AdaMerging: Adaptive Model Merging for Multi-Task Learning
2310.02575
0
0
📈
Abstract
Multi-task learning (MTL) aims to empower a model to tackle multiple tasks simultaneously. A recent development known as task arithmetic has revealed that several models, each fine-tuned for distinct tasks, can be directly merged into a single model to execute MTL without necessitating a retraining process using the initial training data. Nevertheless, this direct addition of models often leads to a significant deterioration in the overall performance of the merged model. This decline occurs due to potential conflicts and intricate correlations among the multiple tasks. Consequently, the challenge emerges of how to merge pre-trained models more effectively without using their original training data. This paper introduces an innovative technique called Adaptive Model Merging (AdaMerging). This approach aims to autonomously learn the coefficients for model merging, either in a task-wise or layer-wise manner, without relying on the original training data. Specifically, our AdaMerging method operates as an automatic, unsupervised task arithmetic scheme. It leverages entropy minimization on unlabeled test samples from the multi-task setup as a surrogate objective function to iteratively refine the merging coefficients of the multiple models. Our experimental findings across eight tasks demonstrate the efficacy of the AdaMerging scheme we put forth. Compared to the current state-of-the-art task arithmetic merging scheme, AdaMerging showcases a remarkable 11% improvement in performance. Notably, AdaMerging also exhibits superior generalization capabilities when applied to unseen downstream tasks. Furthermore, it displays a significantly enhanced robustness to data distribution shifts that may occur during the testing phase.
Create account to get full access
Overview
- The paper introduces a new technique called Adaptive Model Merging (AdaMerging) for combining pre-trained models to perform multi-task learning (MTL) without the need for retraining on the original data.
- Traditional methods of directly merging pre-trained models often lead to a significant decline in overall performance due to conflicts and correlations between the tasks.
- AdaMerging aims to autonomously learn the optimal coefficients for merging the pre-trained models, either at the task-level or layer-level, without relying on the original training data.
Plain English Explanation
The paper presents a solution to a problem in multi-task learning. Multi-task learning is when a machine learning model is trained to perform multiple tasks at once, like image classification and language translation. This can be more efficient than training separate models for each task.
A recent development called "task arithmetic" showed that you can combine multiple pre-trained models, each specialized for a different task, into a single multi-task model. However, simply adding these pre-trained models together often leads to a drop in the overall performance of the combined model.
The reason for this performance decline is that the different tasks can conflict with or be closely related to each other in complex ways. The paper introduces a new technique called AdaMerging that can automatically figure out the best way to combine the pre-trained models without needing the original training data.
AdaMerging works by learning the optimal "coefficients" or weights for merging the pre-trained models, either at the level of individual tasks or individual layers in the models. It does this in an unsupervised way, using only unlabeled test samples from the multi-task setup.
The experiments in the paper show that AdaMerging can significantly outperform other state-of-the-art task arithmetic methods, with an 11% improvement in performance. It also demonstrates better generalization to new, unseen tasks and is more robust to changes in the data distribution during testing.
Technical Explanation
The paper proposes an innovative technique called Adaptive Model Merging (AdaMerging) to address the challenge of effectively combining pre-trained models for multi-task learning (MTL) without access to the original training data.
Traditional methods of directly adding pre-trained models, known as "task arithmetic", often lead to a significant drop in the overall performance of the merged model. This occurs due to potential conflicts and complex correlations between the multiple tasks involved in the MTL setup.
AdaMerging aims to autonomously learn the optimal coefficients for merging the pre-trained models, either in a task-wise or layer-wise manner, without relying on the original training data. The key insight is to leverage entropy minimization on unlabeled test samples from the multi-task setup as a surrogate objective function to iteratively refine the merging coefficients.
The experimental results across eight tasks demonstrate the effectiveness of the AdaMerging approach. Compared to the current state-of-the-art task arithmetic merging scheme, AdaMerging achieves a remarkable 11% improvement in performance. Additionally, AdaMerging exhibits superior generalization capabilities when applied to unseen downstream tasks and shows enhanced robustness to data distribution shifts that may occur during the testing phase.
Critical Analysis
The paper presents a compelling solution to the challenge of effectively combining pre-trained models for multi-task learning without access to the original training data. The proposed AdaMerging technique addresses a significant limitation of existing task arithmetic methods, which often lead to performance degradation due to conflicts and correlations between the tasks.
One potential caveat is that the paper focuses primarily on evaluating AdaMerging on a limited set of eight tasks. While the results are promising, it would be valuable to see how the technique scales and performs when applied to a wider range of multi-task setups, including those with a larger number of tasks and more complex relationships between them.
