Stochastic Reinforcement Learning with Stability Guarantees for Control of Unknown Nonlinear Systems

0

Sign in to get full access
Overview
- This paper presents a stochastic reinforcement learning framework for controlling unknown nonlinear systems with stability guarantees.
- The approach combines data-driven policy optimization with Lyapunov-based stability analysis to ensure the stability of the learned control policies.
- The method is applicable to a wide range of nonlinear systems and does not require prior knowledge of the system dynamics.
Plain English Explanation
The paper describes a new way to control complex, unknown systems using machine learning. Traditional control methods often rely on an accurate mathematical model of the system, which can be difficult to obtain for many real-world systems. This new approach, called stochastic reinforcement learning, uses data gathered from the system to learn how to control it, without requiring a precise model.
The key innovation is that the learned control policy is guaranteed to be stable, meaning the system won't go out of control or become unstable. This is achieved by combining the data-driven policy optimization with Lyapunov-based stability analysis, a mathematical technique for ensuring stability.
The method is versatile, as it can be applied to a wide variety of nonlinear systems without requiring detailed prior knowledge of the system dynamics. This makes it particularly useful for controlling complex, real-world systems where accurate models may not be available.
Technical Explanation
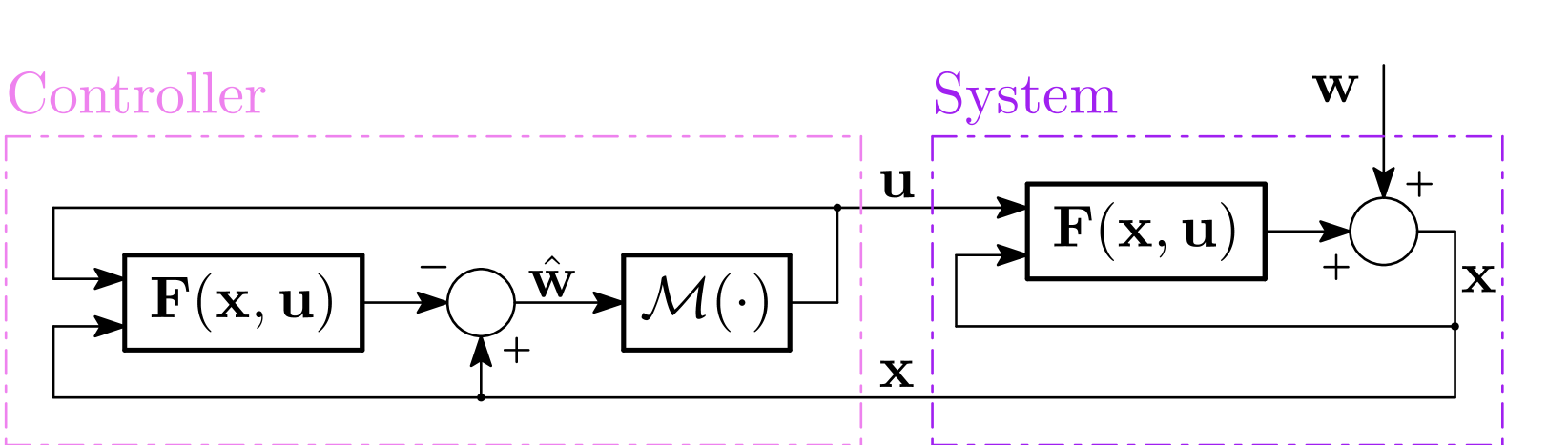
The paper proposes a stochastic reinforcement learning framework for controlling unknown nonlinear systems. The approach combines data-driven policy optimization with Lyapunov-based stability analysis to learn control policies that are guaranteed to be stable.
The algorithm starts by collecting data from the system, which is used to learn an initial control policy. This policy is then iteratively refined through policy optimization, guided by a Lyapunov function that ensures the stability of the learned policy. The Lyapunov function is constructed using a active learning approach, which adaptively selects system trajectories to improve the stability guarantees.
The key benefit of this approach is that it can control a wide range of unknown nonlinear systems without requiring a precise mathematical model of the system dynamics. The stability guarantees provided by the Lyapunov-based analysis ensure that the learned control policy will keep the system stable, even as it is refined through the reinforcement learning process.
Critical Analysis
The paper presents a promising approach for controlling unknown nonlinear systems, with the key advantage of providing stability guarantees. However, the authors acknowledge several limitations and areas for further research:
- The current framework assumes the system is fully observable, meaning all relevant state variables are available. Extending the method to partially observable systems would broaden its applicability.
- The Lyapunov-based stability analysis relies on certain assumptions about the system, such as the existence of a globally asymptotically stable equilibrium point. Relaxing these assumptions could further expand the range of systems that can be controlled.
- The computational complexity of the algorithm may limit its scalability to high-dimensional systems. Improving the efficiency of the Lyapunov function construction and policy optimization steps could help address this.
Additionally, while the paper demonstrates the effectiveness of the approach on several simulated examples, further validation on real-world systems with complex, unknown dynamics would be valuable to assess the practical utility of the method.
Conclusion
This paper presents a novel stochastic reinforcement learning framework for controlling unknown nonlinear systems, with the key innovation of providing stability guarantees for the learned control policies. By combining data-driven policy optimization with Lyapunov-based stability analysis, the approach can control a wide range of complex systems without requiring precise mathematical models.
The stability guarantees and versatility of the method make it a promising approach for real-world applications, such as robotics, aerospace, and industrial control, where controlling unknown nonlinear systems is a critical challenge. Further research to address the identified limitations and validate the method on real-world systems could help unlock the full potential of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Stochastic Reinforcement Learning with Stability Guarantees for Control of Unknown Nonlinear Systems
Thanin Quartz, Ruikun Zhou, Hans De Sterck, Jun Liu
