AdaMoLE: Fine-Tuning Large Language Models with Adaptive Mixture of Low-Rank Adaptation Experts
2405.00361
0
0
💬
Abstract
We introduce AdaMoLE, a novel method for fine-tuning large language models (LLMs) through an Adaptive Mixture of Low-Rank Adaptation (LoRA) Experts. Moving beyond conventional methods that employ a static top-k strategy for activating experts, AdaMoLE dynamically adjusts the activation threshold using a dedicated threshold network, adaptively responding to the varying complexities of different tasks. By replacing a single LoRA in a layer with multiple LoRA experts and integrating a gating function with the threshold mechanism, AdaMoLE effectively selects and activates the most appropriate experts based on the input context. Our extensive evaluations across a variety of commonsense reasoning and natural language processing tasks show that AdaMoLE exceeds baseline performance. This enhancement highlights the advantages of AdaMoLE's adaptive selection of LoRA experts, improving model effectiveness without a corresponding increase in the expert count. The experimental validation not only confirms AdaMoLE as a robust approach for enhancing LLMs but also suggests valuable directions for future research in adaptive expert selection mechanisms, potentially broadening the scope for optimizing model performance across diverse language processing tasks.
Create account to get full access
Overview
- Introduces AdaMoLE, a novel method for fine-tuning large language models (LLMs)
- AdaMoLE uses an Adaptive Mixture of Low-Rank Adaptation (LoRA) Experts
- Improves upon conventional methods that use a static top-k strategy for activating experts
- AdaMoLE dynamically adjusts the activation threshold using a dedicated threshold network
- Selects and activates the most appropriate experts based on the input context
Plain English Explanation
AdaMoLE is a new way to fine-tune large language models, which are AI systems trained on massive amounts of text data. Traditional fine-tuning methods use a fixed set of "experts" - specialized parts of the model - that are activated based on a predefined rule. AdaMoLE instead uses an "adaptive" approach, where the system can dynamically choose the best experts to use for a given task or input.
The key idea is to replace a single LoRA (a type of model component) in each layer with multiple LoRA experts. These experts can be selectively activated based on the input, using a special "gating" function and a "threshold" network that adjusts the activation criteria. This allows the model to better adapt to the varying complexities of different tasks, rather than relying on a one-size-fits-all approach.
The researchers found that AdaMoLE outperformed baseline methods on a variety of common sense reasoning and natural language processing tasks. This suggests that the adaptive expert selection mechanism can improve model effectiveness without needing to increase the overall number of experts.
Technical Explanation
The paper introduces AdaMoLE, a novel approach for fine-tuning large language models (LLMs) using an Adaptive Mixture of Low-Rank Adaptation (LoRA) Experts. Unlike conventional methods that employ a static top-k strategy for activating experts, AdaMoLE dynamically adjusts the activation threshold using a dedicated threshold network. This allows the system to adaptively respond to the varying complexities of different tasks.
AdaMoLE replaces a single LoRA in each layer with multiple LoRA experts and integrates a gating function with the threshold mechanism. This enables the model to effectively select and activate the most appropriate experts based on the input context. The researchers evaluated AdaMoLE across a variety of commonsense reasoning and natural language processing tasks, finding that it exceeds baseline performance.
The experimental validation confirms AdaMoLE as a robust approach for enhancing LLMs, highlighting the advantages of its adaptive selection of LoRA experts. This improvement is achieved without a corresponding increase in the expert count, suggesting valuable directions for future research in adaptive expert selection mechanisms, potentially broadening the scope for optimizing model performance across diverse language processing tasks.
Critical Analysis
The paper presents a compelling approach to fine-tuning large language models, but it's important to consider some potential limitations and areas for further research.
One potential concern is the computational overhead introduced by the dynamic threshold network and gating function. While the authors report that AdaMoLE does not significantly increase the overall parameter count, the additional components may add to the model's complexity and inference time. Further analysis of the model's efficiency and scalability would be valuable.
Additionally, the paper focuses on a limited set of commonsense reasoning and natural language processing tasks. It would be interesting to see how AdaMoLE performs on a broader range of language tasks, including those that may require more specialized or contextual expertise.
The authors also acknowledge that the adaptive expert selection mechanism could potentially lead to instability or overfitting if not properly regularized. Exploring more sophisticated techniques for managing the expert mixture and threshold dynamics could be an area for future research.
Overall, the AdaMoLE approach is a promising step forward in enhancing the fine-tuning of large language models, but additional work is needed to fully understand its strengths, limitations, and potential applications.
Conclusion
AdaMoLE introduces a novel method for fine-tuning large language models that goes beyond conventional static expert activation strategies. By dynamically adjusting the activation threshold and selectively engaging the most appropriate LoRA experts based on the input context, AdaMoLE demonstrates improved performance on a variety of commonsense reasoning and natural language processing tasks.
