Active Label Correction for Building LLM-based Modular AI Systems
2401.05467
0
0
🤖
Abstract
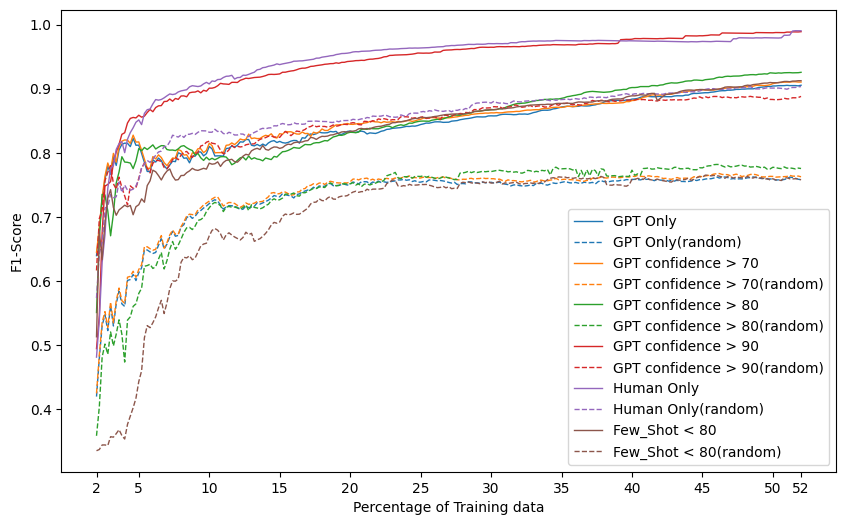
Large Language Models (LLMs) have been used to build modular AI systems such as HuggingGPT, Microsoft Bing Chat, and more. To improve such systems after deployment using the data collected from human interactions, each module can be replaced by a fine-tuned model but the annotations received from LLMs are low quality. We propose that active label correction can be used to improve the data quality by only examining a fraction of the dataset. In this paper, we analyze the noise in datasets annotated by ChatGPT and study denoising it with human feedback. Our results show that active label correction can lead to oracle performance with feedback on fewer examples than the number of noisy examples in the dataset across three different NLP tasks.
Create account to get full access
Overview
- This paper presents a novel approach for building modular AI agents using zero-shot learners, a technique called "machine teaching."
- The method involves training a large language model (LLM) on a diverse set of tasks, then using that model to rapidly teach specialized AI agents how to perform new tasks.
- The authors demonstrate the effectiveness of this approach on several benchmark tasks, showing that the machine-taught agents can match or outperform agents trained from scratch.
Plain English Explanation
The researchers have developed a new way to create modular AI systems that can quickly learn and perform a variety of tasks. They start with a powerful large language model that has been trained on a wide range of information. This model acts as a "teacher" that can rapidly impart its knowledge to specialized AI "agents" that are tailored for specific tasks.
The process works like this: first, the researchers train the large language model to be a knowledgeable "teacher." Then, when they want the AI system to learn a new task, they use the teacher model to "teach" a specialized agent how to do it, rather than training the agent from scratch. This "machine teaching" approach allows the agents to learn new skills much more quickly than traditional methods.
The key insight is that the large, versatile language model can capture a wealth of general knowledge and skills, which it can then efficiently transfer to more specialized agents. This modular design allows the AI system to be highly capable across many different domains, while keeping the individual agents relatively simple and efficient.
Technical Explanation
The core of this approach is the use of zero-shot learning to rapidly teach specialized agents new tasks. The authors start by training a large language model (LLM) on a diverse dataset covering a wide range of knowledge and skills. This LLM serves as the "teacher" in their machine teaching framework.
To train a new agent for a specific task, the researchers provide the LLM teacher with a description of the task, along with any necessary input data. The LLM then generates a set of instructions that the agent can use to perform the task. This zero-shot learning approach allows the agent to acquire new capabilities without requiring full retraining from scratch.
The authors evaluate their machine teaching approach on several benchmark tasks, including ATIS for natural language understanding and CoNLL 2003 for named entity recognition. They show that the machine-taught agents are able to match or outperform agents trained using traditional methods, while requiring significantly less training time and computational resources.
Critical Analysis
The researchers make a compelling case for the effectiveness of their machine teaching approach, demonstrating strong performance on several challenging benchmark tasks. However, the paper does not address some potential limitations or areas for further research.
One concern is the reliance on a single, large language model as the "teacher." While this model may capture a broad range of knowledge, it could also introduce biases or inconsistencies that get propagated to the specialized agents. The authors do not discuss strategies for mitigating these issues or for verifying the reliability of the knowledge being transferred.
Additionally, the paper focuses on relatively narrow, well-defined tasks. It remains to be seen how well the machine teaching approach would scale to more open-ended, real-world problems that require more sophisticated reasoning and problem-solving skills. Further research may be needed to explore the limitations of this approach in more complex domains.
