A General Control-Theoretic Approach for Reinforcement Learning: Theory and Algorithms
2406.14753
0
0
Abstract
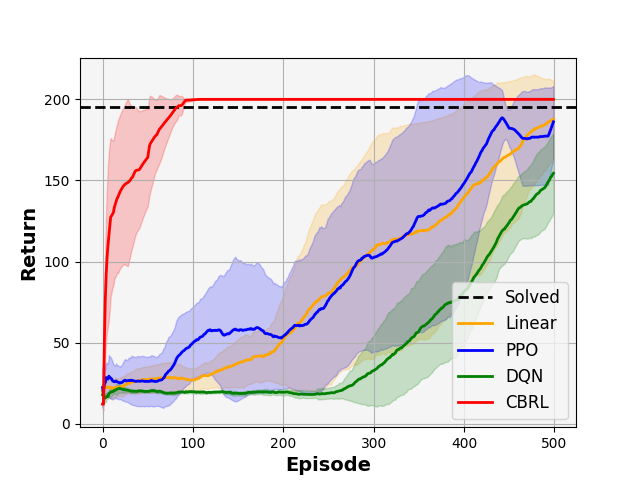
We devise a control-theoretic reinforcement learning approach to support direct learning of the optimal policy. We establish theoretical properties of our approach and derive an algorithm based on a specific instance of this approach. Our empirical results demonstrate the significant benefits of our approach.
Create account to get full access
Overview
- This paper proposes a general control-theoretic approach for reinforcement learning (RL) that unifies various RL algorithms under a common framework.
- The authors develop a new control-theoretic perspective on RL, which allows them to derive novel RL algorithms with strong theoretical guarantees.
- The paper presents theoretical analysis and experimental results demonstrating the effectiveness of the proposed control-based RL approach.
Plain English Explanation
The paper presents a new way of thinking about reinforcement learning (RL) problems, which are a type of machine learning task where an agent learns to make decisions by interacting with an environment and receiving rewards or penalties. The authors propose using concepts from control theory, a field that deals with the design and analysis of systems that can regulate themselves, to develop a more general and principled approach to RL.
By framing RL as a control problem, the authors are able to derive new RL algorithms with strong theoretical guarantees. For example, they show how their control-based approach can be used to design RL algorithms that are safer and more stable than traditional RL methods. They also demonstrate how their framework can unify various existing RL algorithms under a common mathematical structure.
The key insight of the paper is that RL problems can be viewed as a special case of a more general control problem, where the goal is to design a controller (the RL agent) that can optimize the behavior of a dynamic system (the environment) to achieve a desired objective (the reward function). By leveraging the well-developed tools and theories of control theory, the authors are able to develop a more systematic and rigorous approach to RL.
The paper includes both theoretical analysis and experimental results, which show the effectiveness of the proposed control-based RL approach. The authors demonstrate that their methods can outperform traditional RL algorithms on a variety of benchmark tasks, and they also discuss the potential limitations and areas for future research.
Technical Explanation
The paper presents a control-theoretic approach for reinforcement learning that unifies various RL algorithms under a common framework. The authors develop a new perspective on RL, which they call the "control-based RL approach", by drawing an analogy between RL problems and optimal control problems.
Specifically, the authors show that RL can be formulated as a stochastic optimal control problem, where the goal is to design a control policy (the RL agent) that can optimize the behavior of a dynamic system (the environment) to achieve a desired objective (the reward function). This control-theoretic perspective allows the authors to derive novel RL algorithms with strong theoretical guarantees, such as guaranteed convergence and stability.
The paper presents a comprehensive theoretical analysis of the proposed control-based RL approach, including theoretical bounds on the generalization performance and safety guarantees. The authors also provide experimental results on a variety of benchmark tasks, demonstrating the effectiveness of their control-based RL algorithms compared to traditional RL methods.
Furthermore, the authors show how their control-theoretic perspective can be used to unify various existing RL algorithms under a common mathematical structure, providing a deeper understanding of the relationships between different RL approaches.
Critical Analysis
The paper presents a compelling control-theoretic approach to reinforcement learning that offers several advantages over traditional RL methods. The authors' analytical framework provides a principled way to design RL algorithms with strong theoretical guarantees, which is a significant contribution to the field.
However, the paper does not discuss some potential limitations of the proposed approach. For example, the control-based RL algorithms may be more computationally expensive or require more precise modeling of the environment compared to simpler RL methods. Additionally, the theoretical analysis assumes certain assumptions about the environment and the reward function, which may not always hold in real-world applications.
Furthermore, the paper does not explore the potential challenges of applying the control-based RL approach to complex, high-dimensional environments, where the modeling and control requirements may become increasingly difficult.
Overall, the paper presents a significant theoretical contribution to the field of reinforcement learning, but further research is needed to fully understand the practical implications and limitations of the control-based RL approach, especially in more challenging real-world scenarios.
