An Active Learning Framework with a Class Balancing Strategy for Time Series Classification
2405.12122
0
0

Abstract
Training machine learning models for classification tasks often requires labeling numerous samples, which is costly and time-consuming, especially in time series analysis. This research investigates Active Learning (AL) strategies to reduce the amount of labeled data needed for effective time series classification. Traditional AL techniques cannot control the selection of instances per class for labeling, leading to potential bias in classification performance and instance selection, particularly in imbalanced time series datasets. To address this, we propose a novel class-balancing instance selection algorithm integrated with standard AL strategies. Our approach aims to select more instances from classes with fewer labeled examples, thereby addressing imbalance in time series datasets. We demonstrate the effectiveness of our AL framework in selecting informative data samples for two distinct domains of tactile texture recognition and industrial fault detection. In robotics, our method achieves high-performance texture categorization while significantly reducing labeled training data requirements to 70%. We also evaluate the impact of different sliding window time intervals on robotic texture classification using AL strategies. In synthetic fiber manufacturing, we adapt AL techniques to address the challenge of fault classification, aiming to minimize data annotation cost and time for industries. We also address real-life class imbalances in the multiclass industrial anomalous dataset using our class-balancing instance algorithm integrated with AL strategies. Overall, this thesis highlights the potential of our AL framework across these two distinct domains.
Create account to get full access
Overview
- This paper explores the fragility and robustness of active learning algorithms, which are used to train machine learning models with limited labeled data.
- The researchers investigate how various active learning techniques perform under different imbalanced and adversarial data scenarios.
- They propose several new active learning approaches and evaluate their effectiveness through extensive experiments.
Plain English Explanation
Active learning is a technique used in machine learning to train models when there is only a small amount of labeled data available. The idea is to automatically select the most informative unlabeled data points for a human to label, so the model can learn efficiently.
However, this paper reveals that many active learning algorithms are quite fragile - they can perform poorly if the data has certain biases or is adversarially manipulated. For example, if the unlabeled data is imbalanced, meaning there are many more samples of one class than another, standard active learning methods may struggle.
To address this, the researchers propose several new active learning approaches that are more robust to these challenging data scenarios. Their methods aim to actively select a diverse set of data points that represent the full distribution, rather than just focusing on the most informative samples.
Through extensive experiments, the researchers show that their new active learning techniques can outperform existing methods, especially when dealing with imbalanced or adversarial data. This is an important advance, as real-world data is often messy and biased, and we want machine learning models to be able to learn reliably even in the face of such challenges.
Technical Explanation
The paper first reviews existing active learning algorithms, such as uncertainty sampling and diversity-based sampling. It then examines their fragility when the data is imbalanced or adversarially perturbed.
To improve robustness, the researchers propose several new active learning methods:
-
Fragility-Aware Active Learning (FRAL): This technique explicitly models the fragility of the current model and selects samples that are expected to improve its robustness.
-
Anchor-Guided Active Learning (AGAL): This method balances exploration (selecting diverse samples) and exploitation (selecting informative samples) by using anchor points to represent the full data distribution.
-
DirectAL: This deep active learning approach directly optimizes the model's performance on the imbalanced data distribution, rather than just maximizing information gain.
The paper evaluates these new methods on a variety of image classification benchmarks with imbalanced and adversarial data. The results show that the proposed techniques significantly outperform standard active learning algorithms in terms of model accuracy and robustness.
Critical Analysis
The paper makes a valuable contribution by highlighting the fragility of many active learning algorithms and proposing new methods to address this issue. The experimental evaluation is thorough and the results are compelling.
However, one potential limitation is that the paper focuses mainly on image classification tasks. It would be interesting to see how the proposed techniques perform on other types of data and machine learning problems, such as natural language processing or tabular data.
Additionally, the paper does not provide much insight into the computational efficiency of the new active learning methods. In real-world scenarios, the speed and scalability of the algorithms may be an important consideration.
Overall, this research represents an important step forward in making active learning more robust and reliable, which is crucial for deploying machine learning systems in complex, real-world environments.
Conclusion
This paper demonstrates that standard active learning algorithms can be fragile and perform poorly when faced with imbalanced or adversarial data. To address this, the researchers propose several new active learning techniques that explicitly model and improve the robustness of the learning process.
Through extensive experiments, the authors show that their proposed methods, such as Fragility-Aware Active Learning and Anchor-Guided Active Learning, significantly outperform existing approaches in terms of model accuracy and stability. This is an important advance that could enable more reliable and trustworthy machine learning systems, especially in domains with challenging or biased data.
