DiffGen: Robot Demonstration Generation via Differentiable Physics Simulation, Differentiable Rendering, and Vision-Language Model
2405.07309
0
0
🛸
Abstract
Generating robot demonstrations through simulation is widely recognized as an effective way to scale up robot data. Previous work often trained reinforcement learning agents to generate expert policies, but this approach lacks sample efficiency. Recently, a line of work has attempted to generate robot demonstrations via differentiable simulation, which is promising but heavily relies on reward design, a labor-intensive process. In this paper, we propose DiffGen, a novel framework that integrates differentiable physics simulation, differentiable rendering, and a vision-language model to enable automatic and efficient generation of robot demonstrations. Given a simulated robot manipulation scenario and a natural language instruction, DiffGen can generate realistic robot demonstrations by minimizing the distance between the embedding of the language instruction and the embedding of the simulated observation after manipulation. The embeddings are obtained from the vision-language model, and the optimization is achieved by calculating and descending gradients through the differentiable simulation, differentiable rendering, and vision-language model components, thereby accomplishing the specified task. Experiments demonstrate that with DiffGen, we could efficiently and effectively generate robot data with minimal human effort or training time.
Create account to get full access
Overview
- The paper proposes a novel framework called DiffGen to generate realistic robot demonstrations automatically and efficiently.
- DiffGen integrates differentiable physics simulation, differentiable rendering, and a vision-language model.
- Given a simulated robot manipulation scenario and a natural language instruction, DiffGen can generate robot demonstrations that accomplish the specified task.
- The key innovation is optimizing the simulated robot's actions by minimizing the distance between the language instruction embedding and the observation embedding after manipulation.
Plain English Explanation
Generating realistic robot demonstration data is crucial for training robots to perform complex tasks. However, collecting real-world robot data is time-consuming and labor-intensive. The authors of this paper propose a new approach called DiffGen that can automatically generate robot demonstration data in a simulation environment.
DiffGen works by integrating several advanced AI components. First, it uses differentiable physics simulation to model the robot's movements and interactions with its environment. This allows the system to calculate gradients, or directions of improvement, for the robot's actions.
Next, DiffGen uses differentiable rendering to convert the simulated robot movements into visual observations that the robot would see. This bridges the gap between the simulated environment and the robot's visual perception.
Finally, DiffGen employs a vision-language model to understand the natural language instructions provided to the robot. The system then optimizes the robot's actions by minimizing the distance between the language instruction embedding and the observation embedding after the manipulation.
By combining these powerful AI techniques, DiffGen can efficiently generate realistic robot demonstration data with minimal human effort or training time. This could significantly accelerate the development of robust and data-efficient robotic systems that can learn from generalized knowledge gained from human demonstrations and expand their capabilities through demonstration data generation.
