Online Adaptation for Enhancing Imitation Learning Policies
2406.04913
0
0

Abstract
Imitation learning enables autonomous agents to learn from human examples, without the need for a reward signal. Still, if the provided dataset does not encapsulate the task correctly, or when the task is too complex to be modeled, such agents fail to reproduce the expert policy. We propose to recover from these failures through online adaptation. Our approach combines the action proposal coming from a pre-trained policy with relevant experience recorded by an expert. The combination results in an adapted action that closely follows the expert. Our experiments show that an adapted agent performs better than its pure imitation learning counterpart. Notably, adapted agents can achieve reasonable performance even when the base, non-adapted policy catastrophically fails.
Create account to get full access
Overview
- This paper presents a method for online adaptation of imitation learning policies to enhance their performance.
- The approach combines behavioral cloning and inverse reinforcement learning to learn a reward function that can be used to fine-tune the policy during deployment.
- The authors demonstrate the effectiveness of their method on various simulated robotic control tasks.
Plain English Explanation
The paper introduces a new way to improve the performance of imitation learning policies, which are models trained to mimic expert behavior. The key idea is to combine two common approaches to imitation learning - behavioral cloning and inverse reinforcement learning.
First, the method learns an initial policy through behavioral cloning, where the model is trained to directly predict the expert's actions given the current state. This provides a baseline policy that can perform the task reasonably well.
Next, the method uses inverse reinforcement learning to learn a reward function that captures the expert's underlying objectives. This reward function represents what the expert is trying to optimize for, even if their exact decision-making process is not fully known.
Finally, the authors use this learned reward function to fine-tune the initial policy in an online fashion during deployment. This allows the policy to adapt and improve its performance over time, without requiring additional expert demonstrations.
The authors evaluate their approach on several simulated robotic control tasks, showing that it can outperform both the initial behavioral cloning policy and other state-of-the-art imitation learning methods.
Technical Explanation
The paper proposes an online adaptation framework for enhancing imitation learning policies. The key components are:
-
Behavioral Cloning: The method first learns an initial policy through behavioral cloning, where a neural network is trained to directly predict the expert's actions given the current state of the environment.
-
Inverse Reinforcement Learning: Next, the authors use inverse reinforcement learning to learn a reward function that captures the expert's underlying objectives. This is done by finding a reward function that makes the expert's observed behavior appear near-optimal.
-
Online Adaptation: During deployment, the method fine-tunes the initial policy by using the learned reward function in a reinforcement learning setting. This allows the policy to adapt and improve its performance over time without requiring additional expert demonstrations.
The authors evaluate their approach on several simulated robotic control tasks, including robotic manipulation, legged locomotion, and autonomous driving. They show that their online adaptation method outperforms both the initial behavioral cloning policy and other state-of-the-art imitation learning approaches.
Critical Analysis
The authors acknowledge several limitations of their approach. First, the performance of the method relies on the quality of the initial behavioral cloning policy and the learned reward function. If either of these components is poor, the online adaptation may not be effective.
Additionally, the authors note that their method requires access to the environment dynamics during deployment, which may not be feasible in all real-world scenarios. This could limit the applicability of the approach in certain domains.
The paper also does not extensively explore the robustness of the method to distribution shift or changes in the task or environment. Further research would be needed to understand how well the online adaptation approach generalizes to novel situations.
Despite these limitations, the paper presents a promising approach for enhancing imitation learning policies through online adaptation. The combination of behavioral cloning and inverse reinforcement learning is an interesting and potentially impactful contribution to the field of imitation learning.
Conclusion
This paper introduces a novel method for online adaptation of imitation learning policies. By leveraging both behavioral cloning and inverse reinforcement learning, the approach can learn a reward function that can be used to fine-tune the policy during deployment, leading to improved performance over time.
The authors demonstrate the effectiveness of their method on several simulated robotic control tasks, showing that it can outperform both the initial behavioral cloning policy and other state-of-the-art imitation learning approaches. While the method has some limitations, it represents an important step forward in enhancing the capabilities of imitation learning systems.
