Active Preference Optimization for Sample Efficient RLHF
2402.10500
0
0
🛠️
Abstract
Reinforcement Learning from Human Feedback (RLHF) is pivotal in aligning Large Language Models (LLMs) with human preferences. Although aligned generative models have shown remarkable abilities in various tasks, their reliance on high-quality human preference data creates a costly bottleneck in the practical application of RLHF. One primary reason is that current methods rely on uniformly picking prompt-generation pairs from a dataset of prompt-generations, to collect human feedback, resulting in sub-optimal alignment under a constrained budget, which highlights the criticality of adaptive strategies in efficient alignment. Recent works [Mehta et al., 2023, Muldrew et al., 2024] have tried to address this problem by designing various heuristics based on generation uncertainty. However, either the assumptions in [Mehta et al., 2023] are restrictive, or [Muldrew et al., 2024] do not provide any rigorous theoretical guarantee. To address these, we reformulate RLHF within contextual preference bandit framework, treating prompts as contexts, and develop an active-learning algorithm, $textit{Active Preference Optimization}$ ($texttt{APO}$), which enhances model alignment by querying preference data from the most important samples, achieving superior performance for small sample budget. We analyze the theoretical performance guarantees of $texttt{APO}$ under the BTL preference model showing that the suboptimality gap of the policy learned via $texttt{APO}$ scales as $O(1/sqrt{T})$ for a budget of $T$. We also show that collecting preference data by choosing prompts randomly leads to a policy that suffers a constant sub-optimality. We perform detailed experimental evaluations on practical preference datasets to validate $texttt{APO}$'s efficacy over the existing methods, establishing it as a sample-efficient and practical solution of alignment in a cost-effective and scalable manner.
Create account to get full access
Overview
- This paper addresses a key challenge in aligning large language models (LLMs) with human preferences using Reinforcement Learning from Human Feedback (RLHF).
- Current RLHF methods rely on uniformly sampling prompt-generation pairs to collect human feedback, which can lead to suboptimal alignment under a constrained budget.
- The authors propose a new algorithm called Active Preference Optimization (APO) that aims to enhance model alignment by querying preference data from the most important samples.
Plain English Explanation
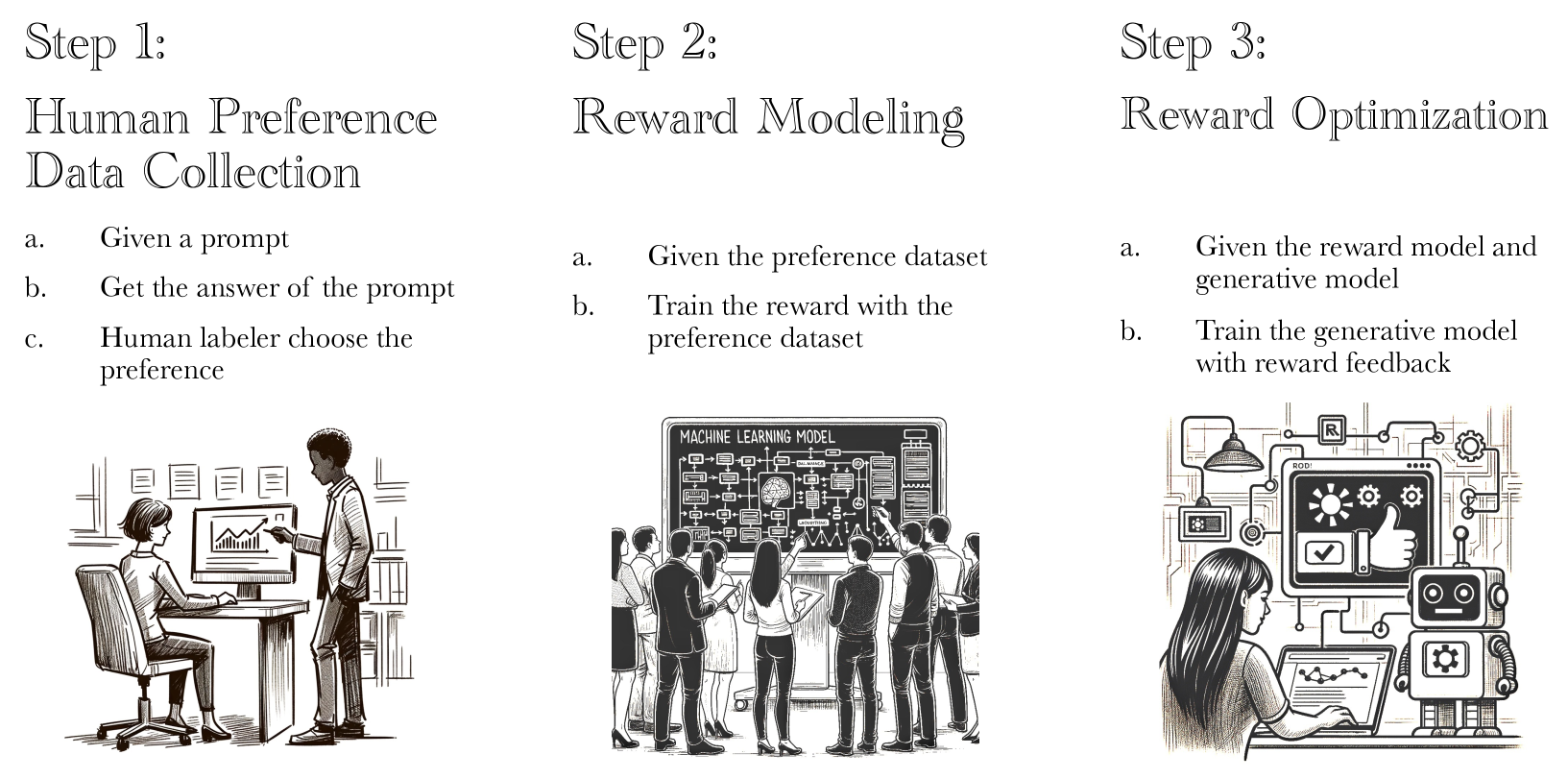
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, ensuring these models behave in alignment with human values and preferences is a critical challenge. One approach to address this is Reinforcement Learning from Human Feedback (RLHF), where the model is trained to optimize for human-preferred outputs.
The key problem is that current RLHF methods rely on randomly selecting which prompt-generation pairs to show to humans for feedback. This can lead to suboptimal results, as the model may not be learning from the most informative examples. Imagine trying to teach a child by randomly picking topics to quiz them on, rather than focusing on the areas they need the most help with.