Technical Explanation
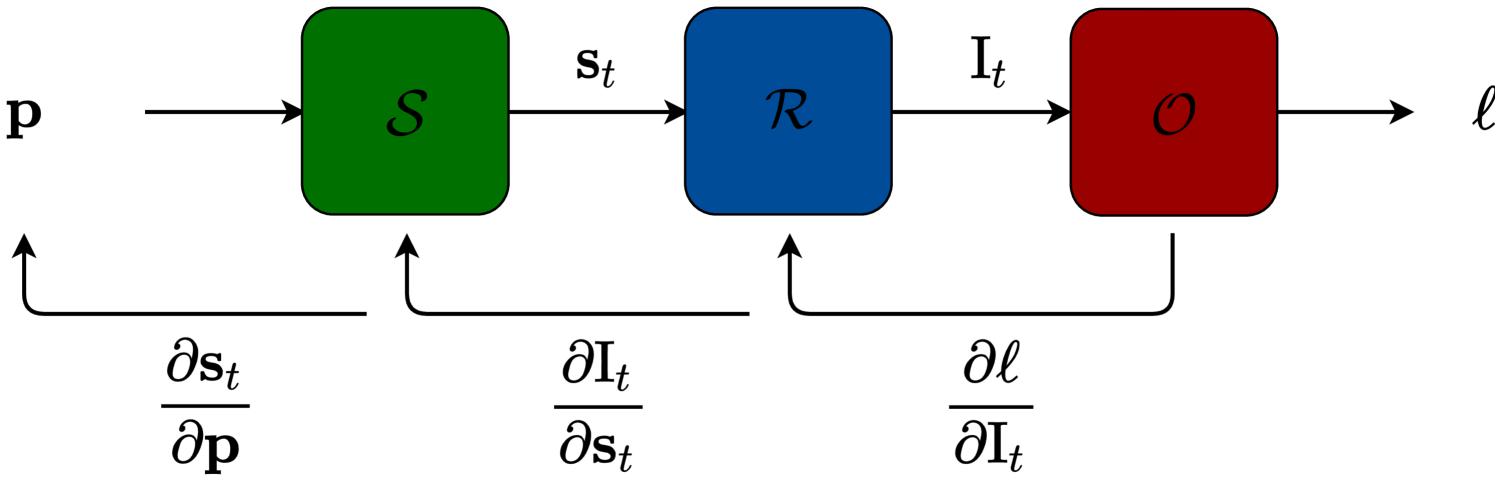
The DiffGen framework consists of three key components: differentiable physics simulation, differentiable rendering, and a vision-language model. The authors use these components to generate realistic robot demonstrations by optimizing the robot's actions to match the provided natural language instruction.
The differentiable physics simulation component models the robot's movements and interactions with the environment, allowing gradients to be calculated for the robot's actions. The differentiable rendering component then converts the simulated robot movements into visual observations that the robot would perceive.
The vision-language model is used to obtain embeddings, or numerical representations, of the natural language instruction and the simulated visual observations. The framework then optimizes the robot's actions by minimizing the distance between the language instruction embedding and the observation embedding after the manipulation.
Through this optimization process, DiffGen is able to generate robot demonstrations that effectively accomplish the specified task. The authors demonstrate the efficiency and effectiveness of DiffGen in their experiments, showing that it can generate high-quality robot data with minimal human effort or training time.
Critical Analysis
The paper presents a compelling approach to generating robot demonstration data through simulation, but there are a few areas that could be further explored or addressed:
-
The reliance on reward design: While the authors claim that DiffGen avoids the labor-intensive process of reward design, the optimization process still relies on the quality of the vision-language model and the distance metric used to compare the language instruction and observation embeddings. Investigating alternative optimization approaches or ways to further automate the process could be valuable.
-
Generalization to more complex tasks: The paper focuses on relatively simple robot manipulation scenarios. Exploring the scalability of DiffGen to more complex, multi-step tasks or diverse robot morphologies would help assess the broader applicability of the framework.
-
Validation with real-world deployment: The authors demonstrate the effectiveness of DiffGen in simulation, but validating the generated demonstrations on physical robots would provide additional insights into the framework's performance and limitations in real-world settings.
-
Potential biases in the vision-language model: As with any language model, the vision-language model used in DiffGen may encode societal biases that could be reflected in the generated demonstrations. Analyzing and mitigating these biases would be an important consideration for the deployment of such a system.
Overall, the DiffGen framework represents a promising step towards more efficient and scalable robot data generation, but further research and validation could help address the identified areas for improvement and expand the capabilities of this approach.
Conclusion
The DiffGen framework proposed in this paper presents a novel and effective way to generate realistic robot demonstration data through the integration of differentiable physics simulation, differentiable rendering, and a vision-language model. By optimizing the robot's actions to match the provided natural language instruction, DiffGen can efficiently produce high-quality robot data with minimal human effort.