The insights and techniques presented in this paper have the potential to benefit a wide range of applications, from healthcare to finance to autonomous systems. By making active learning more robust, we can unlock the power of machine learning in an increasingly diverse and complex world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

On the Fragility of Active Learners
Abhishek Ghose, Emma Thuong Nguyen
0
0
Active learning (AL) techniques aim to maximally utilize a labeling budget by iteratively selecting instances that are most likely to improve prediction accuracy. However, their benefit compared to random sampling has not been consistent across various setups, e.g., different datasets, classifiers. In this empirical study, we examine how a combination of different factors might obscure any gains from an AL technique. Focusing on text classification, we rigorously evaluate AL techniques over around 1000 experiments that vary wrt the dataset, batch size, text representation and the classifier. We show that AL is only effective in a narrow set of circumstances. We also address the problem of using metrics that are better aligned with real world expectations. The impact of this study is in its insights for a practitioner: (a) the choice of text representation and classifier is as important as that of an AL technique, (b) choice of the right metric is critical in assessment of the latter, and, finally, (c) reported AL results must be holistically interpreted, accounting for variables other than just the query strategy.
4/16/2024

Edge-guided and Class-balanced Active Learning for Semantic Segmentation of Aerial Images
Lianlei Shan, Weiqiang Wang, Ke Lv, Bin Luo
0
0
Semantic segmentation requires pixel-level annotation, which is time-consuming. Active Learning (AL) is a promising method for reducing data annotation costs. Due to the gap between aerial and natural images, the previous AL methods are not ideal, mainly caused by unreasonable labeling units and the neglect of class imbalance. Previous labeling units are based on images or regions, which does not consider the characteristics of segmentation tasks and aerial images, i.e., the segmentation network often makes mistakes in the edge region, and the edge of aerial images is often interlaced and irregular. Therefore, an edge-guided labeling unit is proposed and supplemented as the new unit. On the other hand, the class imbalance is severe, manifested in two aspects: the aerial image is seriously imbalanced, and the AL strategy does not fully consider the class balance. Both seriously affect the performance of AL in aerial images. We comprehensively ensure class balance from all steps that may occur imbalance, including initial labeled data, subsequent labeled data, and pseudo-labels. Through the two improvements, our method achieves more than 11.2% gains compared to state-of-the-art methods on three benchmark datasets, Deepglobe, Potsdam, and Vaihingen, and more than 18.6% gains compared to the baseline. Sufficient ablation studies show that every module is indispensable. Furthermore, we establish a fair and strong benchmark for future research on AL for aerial image segmentation.