To address this, the researchers developed a new algorithm called Active Preference Optimization (APO). APO actively selects the most important prompt-generation pairs to show to humans, in order to maximize the model's alignment with human preferences. This is akin to a teacher adaptively choosing which concepts to focus on based on the student's progress.
The authors show that APO can achieve superior performance compared to random sampling, especially when the human feedback budget is limited. This is an important step towards making RLHF a more practical and cost-effective approach for aligning LLMs with human values.
Technical Explanation
The paper formulates the RLHF problem within a contextual preference bandit framework, where prompts are treated as "contexts" and the goal is to learn a policy that generates preferred outputs. The authors develop the Active Preference Optimization (APO) algorithm, which adaptively selects the most informative prompt-generation pairs to query human preferences on.
The key insight behind APO is to leverage the uncertainty in the model's generations to prioritize the most important samples for human feedback. This is in contrast to previous heuristic-based approaches, such as Adversarial Preference Optimization and Exploratory Preference Optimization, which lack rigorous theoretical guarantees.
The authors analyze the theoretical performance of APO under the Bradley-Terry-Luce (BTL) preference model, showing that the suboptimality gap of the learned policy scales as O(1/sqrt(T)) for a budget of T human preference queries. In contrast, they demonstrate that a random sampling approach leads to a constant suboptimality.
The paper also presents detailed experimental evaluations on practical preference datasets, validating APO's effectiveness in enhancing model alignment in a sample-efficient and scalable manner compared to existing methods, such as Prompt Optimization with Human Feedback and Adaptive Preference Scaling for Reinforcement Learning from Human Feedback.
Critical Analysis
The paper presents a novel and principled approach to the RLHF problem, addressing the key shortcoming of current methods that rely on random sampling of prompt-generation pairs for human feedback. The authors' analysis and experiments demonstrate the benefits of their proposed Active Preference Optimization (APO) algorithm in terms of sample efficiency and alignment performance.
However, the paper does not address several important practical considerations. For example, the authors assume access to a well-defined preference model (BTL) and focus on the theoretical analysis. In real-world scenarios, the preference model may be more complex and require additional modeling assumptions or considerations.
Additionally, the paper does not discuss the potential pitfalls of over-optimizing for human preferences, such as the risk of amplifying human biases or myopia. It would be valuable to explore the long-term implications of such alignment techniques and consider potential safeguards or mitigation strategies.