Designing a stabilizing controller for nonlinear systems is a challenging task, especially for high-dimensional problems with unknown dynamics. Traditional reinforcement learning algorithms applied to stabilization tasks tend to drive the system close to the equilibrium point. However, these approaches often fall short of achieving true stabilization and result in persistent oscillations around the equilibrium point. In this work, we propose a reinforcement learning algorithm that stabilizes the system by learning a local linear representation ofthe dynamics. The main component of the algorithm is integrating the learned gain matrix directly into the neural policy. We demonstrate the effectiveness of our algorithm on several challenging high-dimensional dynamical systems. In these simulations, our algorithm outperforms popular reinforcement learning algorithms, such as soft actor-critic (SAC) and proximal policy optimization (PPO), and successfully stabilizes the system. To support the numerical results, we provide a theoretical analysis of the feasibility of the learned algorithm for both deterministic and stochastic reinforcement learning settings, along with a convergence analysis of the proposed learning algorithm. Furthermore, we verify that the learned control policies indeed provide asymptotic stability for the nonlinear systems.
Read more9/16/2024
0
Learning to Boost the Performance of Stable Nonlinear Systems
Luca Furieri, Clara Luc'ia Galimberti, Giancarlo Ferrari-Trecate
The growing scale and complexity of safety-critical control systems underscore the need to evolve current control architectures aiming for the unparalleled performances achievable through state-of-the-art optimization and machine learning algorithms. However, maintaining closed-loop stability while boosting the performance of nonlinear control systems using data-driven and deep-learning approaches stands as an important unsolved challenge. In this paper, we tackle the performance-boosting problem with closed-loop stability guarantees. Specifically, we establish a synergy between the Internal Model Control (IMC) principle for nonlinear systems and state-of-the-art unconstrained optimization approaches for learning stable dynamics. Our methods enable learning over arbitrarily deep neural network classes of performance-boosting controllers for stable nonlinear systems; crucially, we guarantee Lp closed-loop stability even if optimization is halted prematurely, and even when the ground-truth dynamics are unknown, with vanishing conservatism in the class of stabilizing policies as the model uncertainty is reduced to zero. We discuss the implementation details of the proposed control schemes, including distributed ones, along with the corresponding optimization procedures, demonstrating the potential of freely shaping the cost functions through several numerical experiments.
Read more5/3/2024
🏅
0
Actively Learning Reinforcement Learning: A Stochastic Optimal Control Approach
Mohammad S. Ramadan, Mahmoud A. Hayajnh, Michael T. Tolley, Kyriakos G. Vamvoudakis
In this paper we propose a framework towards achieving two intertwined objectives: (i) equipping reinforcement learning with active exploration and deliberate information gathering, such that it regulates state and parameter uncertainties resulting from modeling mismatches and noisy sensory; and (ii) overcoming the computational intractability of stochastic optimal control. We approach both objectives by using reinforcement learning to compute the stochastic optimal control law. On one hand, we avoid the curse of dimensionality prohibiting the direct solution of the stochastic dynamic programming equation. On the other hand, the resulting stochastic optimal control reinforcement learning agent admits caution and probing, that is, optimal online exploration and exploitation. Unlike fixed exploration and exploitation balance, caution and probing are employed automatically by the controller in real-time, even after the learning process is terminated. We conclude the paper with a numerical simulation, illustrating how a Linear Quadratic Regulator with the certainty equivalence assumption may lead to poor performance and filter divergence, while our proposed approach is stabilizing, of an acceptable performance, and computationally convenient.
Read more9/10/2024

0
New!Learning Unstable Continuous-Time Stochastic Linear Control Systems
Reza Sadeghi Hafshejani, Mohamad Kazem Shirani Fradonbeh
We study the problem of system identification for stochastic continuous-time dynamics, based on a single finite-length state trajectory. We present a method for estimating the possibly unstable open-loop matrix by employing properly randomized control inputs. Then, we establish theoretical performance guarantees showing that the estimation error decays with trajectory length, a measure of excitability, and the signal-to-noise ratio, while it grows with dimension. Numerical illustrations that showcase the rates of learning the dynamics, will be provided as well. To perform the theoretical analysis, we develop new technical tools that are of independent interest. That includes non-asymptotic stochastic bounds for highly non-stationary martingales and generalized laws of iterated logarithms, among others.
Read more9/18/2024