Adapters Mixup: Mixing Parameter-Efficient Adapters to Enhance the Adversarial Robustness of Fine-tuned Pre-trained Text Classifiers

0
Sign in to get full access
Overview
- This paper proposes a novel approach to enhance the adversarial robustness of pre-trained language models for text classification tasks.
- The method combines two techniques: Adapters and Mixup, which are used to efficiently fine-tune the models while improving their robustness to adversarial attacks.
Plain English Explanation
The paper focuses on making pre-trained language models, like the ones used for tasks like text classification, more resistant to adversarial attacks. Adversarial attacks are when small, carefully crafted changes are made to the input text that can trick the model into making incorrect predictions, even though the text looks normal to humans.
The researchers use two techniques to address this problem. The first is called Adapters, which allows the model to be fine-tuned for a specific task using only a small number of additional parameters, rather than having to update the entire model. This makes the fine-tuning process more efficient.
The second technique is called Mixup, which is a data augmentation method that creates new training examples by combining (or "mixing up") existing ones. This helps the model learn more robust features and become less sensitive to small changes in the input.
By combining these two techniques, the researchers were able to create a method that can efficiently fine-tune pre-trained language models to be more robust against adversarial attacks, without having to completely retrain the entire model from scratch.
Technical Explanation
The paper proposes a method called "Marrying Adapters and Mixup" (MAAM) to enhance the adversarial robustness of pre-trained language models for text classification tasks. MAAM leverages two key techniques:
-
Adapters: Adapters are small neural network layers that can be inserted into pre-trained models to enable efficient fine-tuning for specific tasks, without having to update the entire model. This makes the fine-tuning process more parameter-efficient.
-
Mixup: Mixup is a data augmentation technique that creates new training examples by linearly combining pairs of existing examples and their corresponding labels. This encourages the model to learn more robust features and become less sensitive to small perturbations in the input.
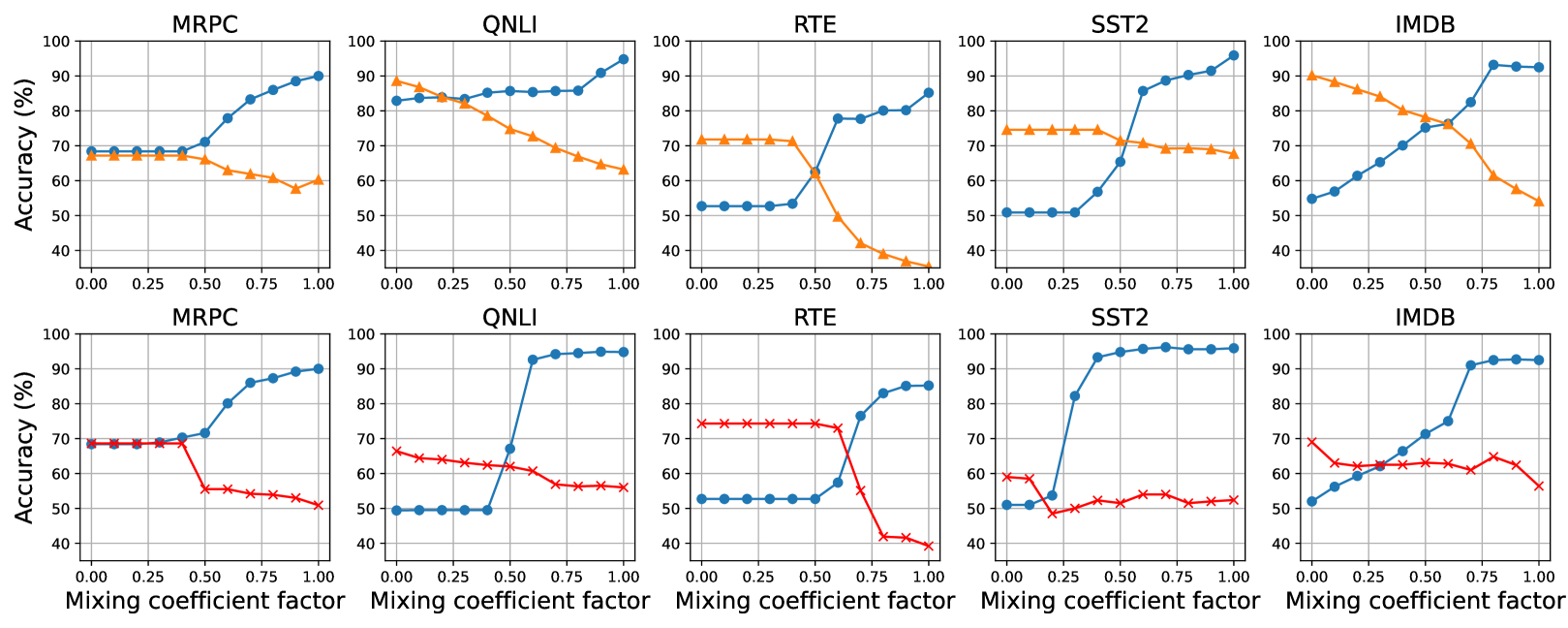
The paper's experiments show that by combining Adapters and Mixup, the MAAM method can effectively enhance the adversarial robustness of pre-trained language models, such as BERT and RoBERTa, without significantly increasing the number of trainable parameters. This makes the fine-tuning process more efficient compared to standard fine-tuning approaches.