Additionally, the paper does not provide a deep analysis of the underlying reasons why AdaMerging is able to outperform other task arithmetic methods. Further investigation into the specific mechanisms and properties of the entropy minimization objective function used by AdaMerging could yield valuable insights into its strengths and potential limitations.
Future research could also explore the integration of AdaMerging with other multi-task learning techniques, such as task grouping or cross-stitch networks, to further enhance its performance and versatility.
Conclusion
The paper introduces a novel Adaptive Model Merging (AdaMerging) technique that enables the effective combination of pre-trained models for multi-task learning without the need for retraining on the original data. By autonomously learning the optimal merging coefficients through an entropy minimization objective, AdaMerging overcomes the performance degradation often encountered with traditional task arithmetic methods.
The experimental results demonstrate the efficacy of AdaMerging, with an impressive 11% improvement in performance compared to the state-of-the-art. Notably, AdaMerging also exhibits superior generalization capabilities and enhanced robustness to data distribution shifts, making it a promising approach for real-world multi-task learning applications.
The AdaMerging technique represents a significant advancement in the field of multi-task learning, paving the way for more efficient and versatile model development and deployment, without the need for resource-intensive retraining processes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MetaGPT: Merging Large Language Models Using Model Exclusive Task Arithmetic
Yuyan Zhou, Liang Song, Bingning Wang, Weipeng Chen
0
0
The advent of large language models (LLMs) like GPT-4 has catalyzed the exploration of multi-task learning (MTL), in which a single model demonstrates proficiency across diverse tasks. Task arithmetic has emerged as a cost-effective approach for MTL. It enables performance enhancement across multiple tasks by adding their corresponding task vectors to a pre-trained model. However, the current lack of a method that can simultaneously achieve optimal performance, computational efficiency, and data privacy limits their application to LLMs. In this paper, we propose textbf{M}odel textbf{E}xclusive textbf{T}ask textbf{A}rithmetic for merging textbf{GPT}-scale models, which formalizes the objective of model merging into a multi-task learning framework, aiming to minimize the average loss difference between the merged model and each individual task model. Since data privacy limits the use of multi-task training data, we leverage LLMs' local linearity and task vectors' orthogonality to separate the data term and scaling coefficients term and derive a model-exclusive task arithmetic method. Our proposed MetaGPT is data-agnostic and bypasses the heavy search process, making it cost-effective and easy to implement for LLMs.Extensive experiments demonstrate that MetaGPT leads to improvements in task arithmetic and achieves state-of-the-art performance on multiple tasks.
6/28/2024

Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging
Zhenyi Lu, Chenghao Fan, Wei Wei, Xiaoye Qu, Dangyang Chen, Yu Cheng
0
0
In the era of large language models, model merging is a promising way to combine multiple task-specific models into a single multitask model without extra training. However, two challenges remain: (a) interference between different models and (b) heterogeneous data during testing. Traditional model merging methods often show significant performance gaps compared to fine-tuned models due to these issues. Additionally, a one-size-fits-all model lacks flexibility for diverse test data, leading to performance degradation. We show that both shared and exclusive task-specific knowledge are crucial for merging performance, but directly merging exclusive knowledge hinders overall performance. In view of this, we propose Twin-Merging, a method that encompasses two principal stages: (1) modularizing knowledge into shared and exclusive components, with compression to reduce redundancy and enhance efficiency; (2) dynamically merging shared and task-specific knowledge based on the input. This approach narrows the performance gap between merged and fine-tuned models and improves adaptability to heterogeneous data. Extensive experiments on $12$ datasets for both discriminative and generative tasks demonstrate the effectiveness of our method, showing an average improvement of $28.34%$ in absolute normalized score for discriminative tasks and even surpassing the fine-tuned upper bound on the generative tasks. (Our implementation is available in https://github.com/LZY-the-boys/Twin-Mergin.)
