Model predictive control-based value estimation for efficient reinforcement learning
2310.16646
0
0
📈
Abstract
Reinforcement learning suffers from limitations in real practices primarily due to the number of required interactions with virtual environments. It results in a challenging problem because we are implausible to obtain a local optimal strategy with only a few attempts for many learning methods. Hereby, we design an improved reinforcement learning method based on model predictive control that models the environment through a data-driven approach. Based on the learned environment model, it performs multi-step prediction to estimate the value function and optimize the policy. The method demonstrates higher learning efficiency, faster convergent speed of strategies tending to the local optimal value, and less sample capacity space required by experience replay buffers. Experimental results, both in classic databases and in a dynamic obstacle avoidance scenario for an unmanned aerial vehicle, validate the proposed approaches.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Reinforcement learning (RL) faces limitations in real-world applications due to the large number of required interactions with virtual environments.
- This issue arises because many RL methods struggle to find a locally optimal strategy with just a few attempts.
- The paper proposes an improved RL method based on model predictive control that models the environment using a data-driven approach.
- The method performs multi-step prediction to estimate the value function and optimize the policy, leading to higher learning efficiency, faster convergence to local optima, and reduced sample requirements for experience replay.
- Experiments in classic benchmarks and a dynamic obstacle avoidance scenario for unmanned aerial vehicles validate the proposed approach.
Plain English Explanation
Reinforcement learning is a powerful technique for training AI systems to make decisions, but it often requires a lot of trial-and-error interactions with virtual environments before it can find a good strategy. This can be a problem in real-world applications, where we may not have the luxury of endless experimentation.
The paper proposes a new reinforcement learning method that tries to address this limitation. Instead of relying solely on trial-and-error, the method builds a model of the environment using machine learning techniques. This allows the system to simulate and predict the consequences of its actions ahead of time, rather than having to learn everything from scratch.
By using this model-based approach, the researchers found that their method could learn effective strategies much more efficiently, converging on good solutions faster and using fewer samples from the environment. This could make reinforcement learning more practical for real-world applications, like controlling an unmanned aerial vehicle navigating a dynamic obstacle course.
The key idea is to combine the power of reinforcement learning with the data-driven modeling of the model predictive control approach. This allows the system to plan ahead, make smarter decisions, and learn more quickly than traditional trial-and-error reinforcement learning.
Technical Explanation
The paper proposes a novel reinforcement learning algorithm that leverages model predictive control and data-driven modeling to address the sample efficiency limitations of standard RL methods.
The core idea is to learn an approximate model of the environment dynamics from data, and then use this model to perform multi-step predicted to estimate the value function and optimize the policy. Specifically, the method:
- Learns a dynamics model of the environment using a Gaussian process or neural network trained on observed state transitions.
- Uses this dynamics model to perform rollouts and estimate the expected future rewards (the value function).
- Optimizes the policy by maximizing the estimated value function, rather than relying solely on samples from the real environment.
By leveraging the learned environment model, the method demonstrates several key advantages over standard model-free RL:
- Higher learning efficiency: The policy can be optimized more effectively using the predicted value function, reducing the number of real-world interactions required.
- Faster convergence: The policy converges more quickly to locally optimal solutions, thanks to the multi-step planning afforded by the dynamics model.
- Reduced sample requirements: The experience replay buffer needed to store environment samples can be much smaller, as the model-based predictions compensate for fewer real-world interactions.
The paper validates the proposed approach through experiments on classic control benchmarks as well as a dynamic obstacle avoidance task for an unmanned aerial vehicle. The results show significant improvements in sample efficiency and convergence speed compared to baseline model-free RL algorithms.
Critical Analysis
The paper presents a compelling approach to improving the sample efficiency of reinforcement learning by incorporating model predictive control techniques. The key strength of the method is its ability to learn an approximate model of the environment dynamics and then leverage this model to plan ahead and optimize the policy more effectively.
However, the paper does not address some potential limitations and areas for further research:
-
Model accuracy: The performance of the method relies heavily on the quality of the learned environment model. If the model is inaccurate or fails to capture important aspects of the real-world dynamics, the planned actions and value function estimates could be misleading. Further research is needed to understand how model errors and uncertainties impact the overall performance.