Finally, the authors mention the need for further research on the scalability and robustness of their approach, particularly in the face of diverse and potentially noisy human feedback. Addressing these practical challenges would help strengthen the real-world applicability of the proposed method.
Conclusion
This paper introduces a novel algorithm, Active Preference Optimization (APO), that aims to enhance the alignment of large language models with human preferences in a more sample-efficient and scalable manner than existing RLHF techniques. By actively selecting the most informative prompt-generation pairs for human feedback, APO can achieve superior performance compared to random sampling approaches, especially under constrained budgets.
While the paper provides strong theoretical and empirical support for APO, it also highlights the need for further research to address practical challenges, such as the complexity of real-world preference models and the potential risks of over-optimizing for human preferences. Addressing these issues could pave the way for more robust and responsible RLHF methods, ultimately helping to ensure that large language models are aligned with human values and interests.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
Adversarial Preference Optimization: Enhancing Your Alignment via RM-LLM Game
Pengyu Cheng, Yifan Yang, Jian Li, Yong Dai, Tianhao Hu, Peixin Cao, Nan Du, Xiaolong Li
0
0
Human preference alignment is essential to improve the interaction quality of large language models (LLMs). Existing alignment methods depend on manually annotated preference data to guide the LLM optimization directions. However, continuously updating LLMs for alignment raises a distribution gap between model-generated samples and human-annotated responses, hindering training effectiveness. To mitigate this issue, previous methods require additional preference annotation on newly generated samples to adapt to the shifted distribution, which consumes a large amount of annotation resources. Targeting more efficient human preference optimization, we propose an Adversarial Preference Optimization (APO) framework, in which the LLM and the reward model update alternatively via a min-max game. Through adversarial training, the reward model can adapt to the shifted generation distribution of the LLM without any additional annotation. With comprehensive experiments, we find the proposed adversarial training framework further enhances existing alignment baselines in terms of LLM helpfulness and harmlessness. The code is at https://github.com/Linear95/APO.
6/4/2024
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
0
0
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
5/2/2024
🧪
Exploratory Preference Optimization: Harnessing Implicit Q*-Approximation for Sample-Efficient RLHF
Tengyang Xie, Dylan J. Foster, Akshay Krishnamurthy, Corby Rosset, Ahmed Awadallah, Alexander Rakhlin
0
0
Reinforcement learning from human feedback (RLHF) has emerged as a central tool for language model alignment. We consider online exploration in RLHF, which exploits interactive access to human or AI feedback by deliberately encouraging the model to produce diverse, maximally informative responses. By allowing RLHF to confidently stray from the pre-trained model, online exploration offers the possibility of novel, potentially super-human capabilities, but its full potential as a paradigm for language model training has yet to be realized, owing to computational and statistical bottlenecks in directly adapting existing reinforcement learning techniques. We propose a new algorithm for online exploration in RLHF, Exploratory Preference Optimization (XPO), which is simple and practical -- a one-line change to (online) Direct Preference Optimization (DPO; Rafailov et al., 2023) -- yet enjoys the strongest known provable guarantees and promising empirical performance. XPO augments the DPO objective with a novel and principled exploration bonus, empowering the algorithm to explore outside the support of the initial model and human feedback data. In theory, we show that XPO is provably sample-efficient and converges to a near-optimal language model policy under natural exploration conditions, irrespective of whether the initial model has good coverage. Our analysis, which builds on the observation that DPO implicitly performs a form of $Q^{star}$-approximation (or, Bellman error minimization), combines previously disparate techniques from language modeling and theoretical reinforcement learning in a serendipitous fashion through the perspective of KL-regularized Markov decision processes. Empirically, we find that XPO is more sample-efficient than non-exploratory DPO variants in a preliminary evaluation.