The researchers evaluate the MAAM method on various text classification benchmarks and demonstrate its superiority over alternative fine-tuning techniques, both in terms of clean accuracy and adversarial robustness.
Critical Analysis
The paper presents a compelling approach to improving the adversarial robustness of pre-trained language models, but there are a few potential limitations and areas for further research:
-
The paper focuses on text classification tasks, but it would be interesting to see how the MAAM method performs on other language tasks, such as natural language inference or named entity recognition.
-
The experiments in the paper use relatively small-scale datasets, and it would be valuable to evaluate the MAAM method on larger, more diverse datasets to assess its broader applicability.
-
The paper does not provide a detailed analysis of the computational efficiency of the MAAM method compared to other fine-tuning approaches, which could be an important consideration for real-world applications.
-
The paper does not explore the potential for further improving the method, such as by combining Adapters with other parameter-efficient fine-tuning techniques or exploring more advanced data augmentation strategies.
Overall, the MAAM method presented in this paper represents a promising approach to enhancing the adversarial robustness of pre-trained language models, and the insights from this work could potentially be leveraged to develop even more effective techniques in the future.
Conclusion
This paper introduces a novel method called "Marrying Adapters and Mixup" (MAAM) that combines two powerful techniques - Adapters and Mixup - to efficiently enhance the adversarial robustness of pre-trained language models for text classification tasks. By leveraging the parameter-efficient fine-tuning capabilities of Adapters and the data augmentation benefits of Mixup, the MAAM method can improve the robustness of language models without significantly increasing the number of trainable parameters.
The empirical results presented in the paper demonstrate the effectiveness of the MAAM approach, which outperforms alternative fine-tuning techniques in terms of both clean accuracy and adversarial robustness. This work represents an important step towards developing more reliable and secure natural language processing systems that can withstand a wide range of adversarial attacks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adapters Mixup: Mixing Parameter-Efficient Adapters to Enhance the Adversarial Robustness of Fine-tuned Pre-trained Text Classifiers
Tuc Nguyen, Thai Le
Existing works show that augmenting the training data of pre-trained language models (PLMs) for classification tasks fine-tuned via parameter-efficient fine-tuning methods (PEFT) using both clean and adversarial examples can enhance their robustness under adversarial attacks. However, this adversarial training paradigm often leads to performance degradation on clean inputs and requires frequent re-training on the entire data to account for new, unknown attacks. To overcome these challenges while still harnessing the benefits of adversarial training and the efficiency of PEFT, this work proposes a novel approach, called AdpMixup, that combines two paradigms: (1) fine-tuning through adapters and (2) adversarial augmentation via mixup to dynamically leverage existing knowledge from a set of pre-known attacks for robust inference. Intuitively, AdpMixup fine-tunes PLMs with multiple adapters with both clean and pre-known adversarial examples and intelligently mixes them up in different ratios during prediction. Our experiments show AdpMixup achieves the best trade-off between training efficiency and robustness under both pre-known and unknown attacks, compared to existing baselines on five downstream tasks across six varied black-box attacks and 2 PLMs. All source code will be available.