6/26/2024
Unleashing the Power of Multi-Task Learning: A Comprehensive Survey Spanning Traditional, Deep, and Pretrained Foundation Model Eras
Jun Yu, Yutong Dai, Xiaokang Liu, Jin Huang, Yishan Shen, Ke Zhang, Rong Zhou, Eashan Adhikarla, Wenxuan Ye, Yixin Liu, Zhaoming Kong, Kai Zhang, Yilong Yin, Vinod Namboodiri, Brian D. Davison, Jason H. Moore, Yong Chen
0
0
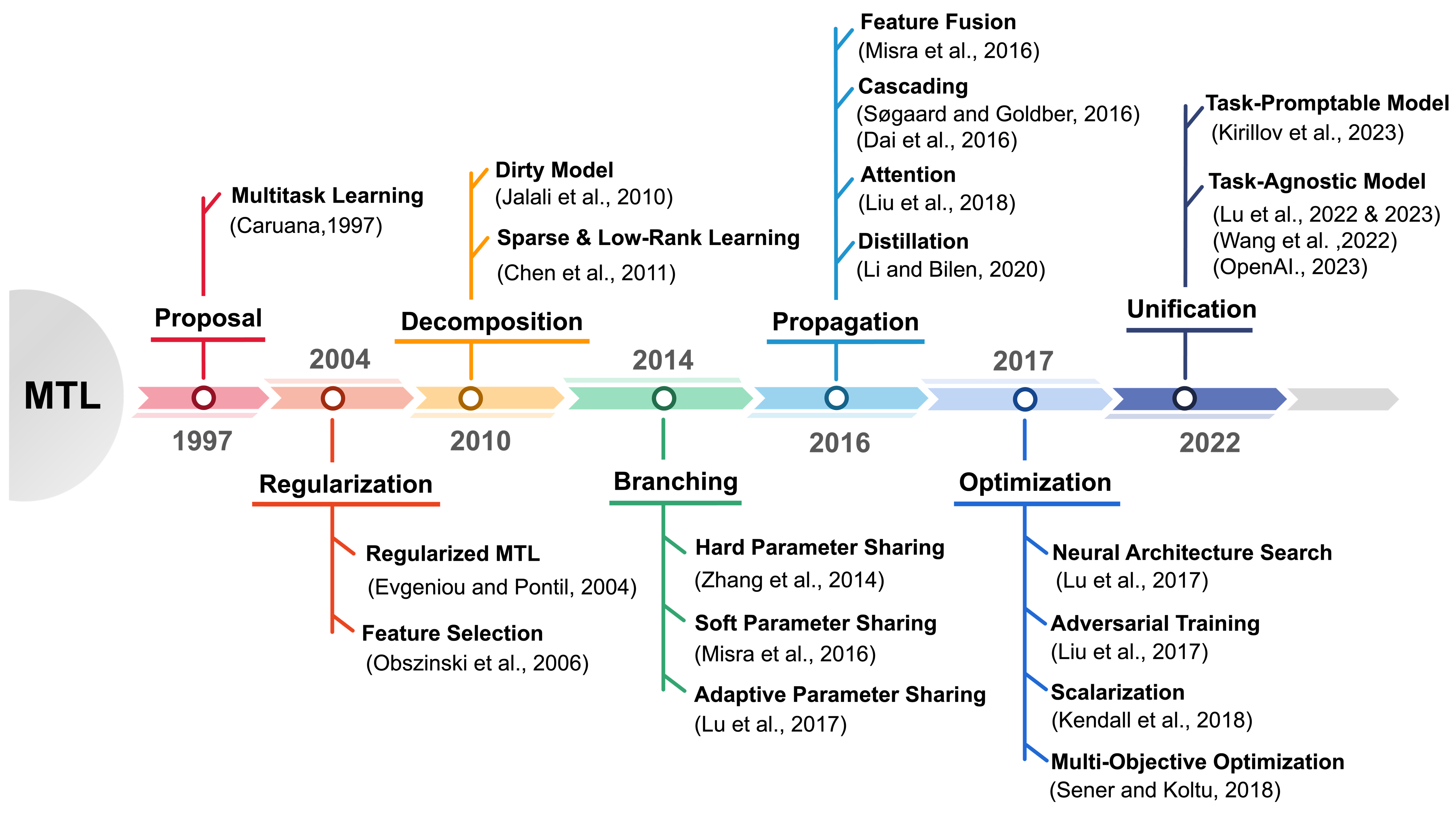
MTL is a learning paradigm that effectively leverages both task-specific and shared information to address multiple related tasks simultaneously. In contrast to STL, MTL offers a suite of benefits that enhance both the training process and the inference efficiency. MTL's key advantages encompass streamlined model architecture, performance enhancement, and cross-domain generalizability. Over the past twenty years, MTL has become widely recognized as a flexible and effective approach in various fields, including CV, NLP, recommendation systems, disease prognosis and diagnosis, and robotics. This survey provides a comprehensive overview of the evolution of MTL, encompassing the technical aspects of cutting-edge methods from traditional approaches to deep learning and the latest trend of pretrained foundation models. Our survey methodically categorizes MTL techniques into five key areas: regularization, relationship learning, feature propagation, optimization, and pre-training. This categorization not only chronologically outlines the development of MTL but also dives into various specialized strategies within each category. Furthermore, the survey reveals how the MTL evolves from handling a fixed set of tasks to embracing a more flexible approach free from task or modality constraints. It explores the concepts of task-promptable and -agnostic training, along with the capacity for ZSL, which unleashes the untapped potential of this historically coveted learning paradigm. Overall, we hope this survey provides the research community with a comprehensive overview of the advancements in MTL from its inception in 1997 to the present in 2023. We address present challenges and look ahead to future possibilities, shedding light on the opportunities and potential avenues for MTL research in a broad manner. This project is publicly available at https://github.com/junfish/Awesome-Multitask-Learning.