Overall, this research contributes valuable insights to the field of imitation learning and has the potential to enable more robust and adaptable AI systems in a variety of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
Efficient Imitation Learning with Conservative World Models
Victor Kolev, Rafael Rafailov, Kyle Hatch, Jiajun Wu, Chelsea Finn
0
0
We tackle the problem of policy learning from expert demonstrations without a reward function. A central challenge in this space is that these policies fail upon deployment due to issues of distributional shift, environment stochasticity, or compounding errors. Adversarial imitation learning alleviates this issue but requires additional on-policy training samples for stability, which presents a challenge in realistic domains due to inefficient learning and high sample complexity. One approach to this issue is to learn a world model of the environment, and use synthetic data for policy training. While successful in prior works, we argue that this is sub-optimal due to additional distribution shifts between the learned model and the real environment. Instead, we re-frame imitation learning as a fine-tuning problem, rather than a pure reinforcement learning one. Drawing theoretical connections to offline RL and fine-tuning algorithms, we argue that standard online world model algorithms are not well suited to the imitation learning problem. We derive a principled conservative optimization bound and demonstrate empirically that it leads to improved performance on two very challenging manipulation environments from high-dimensional raw pixel observations. We set a new state-of-the-art performance on the Franka Kitchen environment from images, requiring only 10 demos on no reward labels, as well as solving a complex dexterity manipulation task.
5/24/2024

Hybrid Inverse Reinforcement Learning
Juntao Ren, Gokul Swamy, Zhiwei Steven Wu, J. Andrew Bagnell, Sanjiban Choudhury
0
0
