AdaDemo: Data-Efficient Demonstration Expansion for Generalist Robotic Agent
2404.07428
0
0
Abstract
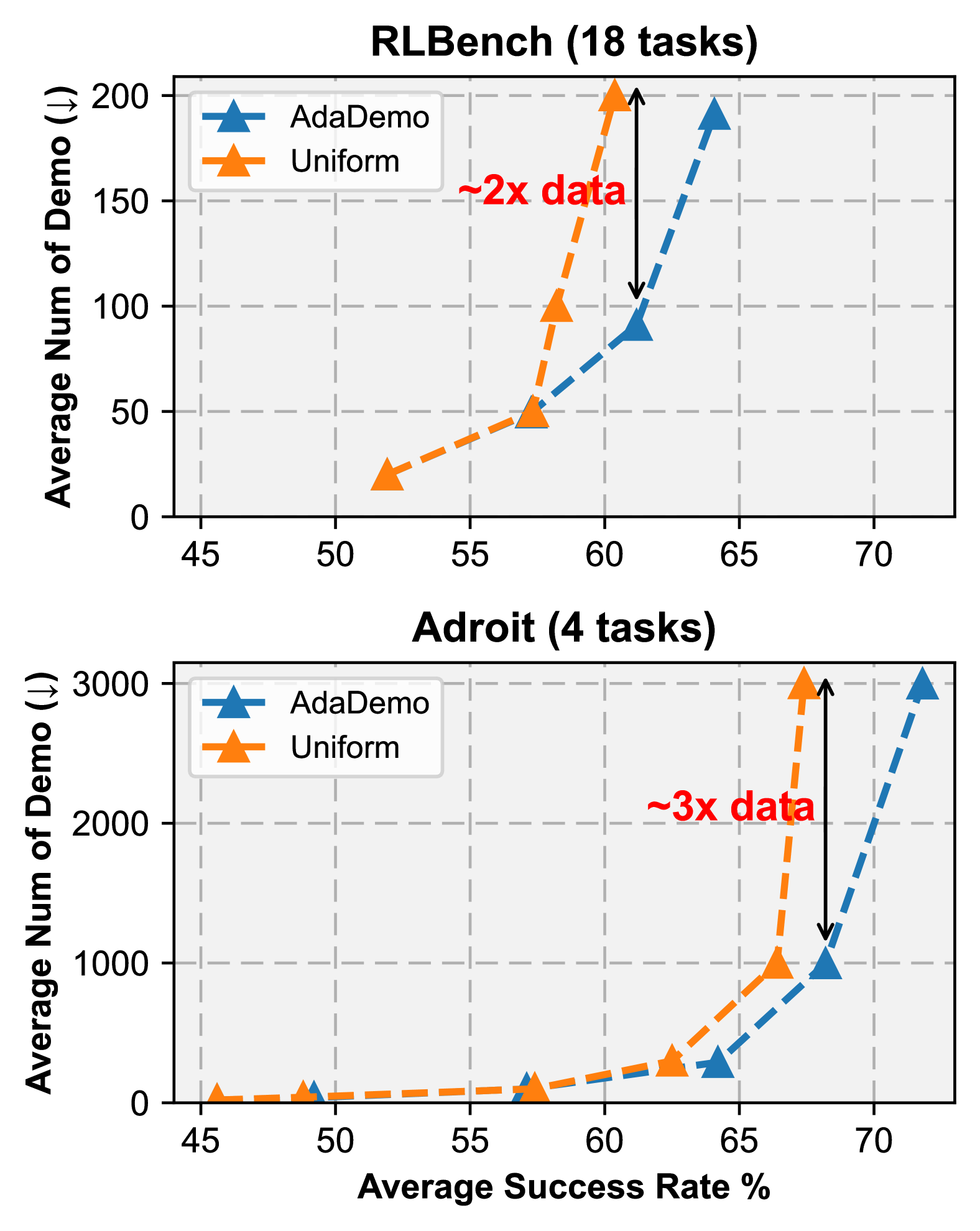
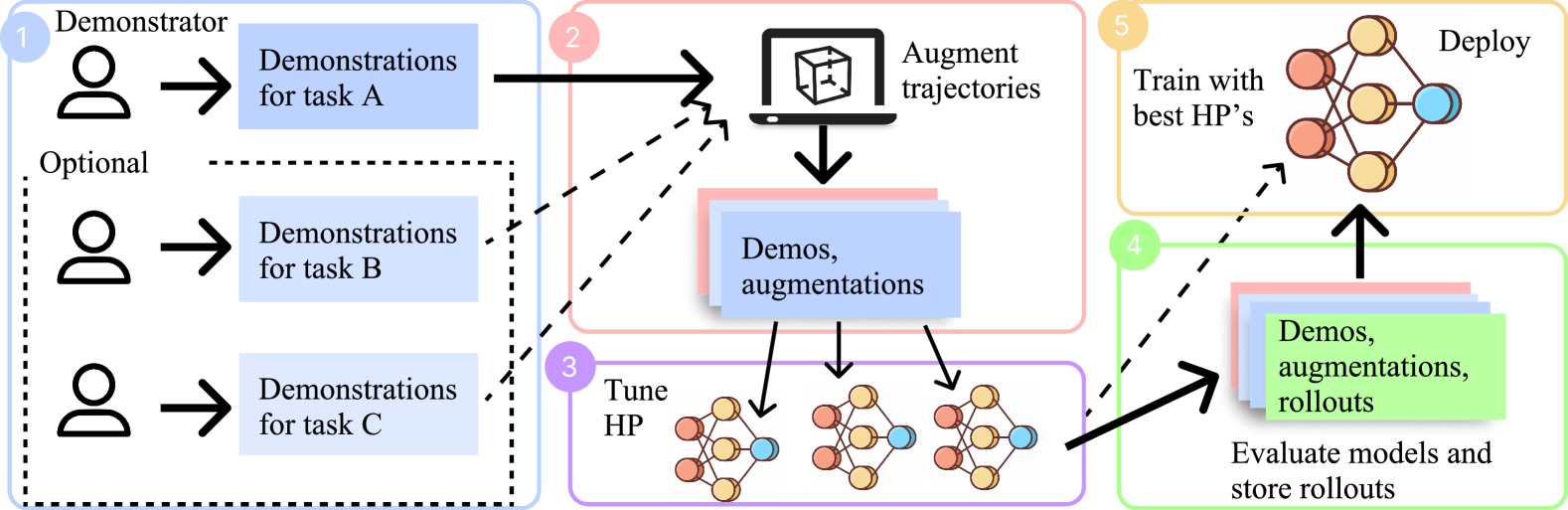
Encouraged by the remarkable achievements of language and vision foundation models, developing generalist robotic agents through imitation learning, using large demonstration datasets, has become a prominent area of interest in robot learning. The efficacy of imitation learning is heavily reliant on the quantity and quality of the demonstration datasets. In this study, we aim to scale up demonstrations in a data-efficient way to facilitate the learning of generalist robotic agents. We introduce AdaDemo (Adaptive Online Demonstration Expansion), a general framework designed to improve multi-task policy learning by actively and continually expanding the demonstration dataset. AdaDemo strategically collects new demonstrations to address the identified weakness in the existing policy, ensuring data efficiency is maximized. Through a comprehensive evaluation on a total of 22 tasks across two robotic manipulation benchmarks (RLBench and Adroit), we demonstrate AdaDemo's capability to progressively improve policy performance by guiding the generation of high-quality demonstration datasets in a data-efficient manner.
Create account to get full access
Overview
- This paper presents AdaDemo, a data-efficient demonstration expansion approach for training generalist robotic agents.
- AdaDemo aims to enable robots to learn a wide range of tasks from a small number of demonstrations, improving data efficiency.
- The key ideas include adaptive demonstration augmentation, self-supervised learning, and a novel task-agnostic reward model.
Plain English Explanation
The paper describes a new method called AdaDemo that helps train robots to learn a variety of tasks efficiently, using only a small number of example demonstrations. This is important because collecting large datasets of robot demonstrations can be time-consuming and expensive.
AdaDemo works by automatically expanding the available demonstration data through adaptive augmentation techniques. It also uses self-supervised learning to extract useful representations from the demonstrations, and a reward model that can be applied to a wide range of tasks without needing task-specific reward functions.