5/1/2024
Merging Multi-Task Models via Weight-Ensembling Mixture of Experts
Anke Tang, Li Shen, Yong Luo, Nan Yin, Lefei Zhang, Dacheng Tao
0
0
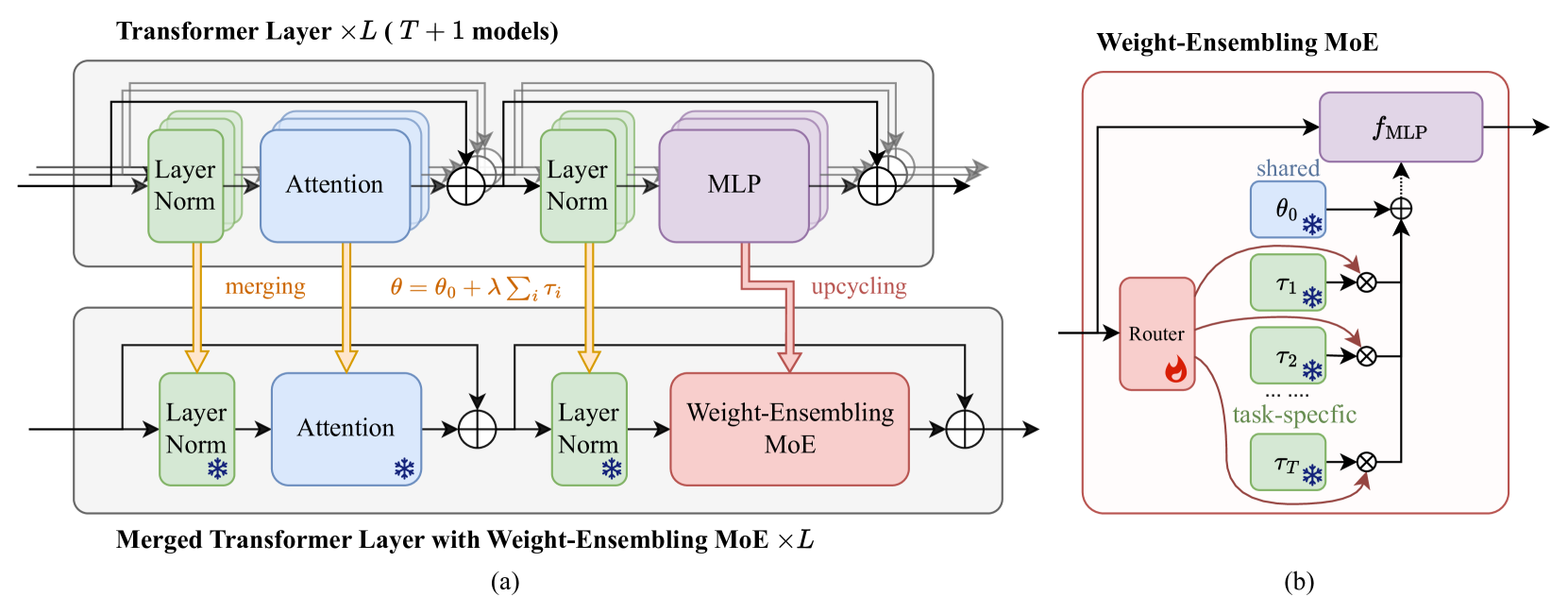
Merging various task-specific Transformer-based models trained on different tasks into a single unified model can execute all the tasks concurrently. Previous methods, exemplified by task arithmetic, have been proven to be both effective and scalable. Existing methods have primarily focused on seeking a static optimal solution within the original model parameter space. A notable challenge is mitigating the interference between parameters of different models, which can substantially deteriorate performance. In this paper, we propose to merge most of the parameters while upscaling the MLP of the Transformer layers to a weight-ensembling mixture of experts (MoE) module, which can dynamically integrate shared and task-specific knowledge based on the input, thereby providing a more flexible solution that can adapt to the specific needs of each instance. Our key insight is that by identifying and separating shared knowledge and task-specific knowledge, and then dynamically integrating them, we can mitigate the parameter interference problem to a great extent. We conduct the conventional multi-task model merging experiments and evaluate the generalization and robustness of our method. The results demonstrate the effectiveness of our method and provide a comprehensive understanding of our method. The code is available at https://github.com/tanganke/weight-ensembling_MoE
6/10/2024