The inverse reinforcement learning approach to imitation learning is a double-edged sword. On the one hand, it can enable learning from a smaller number of expert demonstrations with more robustness to error compounding than behavioral cloning approaches. On the other hand, it requires that the learner repeatedly solve a computationally expensive reinforcement learning (RL) problem. Often, much of this computation is wasted searching over policies very dissimilar to the expert's. In this work, we propose using hybrid RL -- training on a mixture of online and expert data -- to curtail unnecessary exploration. Intuitively, the expert data focuses the learner on good states during training, which reduces the amount of exploration required to compute a strong policy. Notably, such an approach doesn't need the ability to reset the learner to arbitrary states in the environment, a requirement of prior work in efficient inverse RL. More formally, we derive a reduction from inverse RL to expert-competitive RL (rather than globally optimal RL) that allows us to dramatically reduce interaction during the inner policy search loop while maintaining the benefits of the IRL approach. This allows us to derive both model-free and model-based hybrid inverse RL algorithms with strong policy performance guarantees. Empirically, we find that our approaches are significantly more sample efficient than standard inverse RL and several other baselines on a suite of continuous control tasks.
6/6/2024
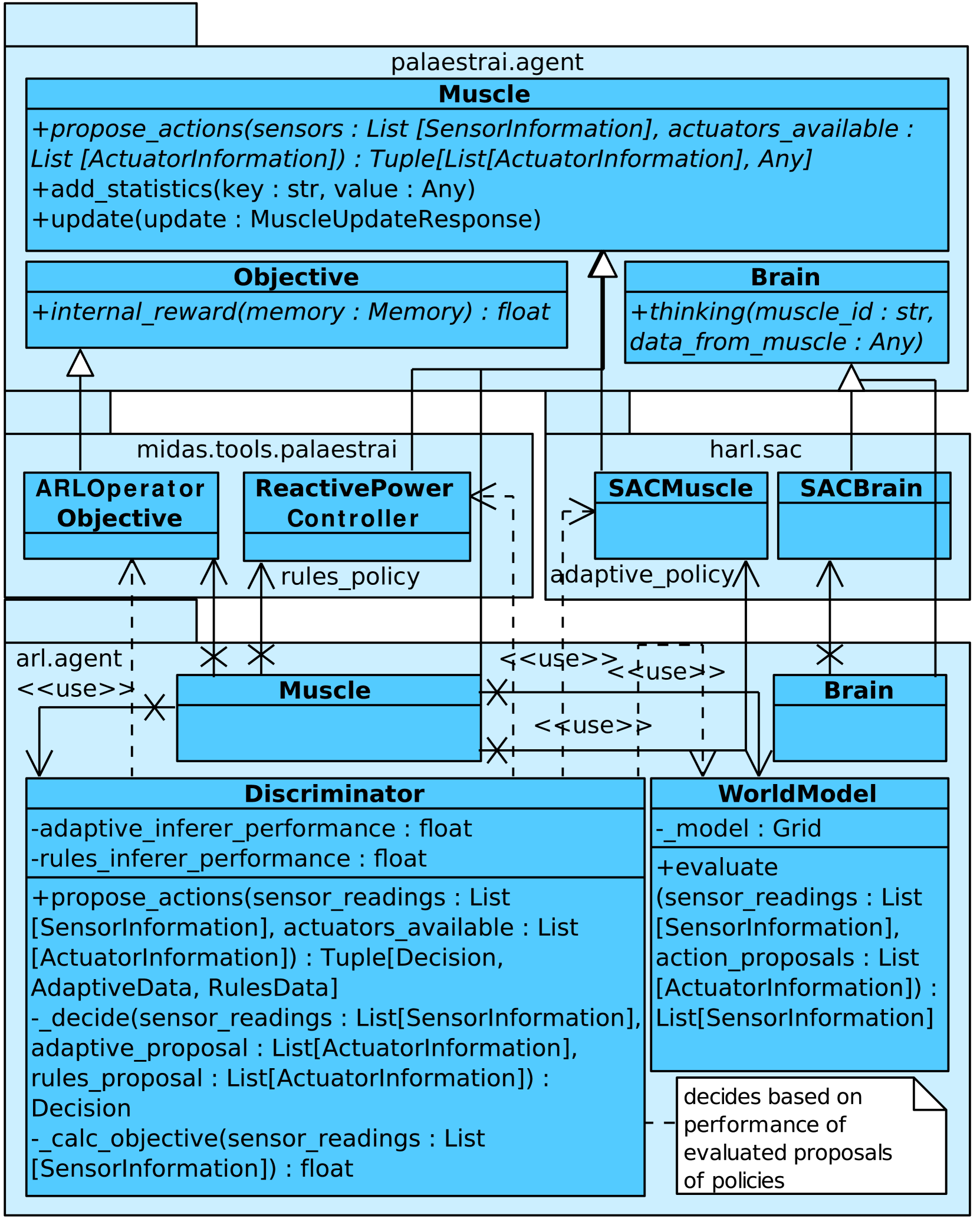
Imitation Game: A Model-based and Imitation Learning Deep Reinforcement Learning Hybrid
Eric MSP Veith, Torben Logemann, Aleksandr Berezin, Arlena Well{ss}ow, Stephan Balduin
0
0
Autonomous and learning systems based on Deep Reinforcement Learning have firmly established themselves as a foundation for approaches to creating resilient and efficient Cyber-Physical Energy Systems. However, most current approaches suffer from two distinct problems: Modern model-free algorithms such as Soft Actor Critic need a high number of samples to learn a meaningful policy, as well as a fallback to ward against concept drifts (e. g., catastrophic forgetting). In this paper, we present the work in progress towards a hybrid agent architecture that combines model-based Deep Reinforcement Learning with imitation learning to overcome both problems.
