Actively Learning Reinforcement Learning: A Stochastic Optimal Control Approach

0
🏅
Sign in to get full access
Overview
- The paper proposes a framework to equip reinforcement learning with active exploration and information gathering.
- This aims to regulate uncertainties from modeling mismatches and noisy sensors.
- It also overcomes the computational complexity of stochastic optimal control.
- The key idea is to use reinforcement learning to compute the stochastic optimal control law.
Plain English Explanation
The paper presents a new approach that combines reinforcement learning with active exploration and information gathering. The goal is to help reinforcement learning systems deal with two key challenges:
-
Uncertainty from Modeling and Sensors: Real-world environments often have uncertainties due to imperfect models and noisy sensor data. This can cause issues for reinforcement learning systems.
-
Computational Complexity of Optimal Control: Directly solving the complex mathematical equations for stochastic optimal control is computationally intractable.
To address these challenges, the framework uses reinforcement learning to calculate the optimal control strategy. This avoids the curse of dimensionality that makes direct optimization so computationally difficult.
Importantly, the reinforcement learning agent is designed to actively explore its environment and gather information. This "caution and probing" behavior helps the agent regulate uncertainty, even after the initial learning process is complete.
Unlike fixed exploration strategies, this adaptive approach allows the agent to optimize its actions based on the current level of uncertainty. This can lead to better performance and stability compared to simpler control methods like the Linear Quadratic Regulator.
Technical Explanation
The paper's key technical contribution is a reinforcement learning framework for stochastic optimal control. This approach sidesteps the computational intractability of directly solving the stochastic dynamic programming equations.
Instead, the reinforcement learning agent learns the optimal control policy through interactions with the environment. Importantly, the agent is equipped with active exploration and information gathering capabilities. This allows it to regulate uncertainties from modeling mismatches and noisy sensors.
The resulting stochastic optimal control policy exhibits "caution and probing" behavior. Rather than using a fixed exploration-exploitation balance, the agent adaptively adjusts its actions based on the current state of uncertainty. This can lead to better performance and stability compared to simpler control methods.
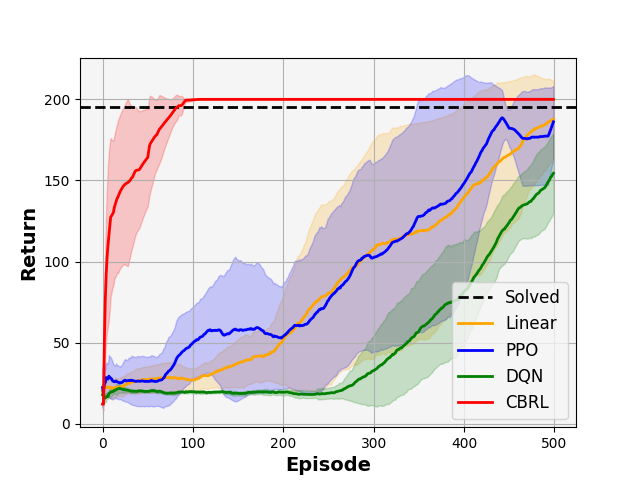
The paper concludes with a numerical simulation demonstrating the benefits of this approach. It shows how a Linear Quadratic Regulator with certainty equivalence can perform poorly and lead to filter divergence. In contrast, the proposed reinforcement learning framework is able to stabilize the system and achieve acceptable performance in a computationally convenient manner.
Critical Analysis
The paper presents a promising approach to combining reinforcement learning with stochastic optimal control. By using reinforcement learning to compute the optimal control law, it avoids the curse of dimensionality that makes direct optimization intractable.
However, the paper does not provide a formal analysis of the convergence and stability properties of the proposed algorithm. While the numerical simulations are promising, more theoretical and empirical work is needed to fully understand the strengths and limitations of this framework.
Additionally, the paper does not address the challenge of reward design for the reinforcement learning agent. Specifying an appropriate reward function that captures the desired trade-off between exploration, exploitation, and control performance is a non-trivial task that could significantly impact the agent's behavior.
Further research is also needed to understand how this approach scales to more complex, high-dimensional control problems. The computational advantages of using reinforcement learning may diminish as the problem size increases, requiring additional innovations.
Conclusion
This paper proposes an intriguing framework that combines reinforcement learning with active exploration and information gathering to overcome the challenges of stochastic optimal control. By using reinforcement learning to compute the optimal control policy, it avoids the computational intractability of direct optimization.
Importantly, the resulting control agent exhibits "caution and probing" behavior, adaptively adjusting its actions based on the current state of uncertainty. This can lead to better performance and stability compared to simpler control methods.