-
Generalization: The paper focuses on evaluating the method on specific benchmark tasks. It's unclear how well the approach would generalize to more complex, real-world environments with higher-dimensional state spaces and more complex dynamics. Active exploration techniques may be necessary to ensure the learned model captures the relevant aspects of the environment.
-
Computational complexity: The multi-step planning and policy optimization steps introduced by the method may incur significant computational overhead, potentially limiting its applicability to real-time control tasks. Balancing the trade-offs between model complexity, planning horizon, and computational efficiency will be an important area of future research.
Despite these potential limitations, the paper presents a promising direction for improving the practical application of reinforcement learning by leveraging model-based techniques. Continued research in this area could lead to more sample-efficient and reliable RL algorithms for a wide range of real-world problems.
Conclusion
The paper proposes an innovative reinforcement learning method that combines model predictive control with data-driven modeling to address the sample efficiency limitations of standard RL approaches. By learning an approximate model of the environment dynamics, the method can perform multi-step planning to estimate the value function and optimize the policy more effectively.
The key advantages of this model-based RL approach include higher learning efficiency, faster convergence to locally optimal solutions, and reduced sample requirements for the experience replay buffer. Experimental results on classic benchmarks and a dynamic obstacle avoidance task validate the effectiveness of the proposed method.
While the paper highlights some potential limitations around model accuracy, generalization, and computational complexity, the overall approach represents an exciting step forward in making reinforcement learning more practical and applicable to real-world problems. Continued research in this area could lead to significant advancements in the field of autonomous decision-making and control.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
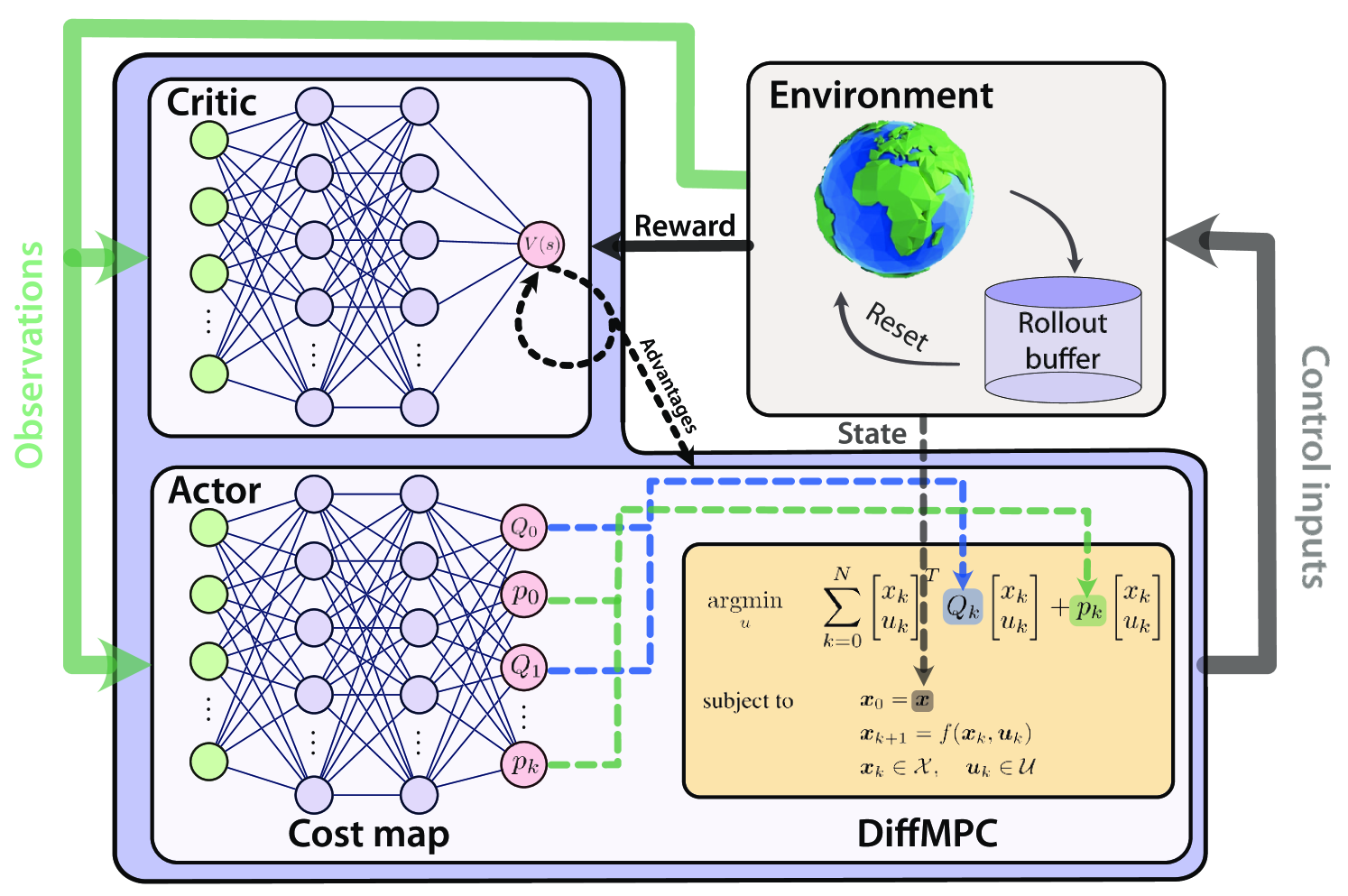
Actor-Critic Model Predictive Control
Angel Romero, Yunlong Song, Davide Scaramuzza
0
0