5/29/2024
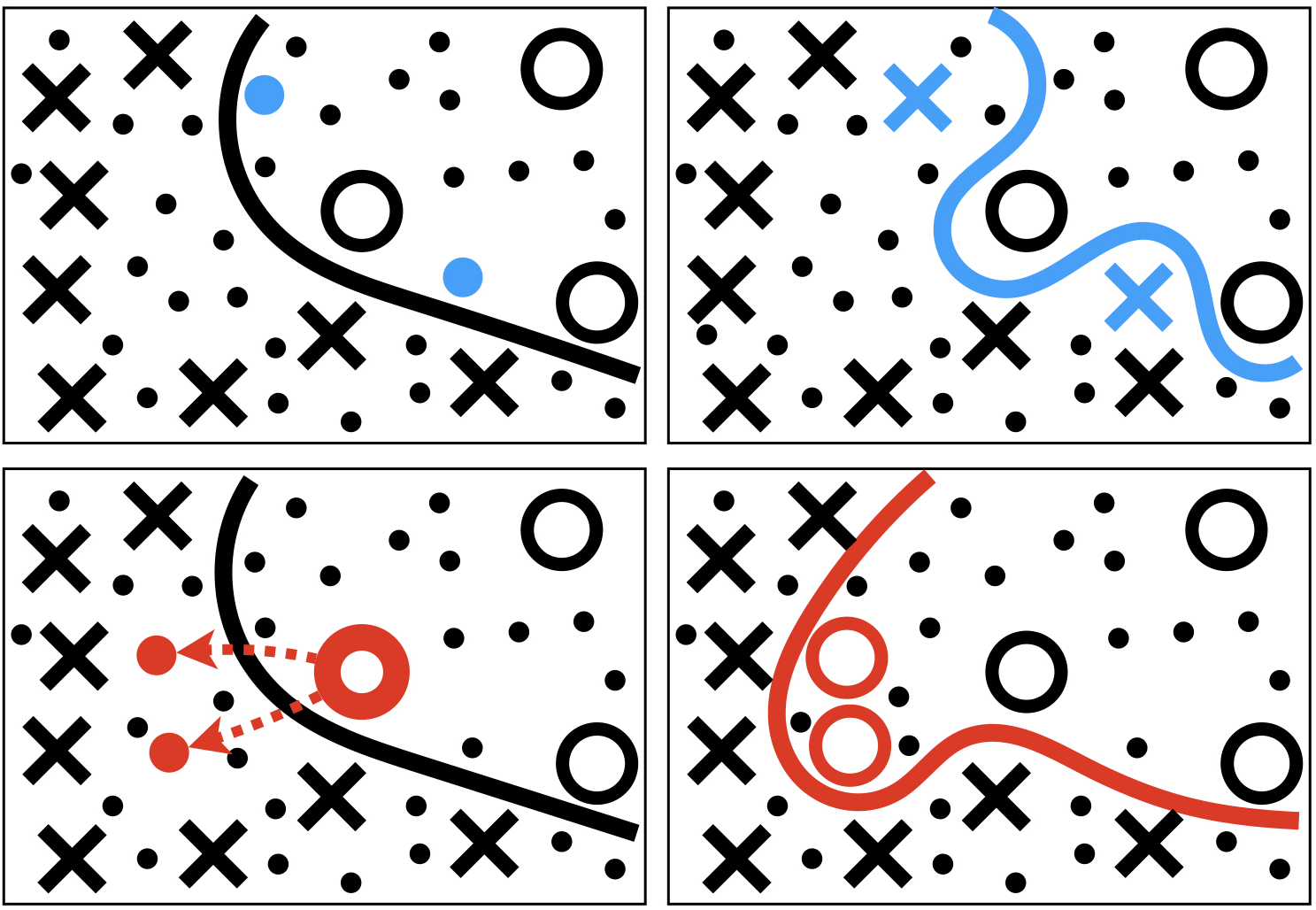
AnchorAL: Computationally Efficient Active Learning for Large and Imbalanced Datasets
Pietro Lesci, Andreas Vlachos
0
0
Active learning for imbalanced classification tasks is challenging as the minority classes naturally occur rarely. Gathering a large pool of unlabelled data is thus essential to capture minority instances. Standard pool-based active learning is computationally expensive on large pools and often reaches low accuracy by overfitting the initial decision boundary, thus failing to explore the input space and find minority instances. To address these issues we propose AnchorAL. At each iteration, AnchorAL chooses class-specific instances from the labelled set, or anchors, and retrieves the most similar unlabelled instances from the pool. This resulting subpool is then used for active learning. Using a small, fixed-sized subpool AnchorAL allows scaling any active learning strategy to large pools. By dynamically selecting different anchors at each iteration it promotes class balance and prevents overfitting the initial decision boundary, thus promoting the discovery of new clusters of minority instances. In experiments across different classification tasks, active learning strategies, and model architectures AnchorAL is (i) faster, often reducing runtime from hours to minutes, (ii) trains more performant models, (iii) and returns more balanced datasets than competing methods.
5/28/2024

Classification Tree-based Active Learning: A Wrapper Approach
Ashna Jose, Emilie Devijver, Massih-Reza Amini, Noel Jakse, Roberta Poloni
0
0
Supervised machine learning often requires large training sets to train accurate models, yet obtaining large amounts of labeled data is not always feasible. Hence, it becomes crucial to explore active learning methods for reducing the size of training sets while maintaining high accuracy. The aim is to select the optimal subset of data for labeling from an initial unlabeled set, ensuring precise prediction of outcomes. However, conventional active learning approaches are comparable to classical random sampling. This paper proposes a wrapper active learning method for classification, organizing the sampling process into a tree structure, that improves state-of-the-art algorithms. A classification tree constructed on an initial set of labeled samples is considered to decompose the space into low-entropy regions. Input-space based criteria are used thereafter to sub-sample from these regions, the total number of points to be labeled being decomposed into each region. This adaptation proves to be a significant enhancement over existing active learning methods. Through experiments conducted on various benchmark data sets, the paper demonstrates the efficacy of the proposed framework by being effective in constructing accurate classification models, even when provided with a severely restricted labeled data set.
4/16/2024