On the Fragility of Active Learners
2403.15744
0
0

Abstract
Active learning (AL) techniques aim to maximally utilize a labeling budget by iteratively selecting instances that are most likely to improve prediction accuracy. However, their benefit compared to random sampling has not been consistent across various setups, e.g., different datasets, classifiers. In this empirical study, we examine how a combination of different factors might obscure any gains from an AL technique. Focusing on text classification, we rigorously evaluate AL techniques over around 1000 experiments that vary wrt the dataset, batch size, text representation and the classifier. We show that AL is only effective in a narrow set of circumstances. We also address the problem of using metrics that are better aligned with real world expectations. The impact of this study is in its insights for a practitioner: (a) the choice of text representation and classifier is as important as that of an AL technique, (b) choice of the right metric is critical in assessment of the latter, and, finally, (c) reported AL results must be holistically interpreted, accounting for variables other than just the query strategy.
Create account to get full access
Overview
- This paper examines the fragility of active learning models, which are used to efficiently annotate large datasets by focusing on the most informative samples.
- The authors investigate several key issues with active learning, including the model's sensitivity to hyperparameters, the impact of dataset imbalance, and the reliability of the uncertainty estimates used to select samples.
- The findings have important implications for the practical application of active learning, especially in domains with complex, real-world data.
Plain English Explanation
Active learning is a machine learning technique that aims to [https://aimodels.fyi/papers/arxiv/anchoral-computationally-efficient-active-learning-large-imbalanced] improve model performance by selectively annotating the most informative samples in a dataset, rather than annotating all samples. This can be especially useful when working with large, complex datasets where manual annotation is time-consuming and expensive.
However, this paper suggests that active learning models can be [https://aimodels.fyi/papers/arxiv/focused-active-learning-histopathological-image-classification] quite fragile and sensitive to various factors, including the choice of hyperparameters, the balance of the dataset, and the reliability of the uncertainty estimates used to select samples for annotation.
The authors found that active learning models can perform [https://aimodels.fyi/papers/arxiv/effectiveness-tree-based-ensembles-anomaly-discovery-insights] well on simple, synthetic datasets, but their performance can degrade significantly when applied to more complex, real-world data. This is a crucial limitation that needs to be addressed for active learning to be widely adopted in practical applications.
The paper highlights the importance of [https://aimodels.fyi/papers/arxiv/active-causal-learning-decoding-chemical-complexities-targeted] carefully evaluating active learning models and understanding their limitations, rather than simply assuming they will provide a reliable and efficient way to annotate large datasets. This is an important consideration for researchers and practitioners working on [https://aimodels.fyi/papers/arxiv/active-learning-efficient-annotation-precision-agriculture-use] real-world machine learning problems.
Technical Explanation
The paper investigates several key issues with batch active learning, a widely used approach for efficiently annotating large datasets. The authors first provide an overview of the batch active learning process, which involves training a model on a small initial dataset, using the model to select the most informative samples from the remaining unlabeled data, annotating those samples, and then retraining the model with the expanded dataset.
The authors then conduct a series of experiments to assess the fragility of active learning models. They examine the models' sensitivity to hyperparameter choices, the impact of dataset imbalance, and the reliability of the uncertainty estimates used to select samples for annotation. The experiments are carried out on both synthetic and real-world datasets, including image classification and natural language processing tasks.
The results show that active learning models can perform well on simple, synthetic datasets, but their performance can degrade significantly when applied to more complex, real-world data. The authors attribute this to the models' [https://aimodels.fyi/papers/arxiv/anchoral-computationally-efficient-active-learning-large-imbalanced] sensitivity to hyperparameters, the impact of dataset imbalance, and the unreliability of the uncertainty estimates used to select samples.
The paper provides a detailed analysis of these issues and offers several potential solutions, such as using ensemble methods to improve the reliability of uncertainty estimates and incorporating dataset balancing techniques into the active learning process. The authors also discuss the implications of their findings for the practical application of active learning in real-world scenarios.
Critical Analysis
The paper provides a valuable and timely investigation into the fragility of active learning models, which is an important issue that has received relatively little attention in the literature. The authors' systematic evaluation of key factors, such as hyperparameter sensitivity and dataset imbalance, offers a comprehensive understanding of the limitations and challenges associated with active learning.
One potential limitation of the study is that the authors focus primarily on batch active learning, which may not be representative of all active learning approaches. It would be interesting to see if the authors' findings extend to other active learning strategies, such as [https://aimodels.fyi/papers/arxiv/focused-active-learning-histopathological-image-classification] query-by-committee or active learning with human-in-the-loop. Additionally, the paper could have delved deeper into the impact of specific dataset characteristics, such as the complexity, noise, or dimensionality of the data, on the performance of active learning models.