This work has the potential to significantly accelerate the development of robust and data-efficient robotic systems that can learn from generalized knowledge gained from human demonstrations and expand their capabilities through demonstration data generation. While the paper identifies some areas for further exploration, the core ideas and innovations of DiffGen represent an important contribution to the field of robotic data generation and simulation-based training.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation
Yufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, Chuang Gan
0
0
We present RoboGen, a generative robotic agent that automatically learns diverse robotic skills at scale via generative simulation. RoboGen leverages the latest advancements in foundation and generative models. Instead of directly using or adapting these models to produce policies or low-level actions, we advocate for a generative scheme, which uses these models to automatically generate diversified tasks, scenes, and training supervisions, thereby scaling up robotic skill learning with minimal human supervision. Our approach equips a robotic agent with a self-guided propose-generate-learn cycle: the agent first proposes interesting tasks and skills to develop, and then generates corresponding simulation environments by populating pertinent objects and assets with proper spatial configurations. Afterwards, the agent decomposes the proposed high-level task into sub-tasks, selects the optimal learning approach (reinforcement learning, motion planning, or trajectory optimization), generates required training supervision, and then learns policies to acquire the proposed skill. Our work attempts to extract the extensive and versatile knowledge embedded in large-scale models and transfer them to the field of robotics. Our fully generative pipeline can be queried repeatedly, producing an endless stream of skill demonstrations associated with diverse tasks and environments.
6/18/2024
🤖
Evolution and learning in differentiable robots
Luke Strgar, David Matthews, Tyler Hummer, Sam Kriegman
0
0
The automatic design of robots has existed for 30 years but has been constricted by serial non-differentiable design evaluations, premature convergence to simple bodies or clumsy behaviors, and a lack of sim2real transfer to physical machines. Thus, here we employ massively-parallel differentiable simulations to rapidly and simultaneously optimize individual neural control of behavior across a large population of candidate body plans and return a fitness score for each design based on the performance of its fully optimized behavior. Non-differentiable changes to the mechanical structure of each robot in the population -- mutations that rearrange, combine, add, or remove body parts -- were applied by a genetic algorithm in an outer loop of search, generating a continuous flow of novel morphologies with highly-coordinated and graceful behaviors honed by gradient descent. This enabled the exploration of several orders-of-magnitude more designs than all previous methods, despite the fact that robots here have the potential to be much more complex, in terms of number of independent motors, than those in prior studies. We found that evolution reliably produces ``increasingly differentiable'' robots: body plans that smooth the loss landscape in which learning operates and thereby provide better training paths toward performant behaviors. Finally, one of the highly differentiable morphologies discovered in simulation was realized as a physical robot and shown to retain its optimized behavior. This provides a cyberphysical platform to investigate the relationship between evolution and learning in biological systems and broadens our understanding of how a robot's physical structure can influence the ability to train policies for it. Videos and code at https://sites.google.com/view/eldir.
5/28/2024
Dreamitate: Real-World Visuomotor Policy Learning via Video Generation
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, Carl Vondrick
0
0
A key challenge in manipulation is learning a policy that can robustly generalize to diverse visual environments. A promising mechanism for learning robust policies is to leverage video generative models, which are pretrained on large-scale datasets of internet videos. In this paper, we propose a visuomotor policy learning framework that fine-tunes a video diffusion model on human demonstrations of a given task. At test time, we generate an example of an execution of the task conditioned on images of a novel scene, and use this synthesized execution directly to control the robot. Our key insight is that using common tools allows us to effortlessly bridge the embodiment gap between the human hand and the robot manipulator. We evaluate our approach on four tasks of increasing complexity and demonstrate that harnessing internet-scale generative models allows the learned policy to achieve a significantly higher degree of generalization than existing behavior cloning approaches.
6/26/2024
Differentiable Rendering as a Way to Program Cable-Driven Soft Robots
Kasra Arnavaz, Kenny Erleben
0
0
Soft robots have gained increased popularity in recent years due to their adaptability and compliance. In this paper, we use a digital twin model of cable-driven soft robots to learn control parameters in simulation. In doing so, we take advantage of differentiable rendering as a way to instruct robots to complete tasks such as point reach, gripping an object, and obstacle avoidance. This approach simplifies the mathematical description of such complicated tasks and removes the need for landmark points and their tracking. Our experiments demonstrate the applicability of our method.
4/12/2024