Overall, this work represents an exciting step forward in the development of modular and efficient AI systems. By leveraging the power of large language models, the researchers have demonstrated a promising path for building highly capable AI agents that can rapidly adapt to new tasks and environments.
Conclusion
The paper presents a novel "machine teaching" approach for constructing modular AI agents based on zero-shot learning from large language models. This method allows specialized agents to quickly acquire new skills and capabilities by leveraging the broad knowledge and versatility of a pre-trained teacher model.
The authors demonstrate the effectiveness of this approach on several benchmark tasks, showing that the machine-taught agents can match or outperform traditionally trained agents while requiring significantly less time and computational resources. This work represents an important step forward in the development of efficient and adaptable AI systems that can be rapidly deployed across a wide range of applications.
Although the paper does not address all potential limitations, the machine teaching framework shows significant promise as a way to build highly capable AI agents that can flexibly respond to diverse challenges. Further research is needed to explore the scalability and robustness of this approach, but the core ideas presented here could have far-reaching implications for the future of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Enhancing Text Classification through LLM-Driven Active Learning and Human Annotation
Hamidreza Rouzegar, Masoud Makrehchi
0
0
In the context of text classification, the financial burden of annotation exercises for creating training data is a critical issue. Active learning techniques, particularly those rooted in uncertainty sampling, offer a cost-effective solution by pinpointing the most instructive samples for manual annotation. Similarly, Large Language Models (LLMs) such as GPT-3.5 provide an alternative for automated annotation but come with concerns regarding their reliability. This study introduces a novel methodology that integrates human annotators and LLMs within an Active Learning framework. We conducted evaluations on three public datasets. IMDB for sentiment analysis, a Fake News dataset for authenticity discernment, and a Movie Genres dataset for multi-label classification.The proposed framework integrates human annotation with the output of LLMs, depending on the model uncertainty levels. This strategy achieves an optimal balance between cost efficiency and classification performance. The empirical results show a substantial decrease in the costs associated with data annotation while either maintaining or improving model accuracy.
6/19/2024
💬
AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
Xingwei He, Zhenghao Lin, Yeyun Gong, A-Long Jin, Hang Zhang, Chen Lin, Jian Jiao, Siu Ming Yiu, Nan Duan, Weizhu Chen
0
0
Many natural language processing (NLP) tasks rely on labeled data to train machine learning models with high performance. However, data annotation is time-consuming and expensive, especially when the task involves a large amount of data or requires specialized domains. Recently, GPT-3.5 series models have demonstrated remarkable few-shot and zero-shot ability across various NLP tasks. In this paper, we first claim that large language models (LLMs), such as GPT-3.5, can serve as an excellent crowdsourced annotator when provided with sufficient guidance and demonstrated examples. Accordingly, we propose AnnoLLM, an annotation system powered by LLMs, which adopts a two-step approach, explain-then-annotate. Concretely, we first prompt LLMs to provide explanations for why the specific ground truth answer/label was assigned for a given example. Then, we construct the few-shot chain-of-thought prompt with the self-generated explanation and employ it to annotate the unlabeled data with LLMs. Our experiment results on three tasks, including user input and keyword relevance assessment, BoolQ, and WiC, demonstrate that AnnoLLM surpasses or performs on par with crowdsourced annotators. Furthermore, we build the first conversation-based information retrieval dataset employing AnnoLLM. This dataset is designed to facilitate the development of retrieval models capable of retrieving pertinent documents for conversational text. Human evaluation has validated the dataset's high quality.
4/8/2024

LLMs in the Loop: Leveraging Large Language Model Annotations for Active Learning in Low-Resource Languages
Nataliia Kholodna, Sahib Julka, Mohammad Khodadadi, Muhammed Nurullah Gumus, Michael Granitzer
0
0
Low-resource languages face significant barriers in AI development due to limited linguistic resources and expertise for data labeling, rendering them rare and costly. The scarcity of data and the absence of preexisting tools exacerbate these challenges, especially since these languages may not be adequately represented in various NLP datasets. To address this gap, we propose leveraging the potential of LLMs in the active learning loop for data annotation. Initially, we conduct evaluations to assess inter-annotator agreement and consistency, facilitating the selection of a suitable LLM annotator. The chosen annotator is then integrated into a training loop for a classifier using an active learning paradigm, minimizing the amount of queried data required. Empirical evaluations, notably employing GPT-4-Turbo, demonstrate near-state-of-the-art performance with significantly reduced data requirements, as indicated by estimated potential cost savings of at least 42.45 times compared to human annotation. Our proposed solution shows promising potential to substantially reduce both the monetary and computational costs associated with automation in low-resource settings. By bridging the gap between low-resource languages and AI, this approach fosters broader inclusion and shows the potential to enable automation across diverse linguistic landscapes.