An open research question in robotics is how to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC). This paper provides an answer by introducing a new framework called Actor-Critic Model Predictive Control. The key idea is to embed a differentiable MPC within an actor-critic RL framework. The proposed approach leverages the short-term predictive optimization capabilities of MPC with the exploratory and end-to-end training properties of RL. The resulting policy effectively manages both short-term decisions through the MPC-based actor and long-term prediction via the critic network, unifying the benefits of both model-based control and end-to-end learning. We validate our method in both simulation and the real world with a quadcopter platform across various high-level tasks. We show that the proposed architecture can achieve real-time control performance, learn complex behaviors via trial and error, and retain the predictive properties of the MPC to better handle out of distribution behaviour.
4/15/2024
🏅
MPC-Inspired Reinforcement Learning for Verifiable Model-Free Control
Yiwen Lu, Zishuo Li, Yihan Zhou, Na Li, Yilin Mo
0
0
In this paper, we introduce a new class of parameterized controllers, drawing inspiration from Model Predictive Control (MPC). The controller resembles a Quadratic Programming (QP) solver of a linear MPC problem, with the parameters of the controller being trained via Deep Reinforcement Learning (DRL) rather than derived from system models. This approach addresses the limitations of common controllers with Multi-Layer Perceptron (MLP) or other general neural network architecture used in DRL, in terms of verifiability and performance guarantees, and the learned controllers possess verifiable properties like persistent feasibility and asymptotic stability akin to MPC. On the other hand, numerical examples illustrate that the proposed controller empirically matches MPC and MLP controllers in terms of control performance and has superior robustness against modeling uncertainty and noises. Furthermore, the proposed controller is significantly more computationally efficient compared to MPC and requires fewer parameters to learn than MLP controllers. Real-world experiments on vehicle drift maneuvering task demonstrate the potential of these controllers for robotics and other demanding control tasks.