6/3/2024
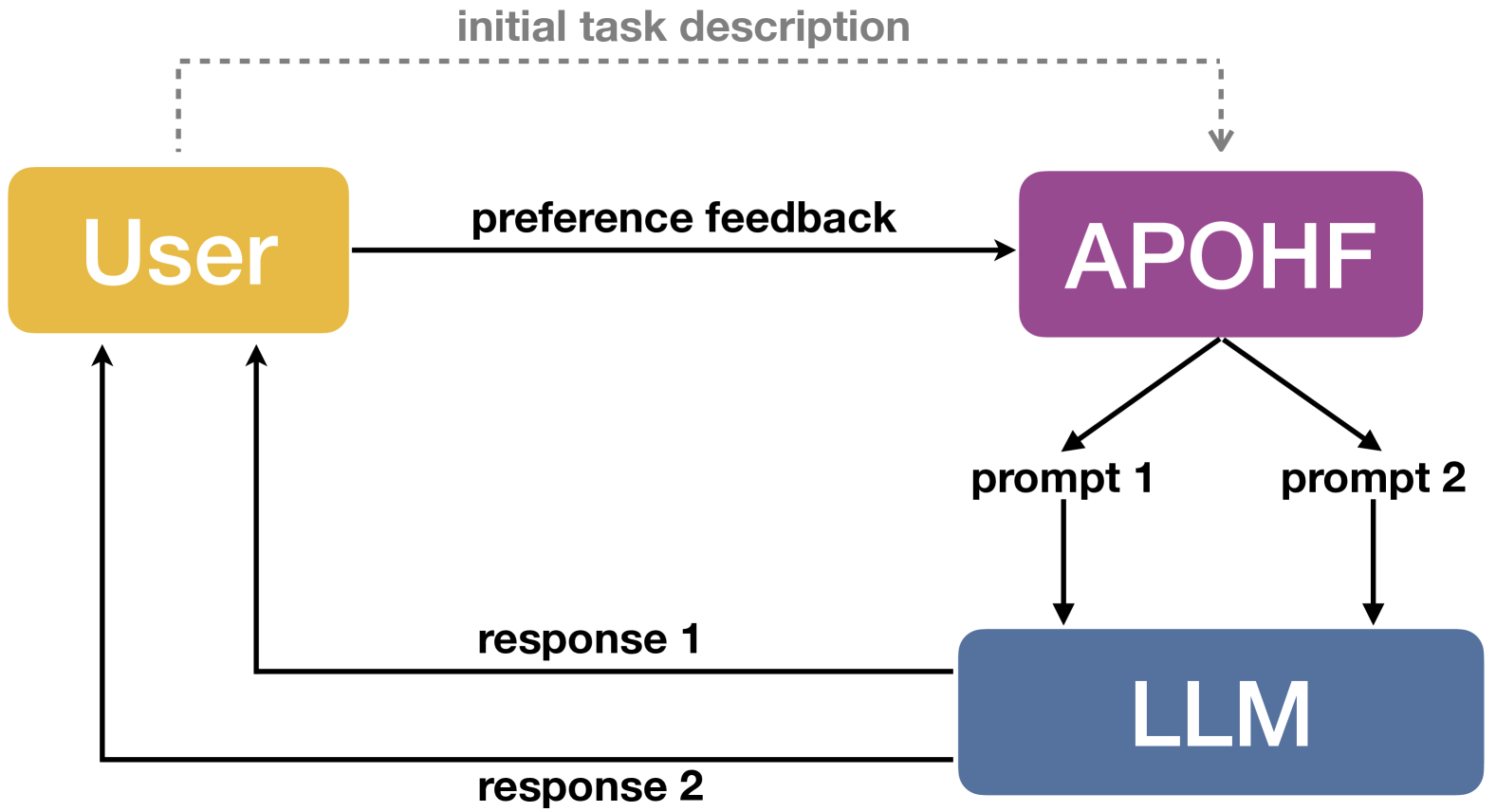
Prompt Optimization with Human Feedback
Xiaoqiang Lin, Zhongxiang Dai, Arun Verma, See-Kiong Ng, Patrick Jaillet, Bryan Kian Hsiang Low
0
0
Large language models (LLMs) have demonstrated remarkable performances in various tasks. However, the performance of LLMs heavily depends on the input prompt, which has given rise to a number of recent works on prompt optimization. However, previous works often require the availability of a numeric score to assess the quality of every prompt. Unfortunately, when a human user interacts with a black-box LLM, attaining such a score is often infeasible and unreliable. Instead, it is usually significantly easier and more reliable to obtain preference feedback from a human user, i.e., showing the user the responses generated from a pair of prompts and asking the user which one is preferred. Therefore, in this paper, we study the problem of prompt optimization with human feedback (POHF), in which we aim to optimize the prompt for a black-box LLM using only human preference feedback. Drawing inspiration from dueling bandits, we design a theoretically principled strategy to select a pair of prompts to query for preference feedback in every iteration, and hence introduce our algorithm named automated POHF (APOHF). We apply our APOHF algorithm to various tasks, including optimizing user instructions, prompt optimization for text-to-image generative models, and response optimization with human feedback (i.e., further refining the response using a variant of our APOHF). The results demonstrate that our APOHF can efficiently find a good prompt using a small number of preference feedback instances. Our code can be found at url{https://github.com/xqlin98/APOHF}.
5/28/2024