DIRECT: Deep Active Learning under Imbalance and Label Noise
2312.09196
0
0

Abstract
Class imbalance is a prevalent issue in real world machine learning applications, often leading to poor performance in rare and minority classes. With an abundance of wild unlabeled data, active learning is perhaps the most effective technique in solving the problem at its root -- collecting a more balanced and informative set of labeled examples during annotation. Label noise is another common issue in data annotation jobs, which is especially challenging for active learning methods. In this work, we conduct the first study of active learning under both class imbalance and label noise. We propose a novel algorithm that robustly identifies the class separation threshold and annotates the most uncertain examples that are closest from it. Through a novel reduction to one-dimensional active learning, our algorithm DIRECT is able to leverage the classic active learning literature to address issues such as batch labeling and tolerance towards label noise. We present extensive experiments on imbalanced datasets with and without label noise. Our results demonstrate that DIRECT can save more than 60% of the annotation budget compared to state-of-art active learning algorithms and more than 80% of annotation budget compared to random sampling.
Create account to get full access
Overview
- Presents a new deep active learning framework called DIRECT that is designed to handle class imbalance and label noise effectively
- Leverages a representation-guided uncertainty sampling strategy and a novel training scheme that jointly optimizes the model and manages class imbalance
- Demonstrates strong performance on several benchmark datasets compared to state-of-the-art active learning methods
Plain English Explanation
DIRECT is a new deep active learning framework that aims to address two common challenges in machine learning: class imbalance and label noise. Class imbalance occurs when there are significantly more examples of some classes than others, which can cause models to perform poorly on the underrepresented classes. Label noise refers to when the training data has incorrect or unreliable labels, which can also degrade model performance.
To tackle these issues, DIRECT uses a representation-guided uncertainty sampling strategy to select the most informative unlabeled examples for annotation. This helps the model learn more efficiently from the limited labeled data. DIRECT also employs a novel training scheme that jointly optimizes the model and manages the class imbalance, similar to the active label correction approach.
The key idea is to balance the training process and ensure the model learns effectively from both the majority and minority classes, even in the presence of noisy labels. This allows DIRECT to outperform other state-of-the-art active learning methods on several benchmark datasets, as demonstrated in the paper.
Technical Explanation
DIRECT uses a representation-guided uncertainty sampling strategy to select informative unlabeled examples for annotation. This involves training a deep neural network model and using its internal representations to identify the most uncertain and potentially "flip-flop" samples - those that the model is least confident about and may change its prediction on with additional training.
The paper also introduces a novel training scheme that jointly optimizes the model and manages class imbalance. This is similar to the active label correction approach, where the model is trained to not only learn the task but also to identify and correct potentially noisy labels.
Specifically, DIRECT uses a combination of cross-entropy loss and a class-balanced loss function to ensure the model learns effectively from both majority and minority classes, even in the presence of label noise. This helps address the class imbalance and label noise challenges that often arise in real-world datasets.
The paper evaluates DIRECT on several benchmark datasets and shows that it outperforms other state-of-the-art active learning methods, including CorSet and ALBypass. This demonstrates the effectiveness of DIRECT's representation-guided uncertainty sampling and joint optimization approach in handling class imbalance and label noise.
Critical Analysis
The paper provides a comprehensive evaluation of DIRECT on several datasets, but it would be useful to see how it performs on a wider range of tasks and dataset characteristics. The authors mention that DIRECT is designed to work well with both class imbalance and label noise, but it would be valuable to understand the relative importance of these two factors and how DIRECT's performance scales as the degree of imbalance or noise increases.
Additionally, the paper does not provide much insight into the computational efficiency of DIRECT compared to other active learning methods. As active learning can be computationally intensive, especially when dealing with large datasets, understanding the time and resource requirements of DIRECT would be important for real-world applications.
Overall, the paper presents a promising new active learning framework that addresses two critical challenges in machine learning. Further research and evaluation on a broader range of settings could help solidify DIRECT's position as a leading solution for active learning under imbalance and label noise.
Conclusion
The DIRECT paper introduces a novel deep active learning framework that effectively handles class imbalance and label noise in training data. By using a representation-guided uncertainty sampling strategy and a joint optimization approach, DIRECT is able to outperform state-of-the-art active learning methods on several benchmark datasets.
This research demonstrates the importance of addressing dataset challenges like imbalance and noise, which can significantly impact the performance of machine learning models. The DIRECT framework provides a practical and effective solution that can be valuable for a wide range of real-world applications where data quality and class balance are critical factors.