The goal is to enable robots to become more "generalist" - able to learn and perform a diverse set of tasks, rather than being specialized for a narrow set of activities. This could make robots more versatile and practical for real-world use cases.
Technical Explanation
The paper introduces AdaDemo, a framework for data-efficient demonstration expansion to train generalist robotic agents. The key components of AdaDemo include:
-
Adaptive Demonstration Augmentation: AdaDemo uses a learned policy to adaptively augment the available demonstration data, generating new synthetic demonstrations that are likely to be helpful for learning a wide range of tasks.
-
Self-Supervised Learning: AdaDemo employs self-supervised learning techniques to extract useful representations from the demonstration data, without relying on task-specific labels or rewards.
-
Task-Agnostic Reward Model: AdaDemo trains a reward model that can be applied to a variety of tasks, without the need for manual reward engineering for each new task.
The authors evaluate AdaDemo on a diverse suite of simulated robotic manipulation tasks, showing that it can achieve strong performance using significantly fewer demonstrations compared to baseline methods. The results demonstrate the potential of AdaDemo to enable more data-efficient and versatile robot learning.
Critical Analysis
The paper presents a compelling approach for improving the data efficiency and generalization of robotic agents. The adaptive demonstration augmentation technique is an interesting innovation that could help address the data scarcity problem common in robot learning.
However, the paper does not fully address the potential limitations of the task-agnostic reward model. While this component aims to improve versatility, it may struggle to capture the nuances of more complex or domain-specific tasks. Further research may be needed to understand the tradeoffs and limitations of this approach.
Additionally, the evaluation is limited to simulated environments, and it would be valuable to see how AdaDemo performs on real-world robotic platforms and tasks. Deploying such techniques in the physical world introduces additional challenges, such as dealing with sensor noise and environmental uncertainty.
Overall, the AdaDemo framework represents a promising step towards more data-efficient and generalist robot learning. Continued research and real-world validation could further strengthen the impact of this work.