While the paper provides promising initial results, further research is needed to fully understand the theoretical properties, scalability, and practical implementation details of this approach. Nonetheless, this work represents an important step towards developing more robust and adaptive control systems that can thrive in complex, uncertain environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Actively Learning Reinforcement Learning: A Stochastic Optimal Control Approach
Mohammad S. Ramadan, Mahmoud A. Hayajnh, Michael T. Tolley, Kyriakos G. Vamvoudakis
In this paper we propose a framework towards achieving two intertwined objectives: (i) equipping reinforcement learning with active exploration and deliberate information gathering, such that it regulates state and parameter uncertainties resulting from modeling mismatches and noisy sensory; and (ii) overcoming the computational intractability of stochastic optimal control. We approach both objectives by using reinforcement learning to compute the stochastic optimal control law. On one hand, we avoid the curse of dimensionality prohibiting the direct solution of the stochastic dynamic programming equation. On the other hand, the resulting stochastic optimal control reinforcement learning agent admits caution and probing, that is, optimal online exploration and exploitation. Unlike fixed exploration and exploitation balance, caution and probing are employed automatically by the controller in real-time, even after the learning process is terminated. We conclude the paper with a numerical simulation, illustrating how a Linear Quadratic Regulator with the certainty equivalence assumption may lead to poor performance and filter divergence, while our proposed approach is stabilizing, of an acceptable performance, and computationally convenient.
Read more9/10/2024
📈
0
Active Learning for Control-Oriented Identification of Nonlinear Systems
Bruce D. Lee, Ingvar Ziemann, George J. Pappas, Nikolai Matni
Model-based reinforcement learning is an effective approach for controlling an unknown system. It is based on a longstanding pipeline familiar to the control community in which one performs experiments on the environment to collect a dataset, uses the resulting dataset to identify a model of the system, and finally performs control synthesis using the identified model. As interacting with the system may be costly and time consuming, targeted exploration is crucial for developing an effective control-oriented model with minimal experimentation. Motivated by this challenge, recent work has begun to study finite sample data requirements and sample efficient algorithms for the problem of optimal exploration in model-based reinforcement learning. However, existing theory and algorithms are limited to model classes which are linear in the parameters. Our work instead focuses on models with nonlinear parameter dependencies, and presents the first finite sample analysis of an active learning algorithm suitable for a general class of nonlinear dynamics. In certain settings, the excess control cost of our algorithm achieves the optimal rate, up to logarithmic factors. We validate our approach in simulation, showcasing the advantage of active, control-oriented exploration for controlling nonlinear systems.
Read more8/14/2024

0
Stochastic Reinforcement Learning with Stability Guarantees for Control of Unknown Nonlinear Systems
Thanin Quartz, Ruikun Zhou, Hans De Sterck, Jun Liu
Designing a stabilizing controller for nonlinear systems is a challenging task, especially for high-dimensional problems with unknown dynamics. Traditional reinforcement learning algorithms applied to stabilization tasks tend to drive the system close to the equilibrium point. However, these approaches often fall short of achieving true stabilization and result in persistent oscillations around the equilibrium point. In this work, we propose a reinforcement learning algorithm that stabilizes the system by learning a local linear representation ofthe dynamics. The main component of the algorithm is integrating the learned gain matrix directly into the neural policy. We demonstrate the effectiveness of our algorithm on several challenging high-dimensional dynamical systems. In these simulations, our algorithm outperforms popular reinforcement learning algorithms, such as soft actor-critic (SAC) and proximal policy optimization (PPO), and successfully stabilizes the system. To support the numerical results, we provide a theoretical analysis of the feasibility of the learned algorithm for both deterministic and stochastic reinforcement learning settings, along with a convergence analysis of the proposed learning algorithm. Furthermore, we verify that the learned control policies indeed provide asymptotic stability for the nonlinear systems.
Read more9/16/2024
0
A General Control-Theoretic Approach for Reinforcement Learning: Theory and Algorithms
Weiqin Chen, Mark S. Squillante, Chai Wah Wu, Santiago Paternain
We devise a control-theoretic reinforcement learning approach to support direct learning of the optimal policy. We establish various theoretical properties of our approach, such as convergence and optimality of our control-theoretic operator, a new control-policy-parameter gradient ascent theorem, and a specific gradient ascent algorithm based on this theorem. As a representative example, we adapt our approach to a particular control-theoretic framework and empirically evaluate its performance on several classical reinforcement learning tasks, demonstrating significant improvements in solution quality, sample complexity, and running time of our control-theoretic approach over state-of-the-art baseline methods.
Read more8/23/2024