Overall, the DIRECT paper contributes an important advancement in the field of active learning and highlights the need for continued research to develop robust and adaptable machine learning systems that can handle the complexities of real-world data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

An Active Learning Framework with a Class Balancing Strategy for Time Series Classification
Shemonto Das
0
0
Training machine learning models for classification tasks often requires labeling numerous samples, which is costly and time-consuming, especially in time series analysis. This research investigates Active Learning (AL) strategies to reduce the amount of labeled data needed for effective time series classification. Traditional AL techniques cannot control the selection of instances per class for labeling, leading to potential bias in classification performance and instance selection, particularly in imbalanced time series datasets. To address this, we propose a novel class-balancing instance selection algorithm integrated with standard AL strategies. Our approach aims to select more instances from classes with fewer labeled examples, thereby addressing imbalance in time series datasets. We demonstrate the effectiveness of our AL framework in selecting informative data samples for two distinct domains of tactile texture recognition and industrial fault detection. In robotics, our method achieves high-performance texture categorization while significantly reducing labeled training data requirements to 70%. We also evaluate the impact of different sliding window time intervals on robotic texture classification using AL strategies. In synthetic fiber manufacturing, we adapt AL techniques to address the challenge of fault classification, aiming to minimize data annotation cost and time for industries. We also address real-life class imbalances in the multiclass industrial anomalous dataset using our class-balancing instance algorithm integrated with AL strategies. Overall, this thesis highlights the potential of our AL framework across these two distinct domains.
5/21/2024

Noisy Label Processing for Classification: A Survey
Mengting Li, Chuang Zhu
0
0
In recent years, deep neural networks (DNNs) have gained remarkable achievement in computer vision tasks, and the success of DNNs often depends greatly on the richness of data. However, the acquisition process of data and high-quality ground truth requires a lot of manpower and money. In the long, tedious process of data annotation, annotators are prone to make mistakes, resulting in incorrect labels of images, i.e., noisy labels. The emergence of noisy labels is inevitable. Moreover, since research shows that DNNs can easily fit noisy labels, the existence of noisy labels will cause significant damage to the model training process. Therefore, it is crucial to combat noisy labels for computer vision tasks, especially for classification tasks. In this survey, we first comprehensively review the evolution of different deep learning approaches for noisy label combating in the image classification task. In addition, we also review different noise patterns that have been proposed to design robust algorithms. Furthermore, we explore the inner pattern of real-world label noise and propose an algorithm to generate a synthetic label noise pattern guided by real-world data. We test the algorithm on the well-known real-world dataset CIFAR-10N to form a new real-world data-guided synthetic benchmark and evaluate some typical noise-robust methods on the benchmark.
