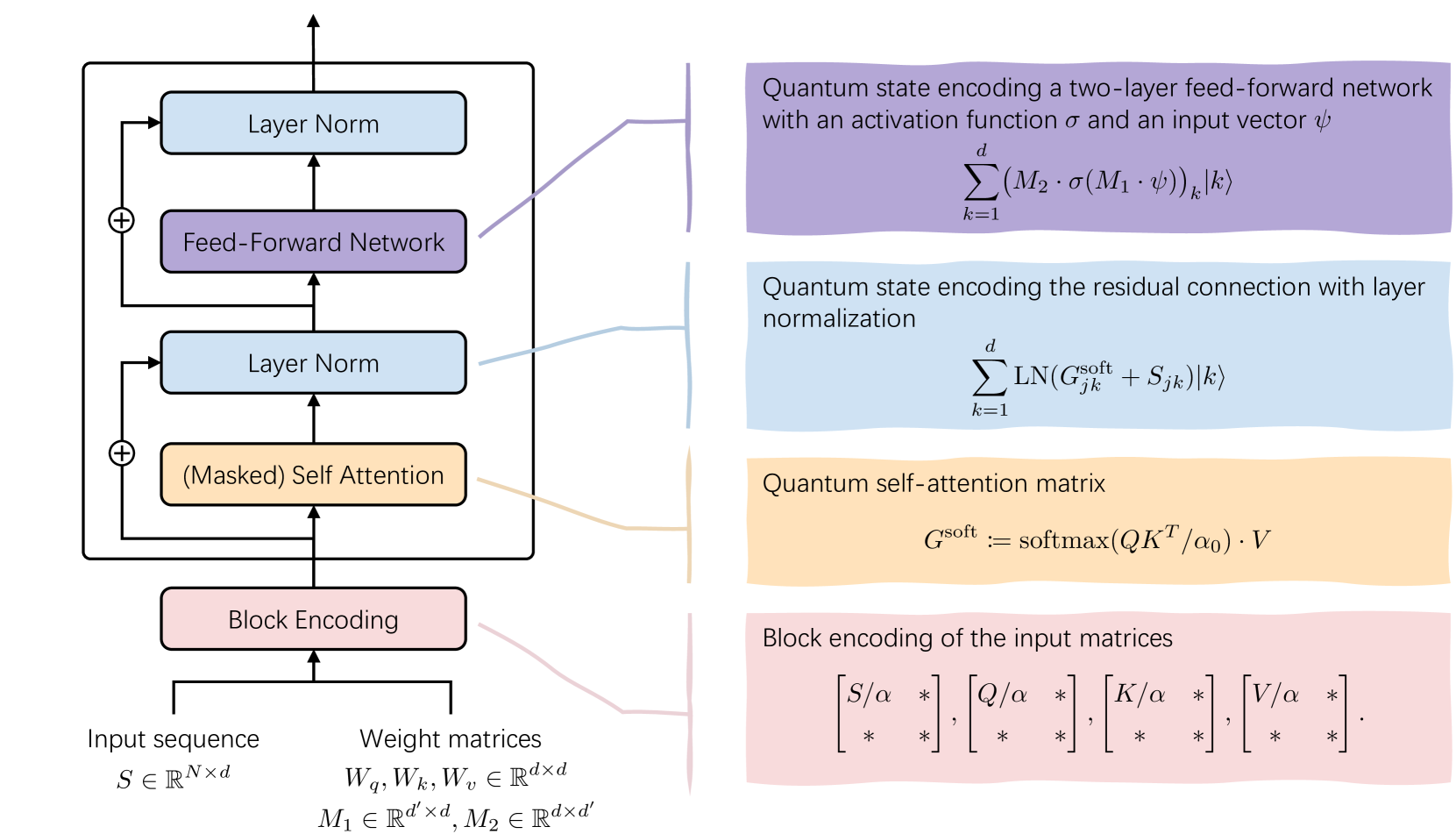
Quantum linear algebra is all you need for Transformer architectures
Naixu Guo, Zhan Yu, Matthew Choi, Aman Agrawal, Kouhei Nakaji, Al'an Aspuru-Guzik, Patrick Rebentrost
0
0
Generative machine learning methods such as large-language models are revolutionizing the creation of text and images. While these models are powerful they also harness a large amount of computational resources. The transformer is a key component in large language models that aims to generate a suitable completion of a given partial sequence. In this work, we investigate transformer architectures under the lens of fault-tolerant quantum computing. The input model is one where trained weight matrices are given as block encodings and we construct the query, key, and value matrices for the transformer. We show how to prepare a block encoding of the self-attention matrix, with a new subroutine for the row-wise application of the softmax function. In addition, we combine quantum subroutines to construct important building blocks in the transformer, the residual connection and layer normalization, and the feed-forward neural network. Our subroutines prepare an amplitude encoding of the transformer output, which can be measured to obtain a prediction. Based on common open-source large-language models, we provide insights into the behavior of important parameters determining the run time of the quantum algorithm. We discuss the potential and challenges for obtaining a quantum advantage.