Conclusion
The AdaDemo paper presents a novel approach for training generalist robotic agents in a data-efficient manner. By combining adaptive demonstration augmentation, self-supervised learning, and a task-agnostic reward model, the authors demonstrate the potential to enable robots to learn a wide range of skills from a small number of example demonstrations.
This research has significant implications for the development of more versatile and practical robotic systems, as it could reduce the cost and effort required to train robots for diverse real-world applications. Further exploration of the limitations and real-world performance of the AdaDemo framework could lead to important advancements in the field of robot learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
JUICER: Data-Efficient Imitation Learning for Robotic Assembly
Lars Ankile, Anthony Simeonov, Idan Shenfeld, Pulkit Agrawal
0
0
While learning from demonstrations is powerful for acquiring visuomotor policies, high-performance imitation without large demonstration datasets remains challenging for tasks requiring precise, long-horizon manipulation. This paper proposes a pipeline for improving imitation learning performance with a small human demonstration budget. We apply our approach to assembly tasks that require precisely grasping, reorienting, and inserting multiple parts over long horizons and multiple task phases. Our pipeline combines expressive policy architectures and various techniques for dataset expansion and simulation-based data augmentation. These help expand dataset support and supervise the model with locally corrective actions near bottleneck regions requiring high precision. We demonstrate our pipeline on four furniture assembly tasks in simulation, enabling a manipulator to assemble up to five parts over nearly 2500 time steps directly from RGB images, outperforming imitation and data augmentation baselines. Project website: https://imitation-juicer.github.io/.
4/11/2024

Human Demonstrations are Generalizable Knowledge for Robots
Te Cui, Guangyan Chen, Tianxing Zhou, Zicai Peng, Mengxiao Hu, Haoyang Lu, Haizhou Li, Meiling Wang, Yi Yang, Yufeng Yue
0
0
Learning from human demonstrations is an emerging trend for designing intelligent robotic systems. However, previous methods typically regard videos as instructions, simply dividing them into action sequences for robotic repetition, which poses obstacles to generalization to diverse tasks or object instances. In this paper, we propose a different perspective, considering human demonstration videos not as mere instructions, but as a source of knowledge for robots. Motivated by this perspective and the remarkable comprehension and generalization capabilities exhibited by large language models (LLMs), we propose DigKnow, a method that DIstills Generalizable KNOWledge with a hierarchical structure. Specifically, DigKnow begins by converting human demonstration video frames into observation knowledge. This knowledge is then subjected to analysis to extract human action knowledge and further distilled into pattern knowledge compassing task and object instances, resulting in the acquisition of generalizable knowledge with a hierarchical structure. In settings with different tasks or object instances, DigKnow retrieves relevant knowledge for the current task and object instances. Subsequently, the LLM-based planner conducts planning based on the retrieved knowledge, and the policy executes actions in line with the plan to achieve the designated task. Utilizing the retrieved knowledge, we validate and rectify planning and execution outcomes, resulting in a substantial enhancement of the success rate. Experimental results across a range of tasks and scenes demonstrate the effectiveness of this approach in facilitating real-world robots to accomplish tasks with the knowledge derived from human demonstrations.
5/14/2024
🛸
DiffGen: Robot Demonstration Generation via Differentiable Physics Simulation, Differentiable Rendering, and Vision-Language Model
Yang Jin, Jun Lv, Shuqiang Jiang, Cewu Lu
0
0
Generating robot demonstrations through simulation is widely recognized as an effective way to scale up robot data. Previous work often trained reinforcement learning agents to generate expert policies, but this approach lacks sample efficiency. Recently, a line of work has attempted to generate robot demonstrations via differentiable simulation, which is promising but heavily relies on reward design, a labor-intensive process. In this paper, we propose DiffGen, a novel framework that integrates differentiable physics simulation, differentiable rendering, and a vision-language model to enable automatic and efficient generation of robot demonstrations. Given a simulated robot manipulation scenario and a natural language instruction, DiffGen can generate realistic robot demonstrations by minimizing the distance between the embedding of the language instruction and the embedding of the simulated observation after manipulation. The embeddings are obtained from the vision-language model, and the optimization is achieved by calculating and descending gradients through the differentiable simulation, differentiable rendering, and vision-language model components, thereby accomplishing the specified task. Experiments demonstrate that with DiffGen, we could efficiently and effectively generate robot data with minimal human effort or training time.
5/14/2024

Online Adaptation for Enhancing Imitation Learning Policies
Federico Malato, Ville Hautamaki
0
0
Imitation learning enables autonomous agents to learn from human examples, without the need for a reward signal. Still, if the provided dataset does not encapsulate the task correctly, or when the task is too complex to be modeled, such agents fail to reproduce the expert policy. We propose to recover from these failures through online adaptation. Our approach combines the action proposal coming from a pre-trained policy with relevant experience recorded by an expert. The combination results in an adapted action that closely follows the expert. Our experiments show that an adapted agent performs better than its pure imitation learning counterpart. Notably, adapted agents can achieve reasonable performance even when the base, non-adapted policy catastrophically fails.
6/10/2024