Conclusion
The paper proposes a novel control-theoretic approach to reinforcement learning that unifies various RL algorithms under a common framework. By framing RL as a stochastic optimal control problem, the authors are able to derive new RL algorithms with strong theoretical guarantees, such as convergence, stability, and safety.
The key contribution of the paper is the development of a principled, control-based perspective on RL, which provides a deeper understanding of the relationships between different RL approaches and opens up new avenues for algorithm design and analysis. The experimental results demonstrate the effectiveness of the proposed control-based RL methods, suggesting that this approach could lead to significant advancements in the field of reinforcement learning.
While the paper presents a compelling theoretical foundation, further research is needed to explore the practical implications and limitations of the control-based RL approach, particularly in complex, high-dimensional environments. Nonetheless, this work represents an important step towards a more systematic and rigorous understanding of reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Pontryagin Perspective on Reinforcement Learning
Onno Eberhard, Claire Vernade, Michael Muehlebach
0
0
Reinforcement learning has traditionally focused on learning state-dependent policies to solve optimal control problems in a closed-loop fashion. In this work, we introduce the paradigm of open-loop reinforcement learning where a fixed action sequence is learned instead. We present three new algorithms: one robust model-based method and two sample-efficient model-free methods. Rather than basing our algorithms on Bellman's equation from dynamic programming, our work builds on Pontryagin's principle from the theory of open-loop optimal control. We provide convergence guarantees and evaluate all methods empirically on a pendulum swing-up task, as well as on two high-dimensional MuJoCo tasks, demonstrating remarkable performance compared to existing baselines.
5/29/2024
🏅
A Review of Safe Reinforcement Learning: Methods, Theory and Applications
Shangding Gu, Long Yang, Yali Du, Guang Chen, Florian Walter, Jun Wang, Alois Knoll
0
0
Reinforcement Learning (RL) has achieved tremendous success in many complex decision-making tasks. However, safety concerns are raised during deploying RL in real-world applications, leading to a growing demand for safe RL algorithms, such as in autonomous driving and robotics scenarios. While safe control has a long history, the study of safe RL algorithms is still in the early stages. To establish a good foundation for future safe RL research, in this paper, we provide a review of safe RL from the perspectives of methods, theories, and applications. Firstly, we review the progress of safe RL from five dimensions and come up with five crucial problems for safe RL being deployed in real-world applications, coined as 2H3W. Secondly, we analyze the algorithm and theory progress from the perspectives of answering the 2H3W problems. Particularly, the sample complexity of safe RL algorithms is reviewed and discussed, followed by an introduction to the applications and benchmarks of safe RL algorithms. Finally, we open the discussion of the challenging problems in safe RL, hoping to inspire future research on this thread. To advance the study of safe RL algorithms, we release an open-sourced repository containing the implementations of major safe RL algorithms at the link: https://github.com/chauncygu/Safe-Reinforcement-Learning-Baselines.git.
5/28/2024
🏅
Theoretical Analysis of Meta Reinforcement Learning: Generalization Bounds and Convergence Guarantees
Cangqing Wang, Mingxiu Sui, Dan Sun, Zecheng Zhang, Yan Zhou
0
0
This research delves deeply into Meta Reinforcement Learning (Meta RL) through a exploration focusing on defining generalization limits and ensuring convergence. By employing a approach this article introduces an innovative theoretical framework to meticulously assess the effectiveness and performance of Meta RL algorithms. We present an explanation of generalization limits measuring how well these algorithms can adapt to learning tasks while maintaining consistent results. Our analysis delves into the factors that impact the adaptability of Meta RL revealing the relationship, between algorithm design and task complexity. Additionally we establish convergence assurances by proving conditions under which Meta RL strategies are guaranteed to converge towards solutions. We examine the convergence behaviors of Meta RL algorithms across scenarios providing a comprehensive understanding of the driving forces behind their long term performance. This exploration covers both convergence and real time efficiency offering a perspective, on the capabilities of these algorithms.
5/24/2024

Strategizing against Q-learners: A Control-theoretical Approach
Yuksel Arslantas, Ege Yuceel, Muhammed O. Sayin
0
0
In this paper, we explore the susceptibility of the independent Q-learning algorithms (a classical and widely used multi-agent reinforcement learning method) to strategic manipulation of sophisticated opponents in normal-form games played repeatedly. We quantify how much strategically sophisticated agents can exploit naive Q-learners if they know the opponents' Q-learning algorithm. To this end, we formulate the strategic actors' interactions as a stochastic game (whose state encompasses Q-function estimates of the Q-learners) as if the Q-learning algorithms are the underlying dynamical system. We also present a quantization-based approximation scheme to tackle the continuum state space and analyze its performance for two competing strategic actors and a single strategic actor both analytically and numerically.
5/28/2024