4/3/2024
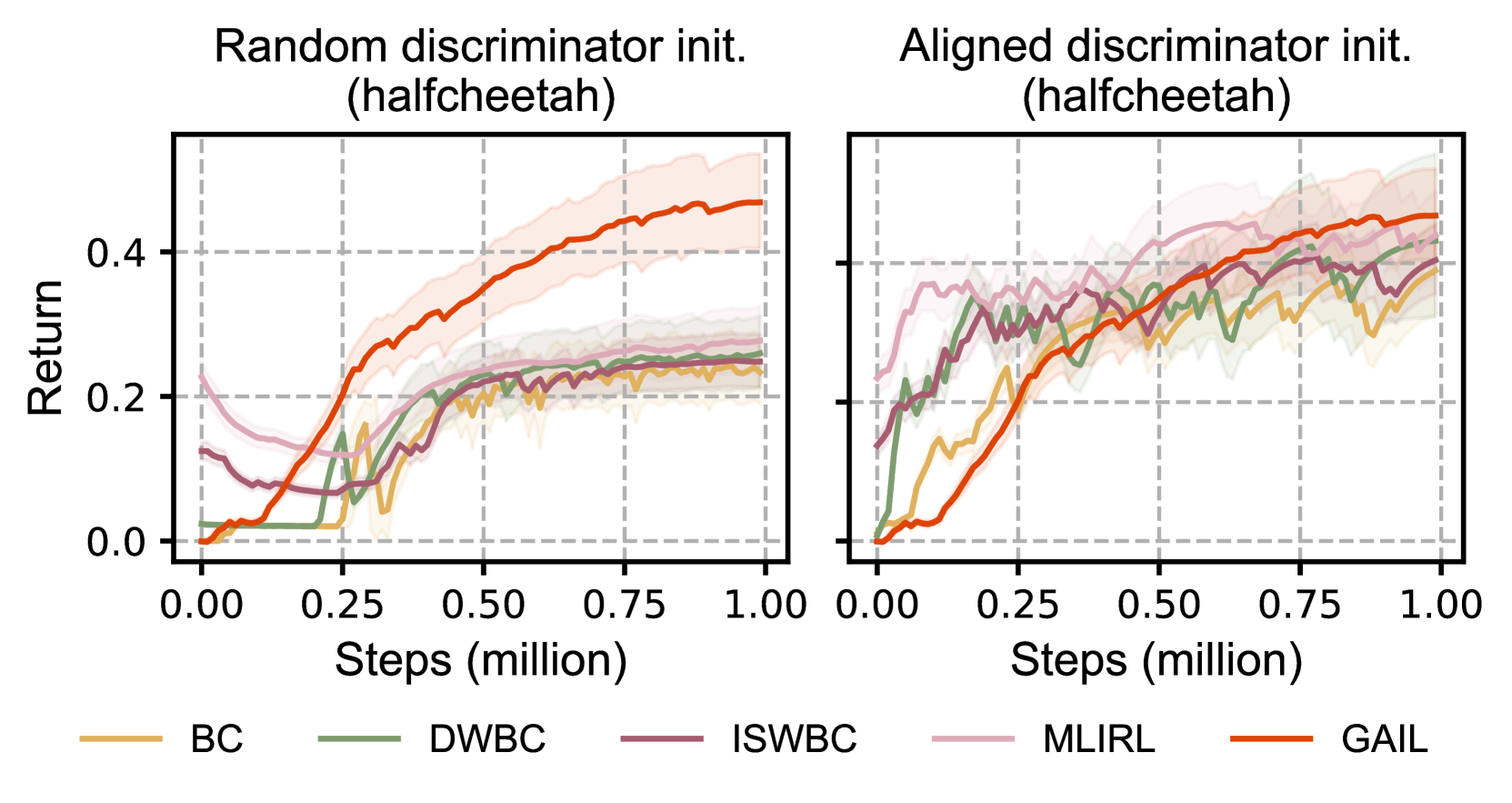
OLLIE: Imitation Learning from Offline Pretraining to Online Finetuning
Sheng Yue, Xingyuan Hua, Ju Ren, Sen Lin, Junshan Zhang, Yaoxue Zhang
0
0
In this paper, we study offline-to-online Imitation Learning (IL) that pretrains an imitation policy from static demonstration data, followed by fast finetuning with minimal environmental interaction. We find the naive combination of existing offline IL and online IL methods tends to behave poorly in this context, because the initial discriminator (often used in online IL) operates randomly and discordantly against the policy initialization, leading to misguided policy optimization and $textit{unlearning}$ of pretraining knowledge. To overcome this challenge, we propose a principled offline-to-online IL method, named $texttt{OLLIE}$, that simultaneously learns a near-expert policy initialization along with an $textit{aligned discriminator initialization}$, which can be seamlessly integrated into online IL, achieving smooth and fast finetuning. Empirically, $texttt{OLLIE}$ consistently and significantly outperforms the baseline methods in $textbf{20}$ challenging tasks, from continuous control to vision-based domains, in terms of performance, demonstration efficiency, and convergence speed. This work may serve as a foundation for further exploration of pretraining and finetuning in the context of IL.
5/31/2024