6/3/2024

QClusformer: A Quantum Transformer-based Framework for Unsupervised Visual Clustering
Xuan-Bac Nguyen, Hoang-Quan Nguyen, Samuel Yen-Chi Chen, Samee U. Khan, Hugh Churchill, Khoa Luu
0
0
Unsupervised vision clustering, a cornerstone in computer vision, has been studied for decades, yielding significant outcomes across numerous vision tasks. However, these algorithms involve substantial computational demands when confronted with vast amounts of unlabeled data. Conversely, Quantum computing holds promise in expediting unsupervised algorithms when handling large-scale databases. In this study, we introduce QClusformer, a pioneering Transformer-based framework leveraging Quantum machines to tackle unsupervised vision clustering challenges. Specifically, we design the Transformer architecture, including the self-attention module and transformer blocks, from a Quantum perspective to enable execution on Quantum hardware. In addition, we present QClusformer, a variant based on the Transformer architecture, tailored for unsupervised vision clustering tasks. By integrating these elements into an end-to-end framework, QClusformer consistently outperforms previous methods running on classical computers. Empirical evaluations across diverse benchmarks, including MS-Celeb-1M and DeepFashion, underscore the superior performance of QClusformer compared to state-of-the-art methods.
5/31/2024
🔄
Classical-to-Quantum Transfer Learning Facilitates Machine Learning with Variational Quantum Circuit
Jun Qi, Chao-Han Huck Yang, Pin-Yu Chen, Min-Hsiu Hsieh, Hector Zenil, Jesper Tegner
0
0
While Quantum Machine Learning (QML) is an exciting emerging area, the accuracy of the loss function still needs to be improved by the number of available qubits. Here, we reformulate the QML problem such that the approximation error (representation power) does not depend on the number of qubits. We prove that a classical-to-quantum transfer learning architecture using a Variational Quantum Circuit (VQC) improves the representation and generalization (estimation error) capabilities of the VQC model. We derive analytical bounds for the approximation and estimation error. We show that the architecture of classical-to-quantum transfer learning leverages pre-trained classical generative AI models, making it easier to find the optimal parameters for the VQC in the training stage. To validate our theoretical analysis, we perform experiments on single-dot and double-dot binary classification tasks for charge stability diagrams in semiconductor quantum dots, where the related empirical results support our theoretical findings. Our analytical and empirical results demonstrate the effectiveness of classical-to-quantum transfer learning architecture in realistic tasks. This sets the stage for accelerating QML applications beyond the current limits of available qubits.
6/24/2024
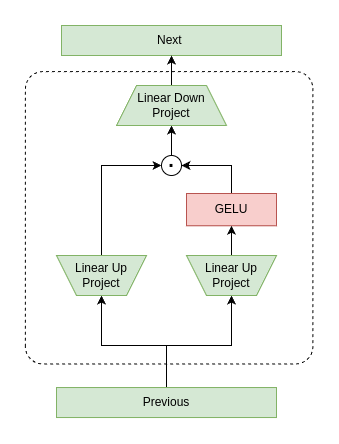
Activator: GLU Activations as The Core Functions of a Vision Transformer
Abdullah Nazhat Abdullah, Tarkan Aydin
0
0
Transformer architecture currently represents the main driver behind many successes in a variety of tasks addressed by deep learning, especially the recent advances in natural language processing (NLP) culminating with large language models (LLM). In addition, transformer architecture has found a wide spread of interest from computer vision (CV) researchers and practitioners, allowing for many advancements in vision-related tasks and opening the door for multi-task and multi-modal deep learning architectures that share the same principle of operation. One drawback to these architectures is their reliance on the scaled dot product attention mechanism with the softmax activation function, which is computationally expensive and requires large compute capabilities both for training and inference. This paper investigates substituting the attention mechanism usually adopted for transformer architecture with an architecture incorporating gated linear unit (GLU) activation within a multi-layer perceptron (MLP) structure in conjunction with the default MLP incorporated in the traditional transformer design. Another step forward taken by this paper is to eliminate the second non-gated MLP to further reduce the computational cost. Experimental assessments conducted by this research show that both proposed modifications and reductions offer competitive performance in relation to baseline architectures, in support of the aims of this work in establishing a more efficient yet capable alternative to the traditional attention mechanism as the core component in designing transformer architectures.
5/28/2024