6/26/2024
Guiding Large Language Models to Post-Edit Machine Translation with Error Annotations
Dayeon Ki, Marine Carpuat
0
0
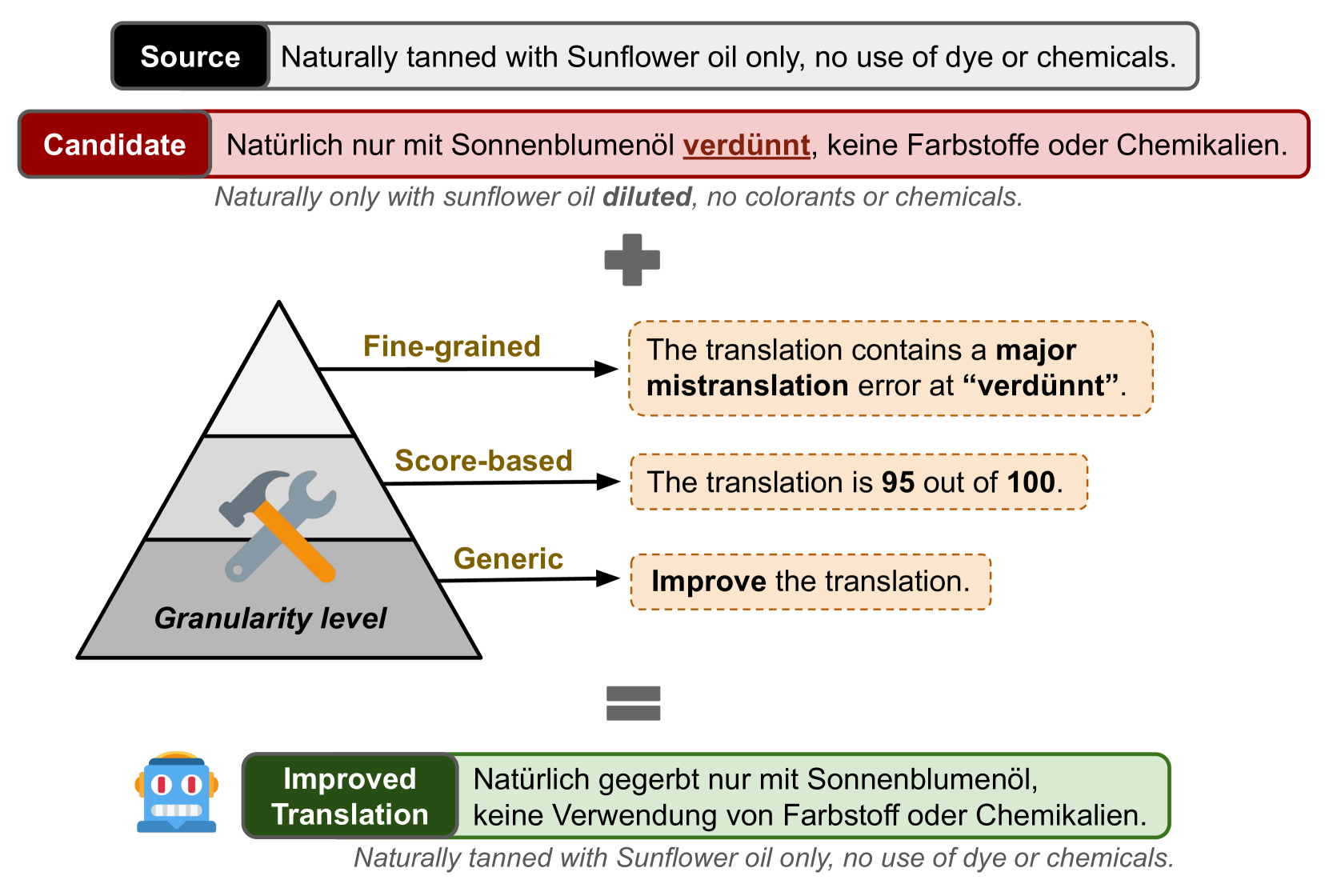
Machine Translation (MT) remains one of the last NLP tasks where large language models (LLMs) have not yet replaced dedicated supervised systems. This work exploits the complementary strengths of LLMs and supervised MT by guiding LLMs to automatically post-edit MT with external feedback on its quality, derived from Multidimensional Quality Metric (MQM) annotations. Working with LLaMA-2 models, we consider prompting strategies varying the nature of feedback provided and then fine-tune the LLM to improve its ability to exploit the provided guidance. Through experiments on Chinese-English, English-German, and English-Russian MQM data, we demonstrate that prompting LLMs to post-edit MT improves TER, BLEU and COMET scores, although the benefits of fine-grained feedback are not clear. Fine-tuning helps integrate fine-grained feedback more effectively and further improves translation quality based on both automatic and human evaluation.
4/12/2024