This research highlights the potential benefits of adaptive expert selection mechanisms, which could lead to more efficient and effective fine-tuning of large language models. As the field of natural language processing continues to evolve, techniques like AdaMoLE may contribute to the development of more versatile and adaptable AI systems capable of tackling an increasingly diverse range of language-related challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA based Mixture of Experts
Dengchun Li, Yingzi Ma, Naizheng Wang, Zhengmao Ye, Zhiyuan Cheng, Yinghao Tang, Yan Zhang, Lei Duan, Jie Zuo, Cal Yang, Mingjie Tang
0
0
Fine-tuning Large Language Models (LLMs) is a common practice to adapt pre-trained models for specific applications. While methods like LoRA have effectively addressed GPU memory constraints during fine-tuning, their performance often falls short, especially in multi-task scenarios. In contrast, Mixture-of-Expert (MoE) models, such as Mixtral 8x7B, demonstrate remarkable performance in multi-task learning scenarios while maintaining a reduced parameter count. However, the resource requirements of these MoEs remain challenging, particularly for consumer-grade GPUs with less than 24GB memory. To tackle these challenges, we propose MixLoRA, an approach to construct a resource-efficient sparse MoE model based on LoRA. MixLoRA inserts multiple LoRA-based experts within the feed-forward network block of a frozen pre-trained dense model and employs a commonly used top-k router. Unlike other LoRA-based MoE methods, MixLoRA enhances model performance by utilizing independent attention-layer LoRA adapters. Additionally, an auxiliary load balance loss is employed to address the imbalance problem of the router. Our evaluations show that MixLoRA improves about 9% accuracy compared to state-of-the-art PEFT methods in multi-task learning scenarios. We also propose a new high-throughput framework to alleviate the computation and memory bottlenecks during the training and inference of MOE models. This framework reduces GPU memory consumption by 40% and token computation latency by 30% during both training and inference.
5/24/2024

Mixture of LoRA Experts
Xun Wu, Shaohan Huang, Furu Wei
0
0
LoRA has gained widespread acceptance in the fine-tuning of large pre-trained models to cater to a diverse array of downstream tasks, showcasing notable effectiveness and efficiency, thereby solidifying its position as one of the most prevalent fine-tuning techniques. Due to the modular nature of LoRA's plug-and-play plugins, researchers have delved into the amalgamation of multiple LoRAs to empower models to excel across various downstream tasks. Nonetheless, extant approaches for LoRA fusion grapple with inherent challenges. Direct arithmetic merging may result in the loss of the original pre-trained model's generative capabilities or the distinct identity of LoRAs, thereby yielding suboptimal outcomes. On the other hand, Reference tuning-based fusion exhibits limitations concerning the requisite flexibility for the effective combination of multiple LoRAs. In response to these challenges, this paper introduces the Mixture of LoRA Experts (MoLE) approach, which harnesses hierarchical control and unfettered branch selection. The MoLE approach not only achieves superior LoRA fusion performance in comparison to direct arithmetic merging but also retains the crucial flexibility for combining LoRAs effectively. Extensive experimental evaluations conducted in both the Natural Language Processing (NLP) and Vision & Language (V&L) domains substantiate the efficacy of MoLE.