Overall, the paper makes a significant contribution to the field by highlighting the fragility of active learning and the need for more robust and reliable methods. The authors' recommendations for addressing these issues, such as the use of ensemble techniques and dataset balancing, provide a valuable starting point for future research and development in this area. Readers are encouraged to [https://aimodels.fyi/papers/arxiv/effectiveness-tree-based-ensembles-anomaly-discovery-insights] think critically about the implications of this research and consider how it might inform their own work on active learning and other machine learning problems.
Conclusion
This paper presents a comprehensive investigation into the fragility of active learning models, which are commonly used to efficiently annotate large datasets by focusing on the most informative samples. The authors' findings suggest that active learning models can be highly sensitive to a variety of factors, including hyperparameter choices, dataset imbalance, and the reliability of the uncertainty estimates used to select samples for annotation.
The implications of this research are significant, as active learning is widely seen as a promising approach for reducing the cost and effort required to annotate large datasets for machine learning tasks. The authors' work highlights the need for more robust and reliable active learning methods, particularly when dealing with complex, real-world data.
Overall, this paper provides valuable insights for researchers and practitioners working on active learning and other machine learning problems. By understanding the limitations and fragility of active learning models, [https://aimodels.fyi/papers/arxiv/active-causal-learning-decoding-chemical-complexities-targeted] they can develop more effective and reliable techniques for efficient data annotation and model training in a variety of applications, from [https://aimodels.fyi/papers/arxiv/active-learning-efficient-annotation-precision-agriculture-use] precision agriculture to medical image analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Active Learning Framework with a Class Balancing Strategy for Time Series Classification
Shemonto Das
0
0
Training machine learning models for classification tasks often requires labeling numerous samples, which is costly and time-consuming, especially in time series analysis. This research investigates Active Learning (AL) strategies to reduce the amount of labeled data needed for effective time series classification. Traditional AL techniques cannot control the selection of instances per class for labeling, leading to potential bias in classification performance and instance selection, particularly in imbalanced time series datasets. To address this, we propose a novel class-balancing instance selection algorithm integrated with standard AL strategies. Our approach aims to select more instances from classes with fewer labeled examples, thereby addressing imbalance in time series datasets. We demonstrate the effectiveness of our AL framework in selecting informative data samples for two distinct domains of tactile texture recognition and industrial fault detection. In robotics, our method achieves high-performance texture categorization while significantly reducing labeled training data requirements to 70%. We also evaluate the impact of different sliding window time intervals on robotic texture classification using AL strategies. In synthetic fiber manufacturing, we adapt AL techniques to address the challenge of fault classification, aiming to minimize data annotation cost and time for industries. We also address real-life class imbalances in the multiclass industrial anomalous dataset using our class-balancing instance algorithm integrated with AL strategies. Overall, this thesis highlights the potential of our AL framework across these two distinct domains.
5/21/2024
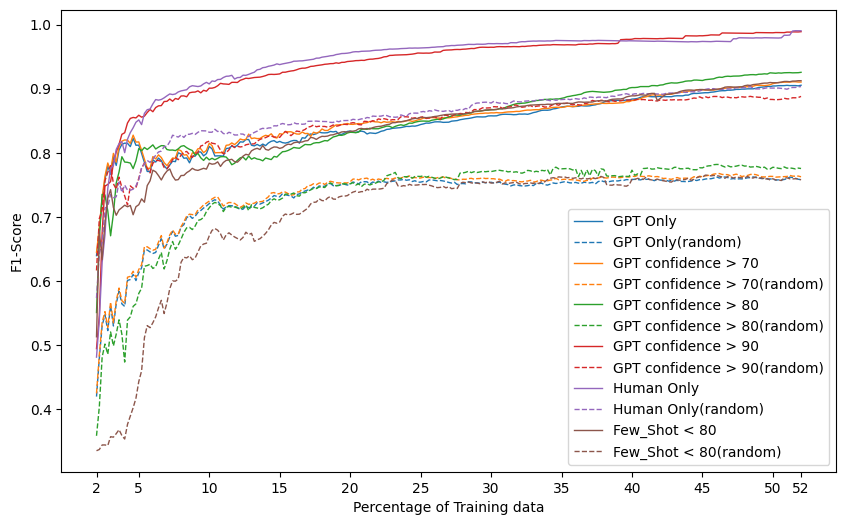
Enhancing Text Classification through LLM-Driven Active Learning and Human Annotation
Hamidreza Rouzegar, Masoud Makrehchi
0
0
In the context of text classification, the financial burden of annotation exercises for creating training data is a critical issue. Active learning techniques, particularly those rooted in uncertainty sampling, offer a cost-effective solution by pinpointing the most instructive samples for manual annotation. Similarly, Large Language Models (LLMs) such as GPT-3.5 provide an alternative for automated annotation but come with concerns regarding their reliability. This study introduces a novel methodology that integrates human annotators and LLMs within an Active Learning framework. We conducted evaluations on three public datasets. IMDB for sentiment analysis, a Fake News dataset for authenticity discernment, and a Movie Genres dataset for multi-label classification.The proposed framework integrates human annotation with the output of LLMs, depending on the model uncertainty levels. This strategy achieves an optimal balance between cost efficiency and classification performance. The empirical results show a substantial decrease in the costs associated with data annotation while either maintaining or improving model accuracy.