4/10/2024
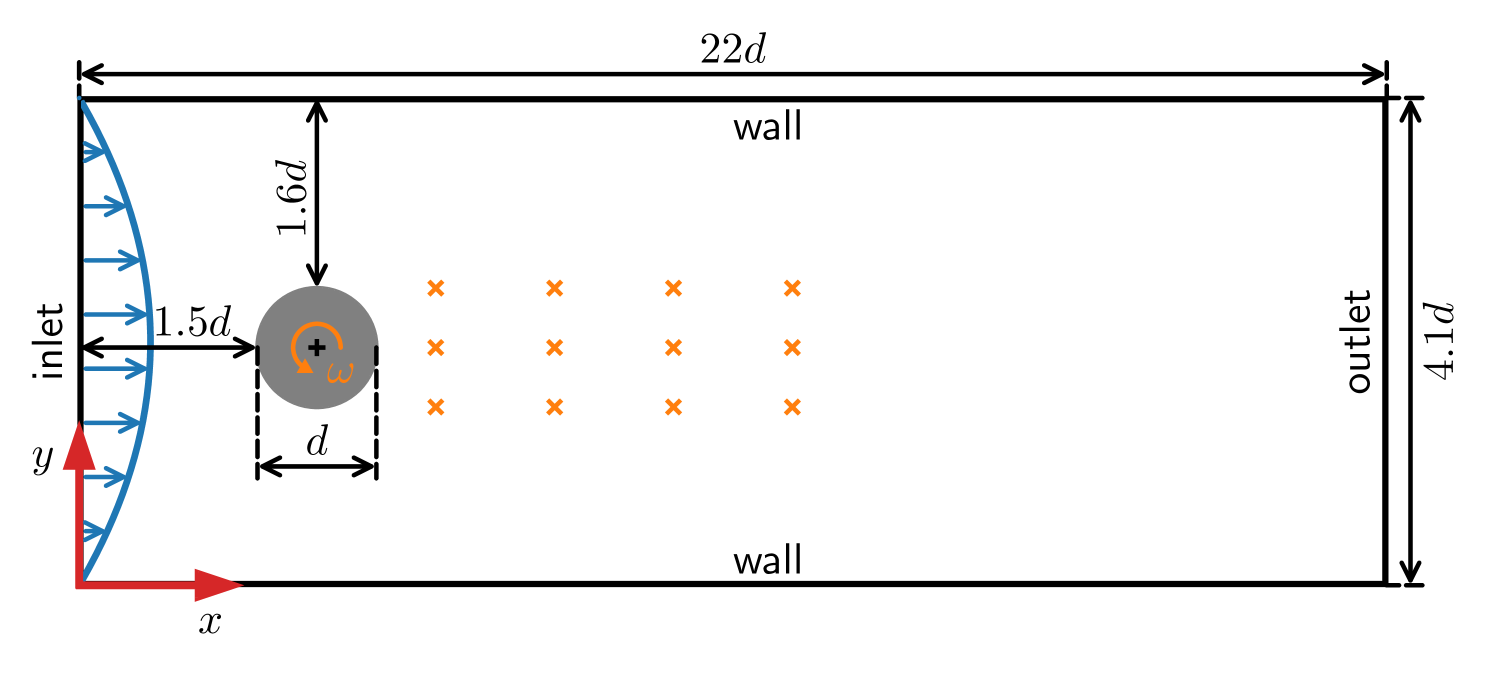
Model-based deep reinforcement learning for accelerated learning from flow simulations
Andre Weiner, Janis Geise
0
0
In recent years, deep reinforcement learning has emerged as a technique to solve closed-loop flow control problems. Employing simulation-based environments in reinforcement learning enables a priori end-to-end optimization of the control system, provides a virtual testbed for safety-critical control applications, and allows to gain a deep understanding of the control mechanisms. While reinforcement learning has been applied successfully in a number of rather simple flow control benchmarks, a major bottleneck toward real-world applications is the high computational cost and turnaround time of flow simulations. In this contribution, we demonstrate the benefits of model-based reinforcement learning for flow control applications. Specifically, we optimize the policy by alternating between trajectories sampled from flow simulations and trajectories sampled from an ensemble of environment models. The model-based learning reduces the overall training time by up to $85%$ for the fluidic pinball test case. Even larger savings are expected for more demanding flow simulations.
