AdapMTL: Adaptive Pruning Framework for Multitask Learning Model

0

Sign in to get full access
Overview
- Proposes a novel adaptive pruning framework called AdapMTL for multitask learning models
- Aims to improve the efficiency and performance of multitask learning models by selectively pruning redundant model components
- Utilizes a dynamic importance score to guide the pruning process and adapt to task-specific requirements
Plain English Explanation
The paper introduces a technique called AdapMTL that helps make multitask learning models more efficient and effective. Multitask learning is when a single model is trained to perform multiple tasks, like recognizing images and translating text. However, this can lead to a bloated model with redundant components.
AdapMTL solves this by adaptively pruning the model - removing parts of it that aren't contributing much to the overall performance. It uses a "dynamic importance score" to figure out which parts of the model are most valuable for each task, and then selectively removes the least important parts. This helps streamline the model, making it faster and more efficient without sacrificing accuracy.
The key idea is to tailor the model to the specific requirements of each task, rather than having a one-size-fits-all approach. By pruning the model in an adaptive way, AdapMTL can improve the overall performance and efficiency of multitask learning systems.
Technical Explanation
The paper proposes the AdapMTL framework, which adaptively prunes a multitask learning model to improve its efficiency and performance. The core idea is to identify and remove redundant model components that are not critical to the overall multitask learning objective.
AdapMTL introduces a dynamic importance score that is used to guide the pruning process. This score reflects the relative importance of each model parameter for the different tasks being learned. Parameters with low importance scores are considered redundant and can be safely removed without significantly impacting model performance.
The pruning process in AdapMTL is iterative and task-specific. At each iteration, the importance scores are recomputed, and the least important parameters are pruned. This allows the framework to adapt to the specific requirements of each task, avoiding a one-size-fits-all approach.
The authors evaluate AdapMTL on several multitask learning benchmarks, including image classification and natural language processing tasks. The results show that AdapMTL can significantly reduce the model size (up to 90%) while maintaining or even improving the overall performance compared to the original multitask learning model.
Critical Analysis
The paper presents a promising approach to improving the efficiency of multitask learning models, but there are a few potential limitations and areas for further research:
-
Generalization to Diverse Multitask Settings: The evaluation in the paper is limited to a few specific multitask learning benchmarks. It would be valuable to assess the performance of AdapMTL on a wider range of multitask learning problems, including those with more diverse task types and data modalities.
-
Computational Overhead: The iterative pruning process in AdapMTL may introduce additional computational overhead, which could offset the benefits of the reduced model size. The authors should investigate the trade-offs between the pruning cost and the runtime efficiency gains.
-
Interpretability of Importance Scores: The dynamic importance scores used to guide the pruning process are not easily interpretable. It would be helpful to provide more insight into what these scores represent and how they relate to the task-specific requirements.
-
Interactions Between Pruned Components: The paper does not explore the potential interactions between the pruned model components and how this might affect the overall performance. Further analysis could shed light on the underlying mechanisms behind the success of the adaptive pruning approach.
Despite these potential areas for improvement, the AdapMTL framework represents an important step forward in making multitask learning models more efficient and practical for real-world applications.
Conclusion
The AdapMTL framework proposed in this paper offers a novel approach to improving the efficiency and performance of multitask learning models. By adaptively pruning redundant model components based on a dynamic importance score, AdapMTL can significantly reduce the model size while maintaining or even improving the overall multitask learning performance.
This work highlights the importance of tailoring machine learning models to the specific requirements of each task, rather than relying on a one-size-fits-all approach. The adaptive pruning technique used in AdapMTL could have broader implications for the design and optimization of efficient and effective deep learning models, especially in resource-constrained environments.