6/19/2024
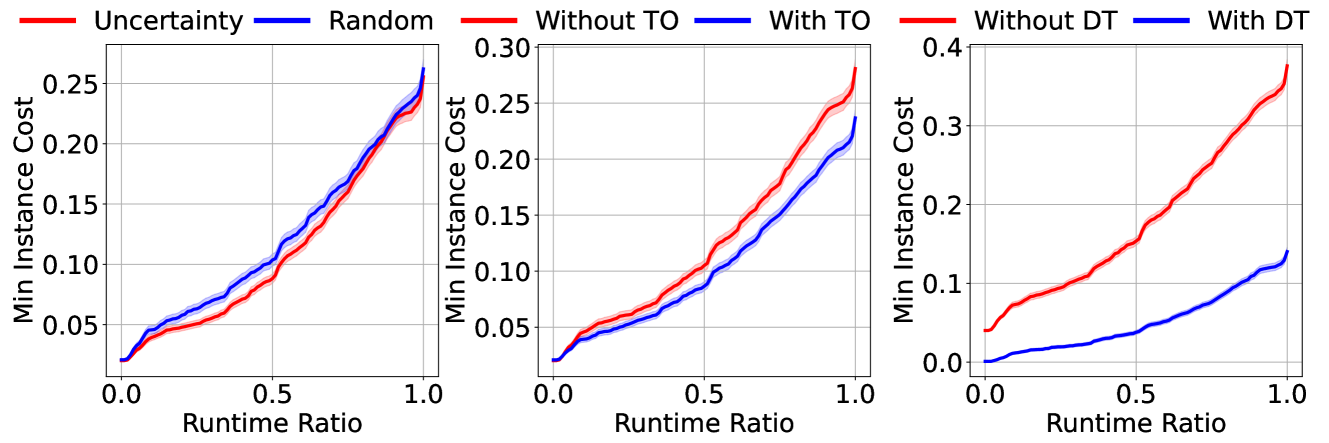
Frugal Algorithm Selection
Erdem Kuc{s}, Ozgur Akgun, Nguyen Dang, Ian Miguel
0
0
When solving decision and optimisation problems, many competing algorithms (model and solver choices) have complementary strengths. Typically, there is no single algorithm that works well for all instances of a problem. Automated algorithm selection has been shown to work very well for choosing a suitable algorithm for a given instance. However, the cost of training can be prohibitively large due to running candidate algorithms on a representative set of training instances. In this work, we explore reducing this cost by choosing a subset of the training instances on which to train. We approach this problem in three ways: using active learning to decide based on prediction uncertainty, augmenting the algorithm predictors with a timeout predictor, and collecting training data using a progressively increasing timeout. We evaluate combinations of these approaches on six datasets from ASLib and present the reduction in labelling cost achieved by each option.
5/21/2024

Self-Training for Sample-Efficient Active Learning for Text Classification with Pre-Trained Language Models
Christopher Schroder, Gerhard Heyer
0
0
Active learning is an iterative labeling process that is used to obtain a small labeled subset, despite the absence of labeled data, thereby enabling to train a model for supervised tasks such as text classification. While active learning has made considerable progress in recent years due to improvements provided by pre-trained language models, there is untapped potential in the often neglected unlabeled portion of the data, although it is available in considerably larger quantities than the usually small set of labeled data. Here we investigate how self-training, a semi-supervised approach where a model is used to obtain pseudo-labels from the unlabeled data, can be used to improve the efficiency of active learning for text classification. Starting with an extensive reproduction of four previous self-training approaches, some of which are evaluated for the first time in the context of active learning or natural language processing, we devise HAST, a new and effective self-training strategy, which is evaluated on four text classification benchmarks, on which it outperforms the reproduced self-training approaches and reaches classification results comparable to previous experiments for three out of four datasets, using only 25% of the data.
6/14/2024