4/23/2024
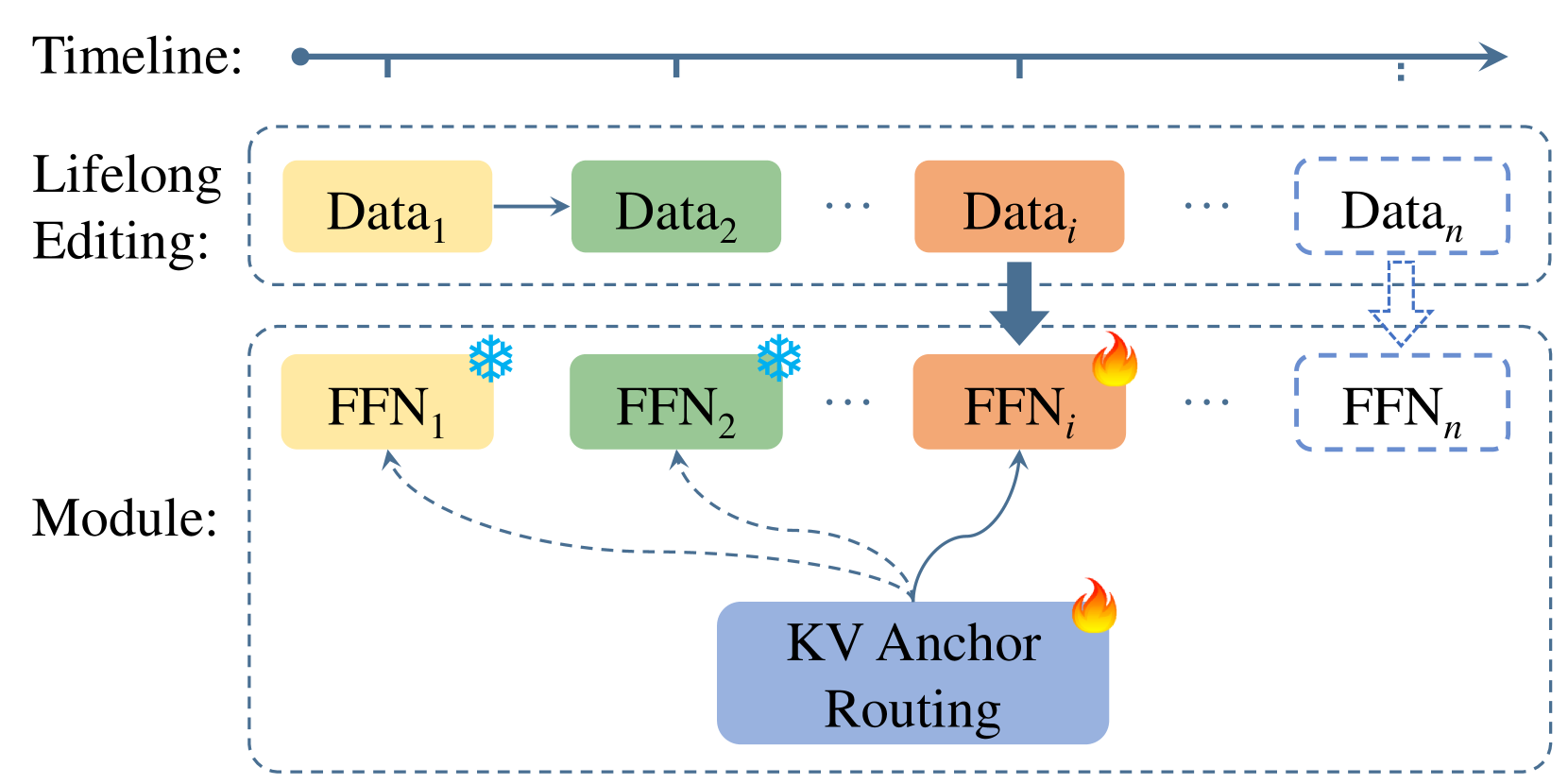
New!LEMoE: Advanced Mixture of Experts Adaptor for Lifelong Model Editing of Large Language Models
Renzhi Wang, Piji Li
0
0
Large language models (LLMs) require continual knowledge updates to stay abreast of the ever-changing world facts, prompting the formulation of lifelong model editing task. While recent years have witnessed the development of various techniques for single and batch editing, these methods either fail to apply or perform sub-optimally when faced with lifelong editing. In this paper, we introduce LEMoE, an advanced Mixture of Experts (MoE) adaptor for lifelong model editing. We first analyze the factors influencing the effectiveness of conventional MoE adaptor in lifelong editing, including catastrophic forgetting, inconsistent routing and order sensitivity. Based on these insights, we propose a tailored module insertion method to achieve lifelong editing, incorporating a novel KV anchor routing to enhance routing consistency between training and inference stage, along with a concise yet effective clustering-based editing order planning. Experimental results demonstrate the effectiveness of our method in lifelong editing, surpassing previous model editing techniques while maintaining outstanding performance in batch editing task. Our code will be available.
7/1/2024

AdaMoE: Token-Adaptive Routing with Null Experts for Mixture-of-Experts Language Models
Zihao Zeng, Yibo Miao, Hongcheng Gao, Hao Zhang, Zhijie Deng
0
0
Mixture of experts (MoE) has become the standard for constructing production-level large language models (LLMs) due to its promise to boost model capacity without causing significant overheads. Nevertheless, existing MoE methods usually enforce a constant top-k routing for all tokens, which is arguably restrictive because various tokens (e.g., vs. apple) may require various numbers of experts for feature abstraction. Lifting such a constraint can help make the most of limited resources and unleash the potential of the model for downstream tasks. In this sense, we introduce AdaMoE to realize token-adaptive routing for MoE, where different tokens are permitted to select a various number of experts. AdaMoE makes minimal modifications to the vanilla MoE with top-k routing -- it simply introduces a fixed number of null experts, which do not consume any FLOPs, to the expert set and increases the value of k. AdaMoE does not force each token to occupy a fixed number of null experts but ensures the average usage of the null experts with a load-balancing loss, leading to an adaptive number of null/true experts used by each token. AdaMoE exhibits a strong resemblance to MoEs with expert choice routing while allowing for trivial auto-regressive modeling. AdaMoE is easy to implement and can be effectively applied to pre-trained (MoE-)LLMs. Extensive studies show that AdaMoE can reduce average expert load (FLOPs) while achieving superior performance. For example, on the ARC-C dataset, applying our method to fine-tuning Mixtral-8x7B can reduce FLOPs by 14.5% while increasing accuracy by 1.69%.
6/21/2024