4/8/2024
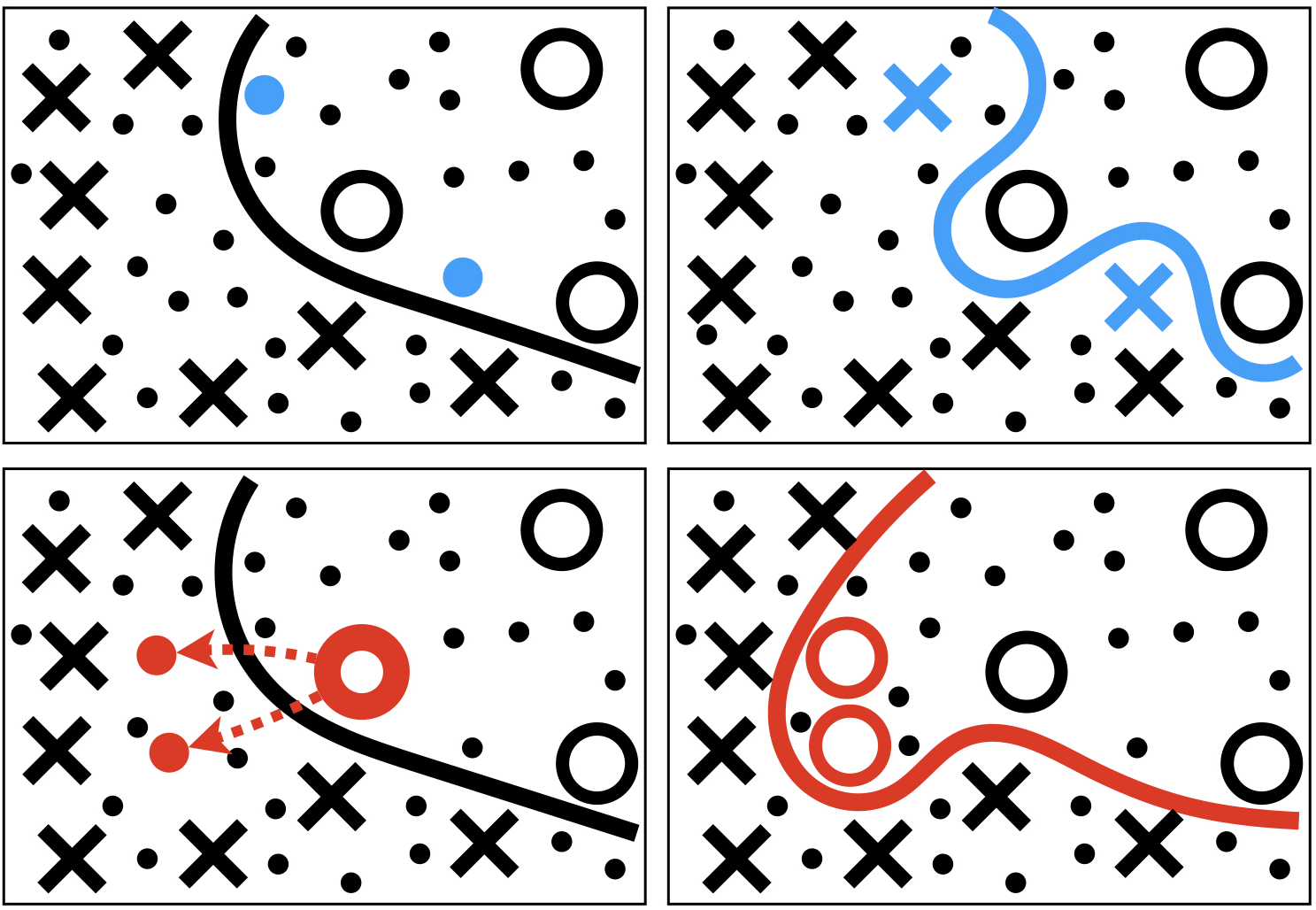
Querying Easily Flip-flopped Samples for Deep Active Learning
Seong Jin Cho, Gwangsu Kim, Junghyun Lee, Jinwoo Shin, Chang D. Yoo
0
0
Active learning is a machine learning paradigm that aims to improve the performance of a model by strategically selecting and querying unlabeled data. One effective selection strategy is to base it on the model's predictive uncertainty, which can be interpreted as a measure of how informative a sample is. The sample's distance to the decision boundary is a natural measure of predictive uncertainty, but it is often intractable to compute, especially for complex decision boundaries formed in multiclass classification tasks. To address this issue, this paper proposes the {it least disagree metric} (LDM), defined as the smallest probability of disagreement of the predicted label, and an estimator for LDM proven to be asymptotically consistent under mild assumptions. The estimator is computationally efficient and can be easily implemented for deep learning models using parameter perturbation. The LDM-based active learning is performed by querying unlabeled data with the smallest LDM. Experimental results show that our LDM-based active learning algorithm obtains state-of-the-art overall performance on all considered datasets and deep architectures.
5/17/2024
AnchorAL: Computationally Efficient Active Learning for Large and Imbalanced Datasets
Pietro Lesci, Andreas Vlachos
0
0
Active learning for imbalanced classification tasks is challenging as the minority classes naturally occur rarely. Gathering a large pool of unlabelled data is thus essential to capture minority instances. Standard pool-based active learning is computationally expensive on large pools and often reaches low accuracy by overfitting the initial decision boundary, thus failing to explore the input space and find minority instances. To address these issues we propose AnchorAL. At each iteration, AnchorAL chooses class-specific instances from the labelled set, or anchors, and retrieves the most similar unlabelled instances from the pool. This resulting subpool is then used for active learning. Using a small, fixed-sized subpool AnchorAL allows scaling any active learning strategy to large pools. By dynamically selecting different anchors at each iteration it promotes class balance and prevents overfitting the initial decision boundary, thus promoting the discovery of new clusters of minority instances. In experiments across different classification tasks, active learning strategies, and model architectures AnchorAL is (i) faster, often reducing runtime from hours to minutes, (ii) trains more performant models, (iii) and returns more balanced datasets than competing methods.
5/28/2024