Future research directions could include exploring the generalization of AdapMTL to a wider range of multitask learning problems, investigating the computational trade-offs of the pruning process, and providing more interpretability into the importance score calculations. Overall, the AdapMTL framework represents an important contribution to the field of multitask learning and model efficiency optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AdapMTL: Adaptive Pruning Framework for Multitask Learning Model
Mingcan Xiang, Steven Jiaxun Tang, Qizheng Yang, Hui Guan, Tongping Liu
In the domain of multimedia and multimodal processing, the efficient handling of diverse data streams such as images, video, and sensor data is paramount. Model compression and multitask learning (MTL) are crucial in this field, offering the potential to address the resource-intensive demands of processing and interpreting multiple forms of media simultaneously. However, effectively compressing a multitask model presents significant challenges due to the complexities of balancing sparsity allocation and accuracy performance across multiple tasks. To tackle these challenges, we propose AdapMTL, an adaptive pruning framework for MTL models. AdapMTL leverages multiple learnable soft thresholds independently assigned to the shared backbone and the task-specific heads to capture the nuances in different components' sensitivity to pruning. During training, it co-optimizes the soft thresholds and MTL model weights to automatically determine the suitable sparsity level at each component to achieve both high task accuracy and high overall sparsity. It further incorporates an adaptive weighting mechanism that dynamically adjusts the importance of task-specific losses based on each task's robustness to pruning. We demonstrate the effectiveness of AdapMTL through comprehensive experiments on popular multitask datasets, namely NYU-v2 and Tiny-Taskonomy, with different architectures, showcasing superior performance compared to state-of-the-art pruning methods.
Read more8/9/2024
📈
0
AdaMerging: Adaptive Model Merging for Multi-Task Learning
Enneng Yang, Zhenyi Wang, Li Shen, Shiwei Liu, Guibing Guo, Xingwei Wang, Dacheng Tao
Multi-task learning (MTL) aims to empower a model to tackle multiple tasks simultaneously. A recent development known as task arithmetic has revealed that several models, each fine-tuned for distinct tasks, can be directly merged into a single model to execute MTL without necessitating a retraining process using the initial training data. Nevertheless, this direct addition of models often leads to a significant deterioration in the overall performance of the merged model. This decline occurs due to potential conflicts and intricate correlations among the multiple tasks. Consequently, the challenge emerges of how to merge pre-trained models more effectively without using their original training data. This paper introduces an innovative technique called Adaptive Model Merging (AdaMerging). This approach aims to autonomously learn the coefficients for model