Read more6/18/2024
🌿
0
Parameter-Efficient Fine-Tuning With Adapters
Keyu Chen, Yuan Pang, Zi Yang
In the arena of language model fine-tuning, the traditional approaches, such as Domain-Adaptive Pretraining (DAPT) and Task-Adaptive Pretraining (TAPT), although effective, but computational intensive. This research introduces a novel adaptation method utilizing the UniPELT framework as a base and added a PromptTuning Layer, which significantly reduces the number of trainable parameters while maintaining competitive performance across various benchmarks. Our method employs adapters, which enable efficient transfer of pretrained models to new tasks with minimal retraining of the base model parameters. We evaluate our approach using three diverse datasets: the GLUE benchmark, a domain-specific dataset comprising four distinct areas, and the Stanford Question Answering Dataset 1.1 (SQuAD). Our results demonstrate that our customized adapter-based method achieves performance comparable to full model fine-tuning, DAPT+TAPT and UniPELT strategies while requiring fewer or equivalent amount of parameters. This parameter efficiency not only alleviates the computational burden but also expedites the adaptation process. The study underlines the potential of adapters in achieving high performance with significantly reduced resource consumption, suggesting a promising direction for future research in parameter-efficient fine-tuning.
Read more5/10/2024

0
An Empirical Study on Parameter-Efficient Fine-Tuning for MultiModal Large Language Models
Xiongtao Zhou, Jie He, Yuhua Ke, Guangyao Zhu, V'ictor Guti'errez-Basulto, Jeff Z. Pan
Multimodal large language models (MLLMs) fine-tuned with multimodal instruction datasets have demonstrated remarkable capabilities in multimodal tasks. However, fine-tuning all parameters of MLLMs has become challenging as they usually contain billions of parameters. To address this issue, we study parameter-efficient fine-tuning (PEFT) methods for MLLMs. We aim to identify effective methods for enhancing the performance of MLLMs in scenarios where only a limited number of parameters are trained. This paper conducts empirical studies using four popular PEFT methods to fine-tune the LLM component of open-source MLLMs. We present a comprehensive analysis that encompasses various aspects, including the impact of PEFT methods on various models, parameters and location of the PEFT module, size of fine-tuning data, model stability based on PEFT methods, MLLM's generalization, and hallucination. We evaluated four PEFT methods on seven datasets from two different categories: unseen and seen datasets. Across all experiments, we show that the adapter is the best-performing PEFT method. At the same time, fine-tuning the connector layers leads to improved performance in most MLLMs. Code and data are available at https://github.com/alenai97/PEFT-MLLM.git.
Read more6/10/2024

0
Adapter-X: A Novel General Parameter-Efficient Fine-Tuning Framework for Vision
Minglei Li, Peng Ye, Yongqi Huang, Lin Zhang, Tao Chen, Tong He, Jiayuan Fan, Wanli Ouyang
Parameter-efficient fine-tuning (PEFT) has become increasingly important as foundation models continue to grow in both popularity and size. Adapter has been particularly well-received due to their potential for parameter reduction and adaptability across diverse tasks. However, striking a balance between high efficiency and robust generalization across tasks remains a challenge for adapter-based methods. We analyze existing methods and find that: 1) parameter sharing is the key to reducing redundancy; 2) more tunable parameters, dynamic allocation, and block-specific design are keys to improving performance. Unfortunately, no previous work considers all these factors. Inspired by this insight, we introduce a novel framework named Adapter-X. First, a Sharing Mixture of Adapters (SMoA) module is proposed to fulfill token-level dynamic allocation, increased tunable parameters, and inter-block sharing at the same time. Second, some block-specific designs like Prompt Generator (PG) are introduced to further enhance the ability of adaptation. Extensive experiments across 2D image and 3D point cloud modalities demonstrate that Adapter-X represents a significant milestone as it is the first to outperform full fine-tuning in both 2D image and 3D point cloud modalities with significantly fewer parameters, i.e., only 0.20% and 1.88% of original trainable parameters for 2D and 3D classification tasks. Our code will be publicly available.
Read more6/7/2024