4/11/2024
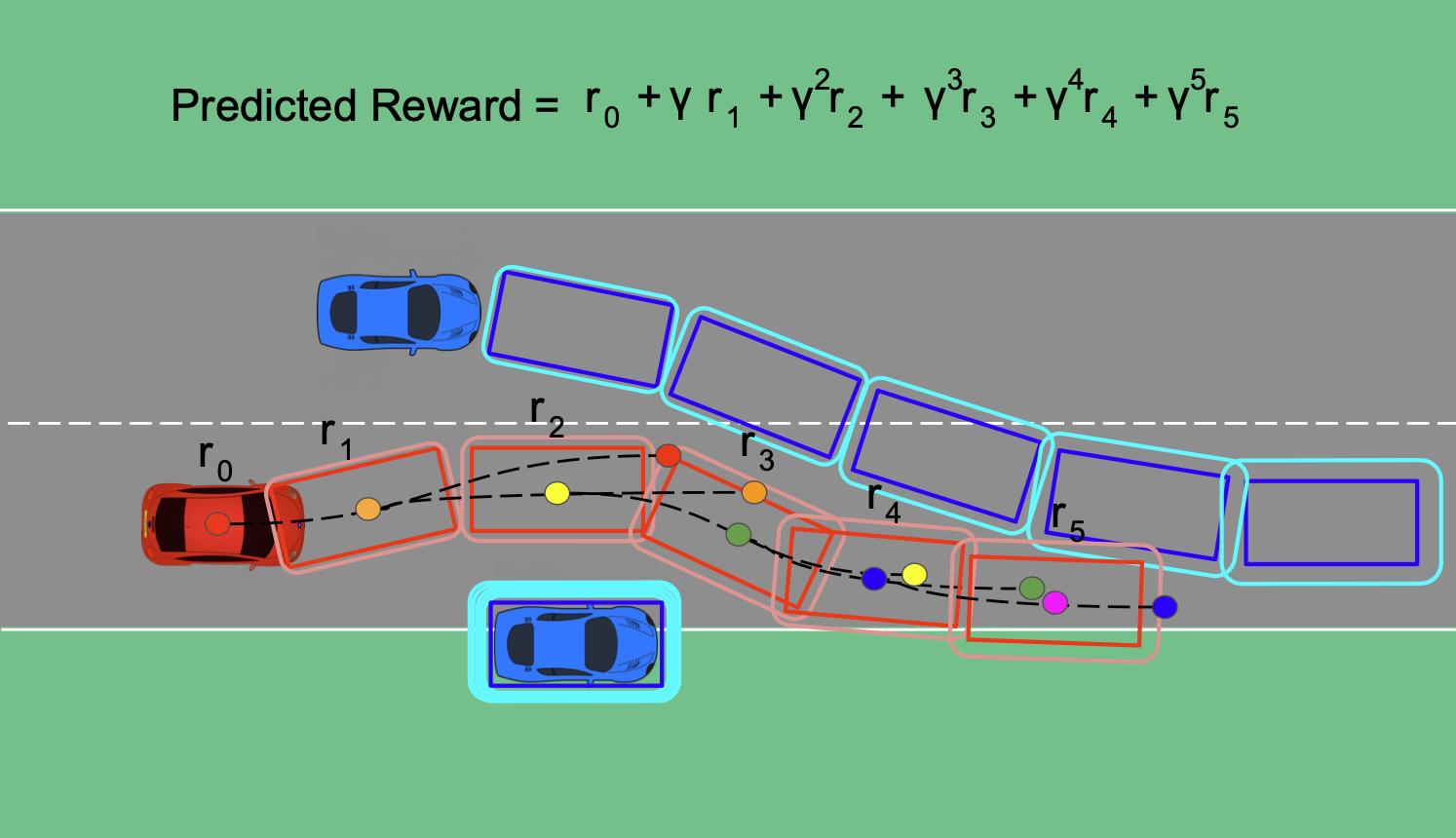
Trajectory Planning for Autonomous Vehicle Using Iterative Reward Prediction in Reinforcement Learning
Hyunwoo Park
0
0
Traditional trajectory planning methods for autonomous vehicles have several limitations. For example, heuristic and explicit simple rules limit generalizability and hinder complex motions. These limitations can be addressed using reinforcement learning-based trajectory planning. However, reinforcement learning suffers from unstable learning, and existing reinforcement learning-based trajectory planning methods do not consider the uncertainties. Thus, this paper, proposes a reinforcement learning-based trajectory planning method for autonomous vehicles. The proposed method involves an iterative reward prediction approach that iteratively predicts expectations of future states. These predicted states are then used to forecast rewards and integrated into the learning process to enhance stability. Additionally, a method is proposed that utilizes uncertainty propagation to make the reinforcement learning agent aware of uncertainties. The proposed method was evaluated using the CARLA simulator. Compared to the baseline methods, the proposed method reduced the collision rate by 60.17 %, and increased the average reward by 30.82 times. A video of the proposed method is available at https://www.youtube.com/watch?v=PfDbaeLfcN4.
5/14/2024