merging, either in a task-wise or layer-wise manner, without relying on the original training data. Specifically, our AdaMerging method operates as an automatic, unsupervised task arithmetic scheme. It leverages entropy minimization on unlabeled test samples from the multi-task setup as a surrogate objective function to iteratively refine the merging coefficients of the multiple models. Our experimental findings across eight tasks demonstrate the efficacy of the AdaMerging scheme we put forth. Compared to the current state-of-the-art task arithmetic merging scheme, AdaMerging showcases a remarkable 11% improvement in performance. Notably, AdaMerging also exhibits superior generalization capabilities when applied to unseen downstream tasks. Furthermore, it displays a significantly enhanced robustness to data distribution shifts that may occur during the testing phase.
Read more5/29/2024
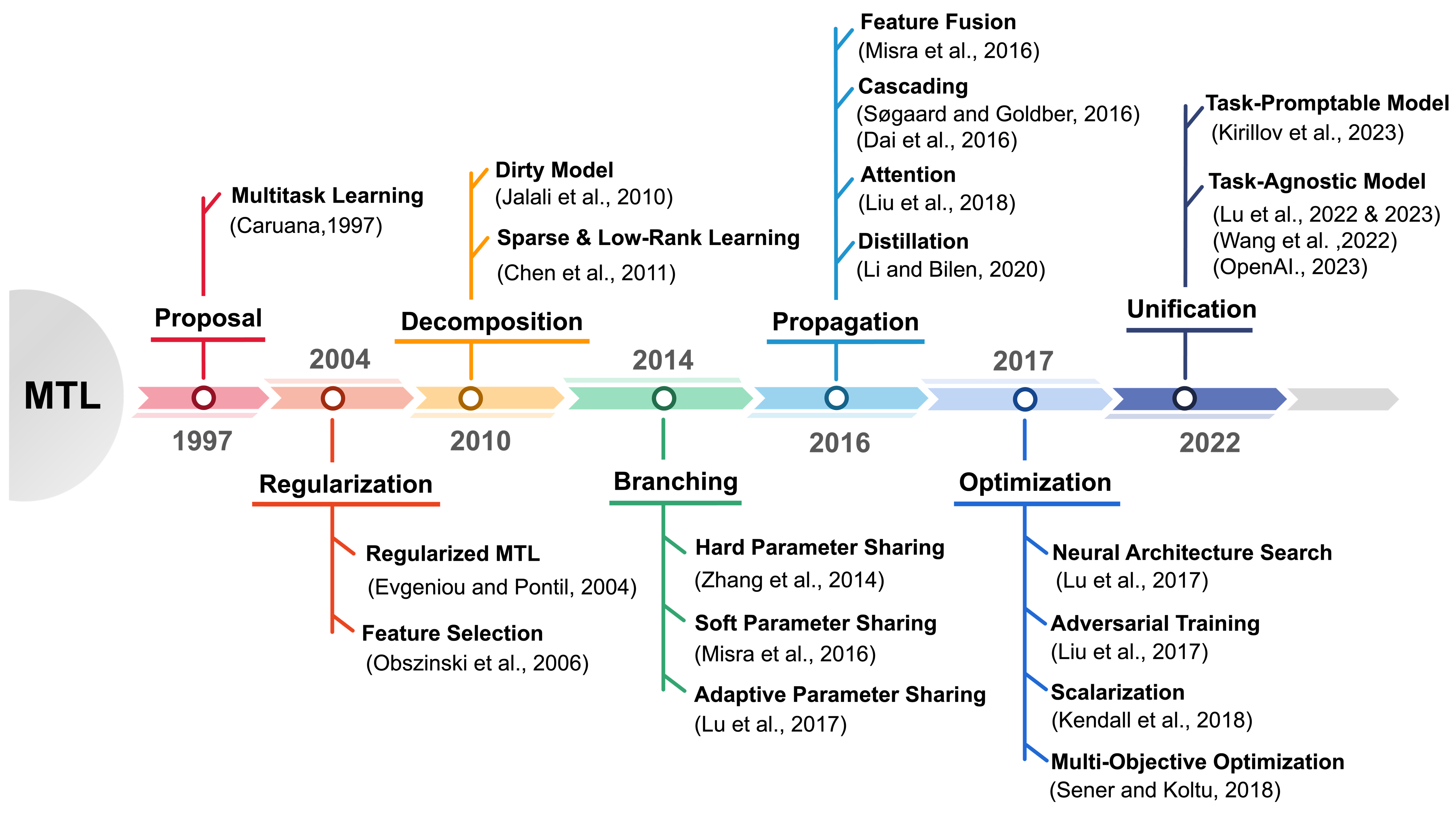
0
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Jun Yu, Yutong Dai, Xiaokang Liu, Jin Huang, Yishan Shen, Ke Zhang, Rong Zhou, Eashan Adhikarla, Wenxuan Ye, Yixin Liu, Zhaoming Kong, Kai Zhang, Yilong Yin, Vinod Namboodiri, Brian D. Davison, Jason H. Moore, Yong Chen
MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
Read more5/1/2024

0
Giving each task what it needs -- leveraging structured sparsity for tailored multi-task learning
Richa Upadhyay, Ronald Phlypo, Rajkumar Saini, Marcus Liwicki
In the Multi-task Learning (MTL) framework, every task demands distinct feature representations, ranging from low-level to high-level attributes. It is vital to address the specific (feature/parameter) needs of each task, especially in computationally constrained environments. This work, therefore, introduces Layer-Optimized Multi-Task (LOMT) models that utilize structured sparsity to refine feature selection for individual tasks and enhance the performance of all tasks in a multi-task scenario. Structured or group sparsity systematically eliminates parameters from trivial channels and, sometimes, eventually, entire layers within a convolution neural network during training. Consequently, the remaining layers provide the most optimal features for a given task. In this two-step approach, we subsequently leverage this sparsity-induced optimal layer information to build the LOMT models by connecting task-specific decoders to these strategically identified layers, deviating from conventional approaches that uniformly connect decoders at the end of the network. This tailored architecture optimizes the network, focusing on essential features while reducing redundancy. We validate the efficacy of the proposed approach on two datasets, i.e., NYU-v2 and CelebAMask-HD datasets, for multiple heterogeneous tasks. A detailed performance analysis of the LOMT models, in contrast to the conventional MTL models, reveals that the LOMT models outperform for most task combinations. The excellent qualitative and quantitative outcomes highlight the effectiveness of employing structured sparsity for optimal layer (or feature) selection.
Read more9/6/2024