MPC-Inspired Reinforcement Learning for Verifiable Model-Free Control
2312.05332
0
0
🏅
Abstract
In this paper, we introduce a new class of parameterized controllers, drawing inspiration from Model Predictive Control (MPC). The controller resembles a Quadratic Programming (QP) solver of a linear MPC problem, with the parameters of the controller being trained via Deep Reinforcement Learning (DRL) rather than derived from system models. This approach addresses the limitations of common controllers with Multi-Layer Perceptron (MLP) or other general neural network architecture used in DRL, in terms of verifiability and performance guarantees, and the learned controllers possess verifiable properties like persistent feasibility and asymptotic stability akin to MPC. On the other hand, numerical examples illustrate that the proposed controller empirically matches MPC and MLP controllers in terms of control performance and has superior robustness against modeling uncertainty and noises. Furthermore, the proposed controller is significantly more computationally efficient compared to MPC and requires fewer parameters to learn than MLP controllers. Real-world experiments on vehicle drift maneuvering task demonstrate the potential of these controllers for robotics and other demanding control tasks.
Create account to get full access
Overview
- Introduces a new class of parameterized controllers inspired by Model Predictive Control (MPC)
- The controller resembles a Quadratic Programming (QP) solver of a linear MPC problem, with the parameters of the controller trained via Deep Reinforcement Learning (DRL) rather than derived from system models
- Addresses limitations of common controllers with Multi-Layer Perceptron (MLP) or other general neural network architecture used in DRL
- Learned controllers possess verifiable properties like persistent feasibility and asymptotic stability akin to MPC
- Empirically matches MPC and MLP controllers in terms of control performance and has superior robustness against modeling uncertainty and noise
- Significantly more computationally efficient compared to MPC and requires fewer parameters to learn than MLP controllers
- Demonstrated on real-world vehicle drift maneuvering tasks
Plain English Explanation
This paper introduces a new type of controller that is inspired by Model Predictive Control (MPC). Rather than deriving the parameters of the controller from system models, the researchers use Deep Reinforcement Learning (DRL) to train the parameters.
This approach addresses some of the limitations of other neural network-based controllers, such as a lack of verifiability and performance guarantees. The learned controllers in this paper have properties like persistent feasibility and asymptotic stability, similar to MPC controllers.
The researchers found that their controller matches the performance of MPC and other neural network controllers, but is more robust to uncertainties in the system model and noise. Additionally, the new controller is much more computationally efficient than MPC and requires fewer parameters to learn than traditional neural network controllers.
The researchers demonstrated the potential of this new controller by using it to control a vehicle during a challenging drift maneuvering task, showing its applicability to robotics and other demanding control problems.
Technical Explanation
The paper introduces a new class of parameterized controllers that draw inspiration from Model Predictive Control (MPC). The controller resembles a Quadratic Programming (QP) solver of a linear MPC problem, but the parameters of the controller are trained using Deep Reinforcement Learning (DRL) rather than derived from system models.
This approach aims to address the limitations of common controllers with Multi-Layer Perceptron (MLP) or other general neural network architectures used in DRL, in terms of verifiability and performance guarantees. The learned controllers in this paper possess verifiable properties like persistent feasibility and asymptotic stability, similar to MPC controllers.
Numerical examples show that the proposed controller empirically matches MPC and MLP controllers in terms of control performance, while also demonstrating superior robustness against modeling uncertainty and noise. Furthermore, the proposed controller is significantly more computationally efficient compared to MPC and requires fewer parameters to learn than MLP controllers.
The researchers also conducted real-world experiments on a vehicle drift maneuvering task, which demonstrated the potential of these controllers for robotics and other demanding control tasks.
Critical Analysis
The paper presents a promising approach to addressing the limitations of traditional neural network-based controllers used in DRL. By drawing inspiration from MPC and leveraging the verifiable properties of the learned controllers, the researchers have developed a solution that appears to match the performance of existing methods while offering improved computational efficiency and robustness.
However, the paper does not provide a comprehensive analysis of the limitations or potential drawbacks of the proposed approach. For example, it would be helpful to understand the training requirements and the sensitivity of the controllers to hyperparameter tuning or the quality of the training data.
Additionally, while the real-world experiments on vehicle drift maneuvering are encouraging, it would be valuable to see the controllers tested on a broader range of control tasks to fully assess their generalizability and practical applicability.
Further research could also explore the potential to combine this approach with other techniques, such as Gaussian Process-based MPC or Distributionally Robust Policy Learning, to further enhance the performance and robustness of the controllers.
Conclusion
This paper presents a novel approach to designing parameterized controllers that combine the benefits of MPC and DRL. By training the controller parameters using DRL instead of relying on system models, the researchers have developed a solution that maintains the desirable properties of MPC while offering improved computational efficiency and robustness.
The results demonstrate the potential of this approach to address the limitations of traditional neural network-based controllers used in DRL, making it a promising direction for further research and development in the field of advanced control systems. The real-world experiments on vehicle drift maneuvering tasks suggest that these controllers may have significant practical applications, particularly in robotics and other demanding control scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
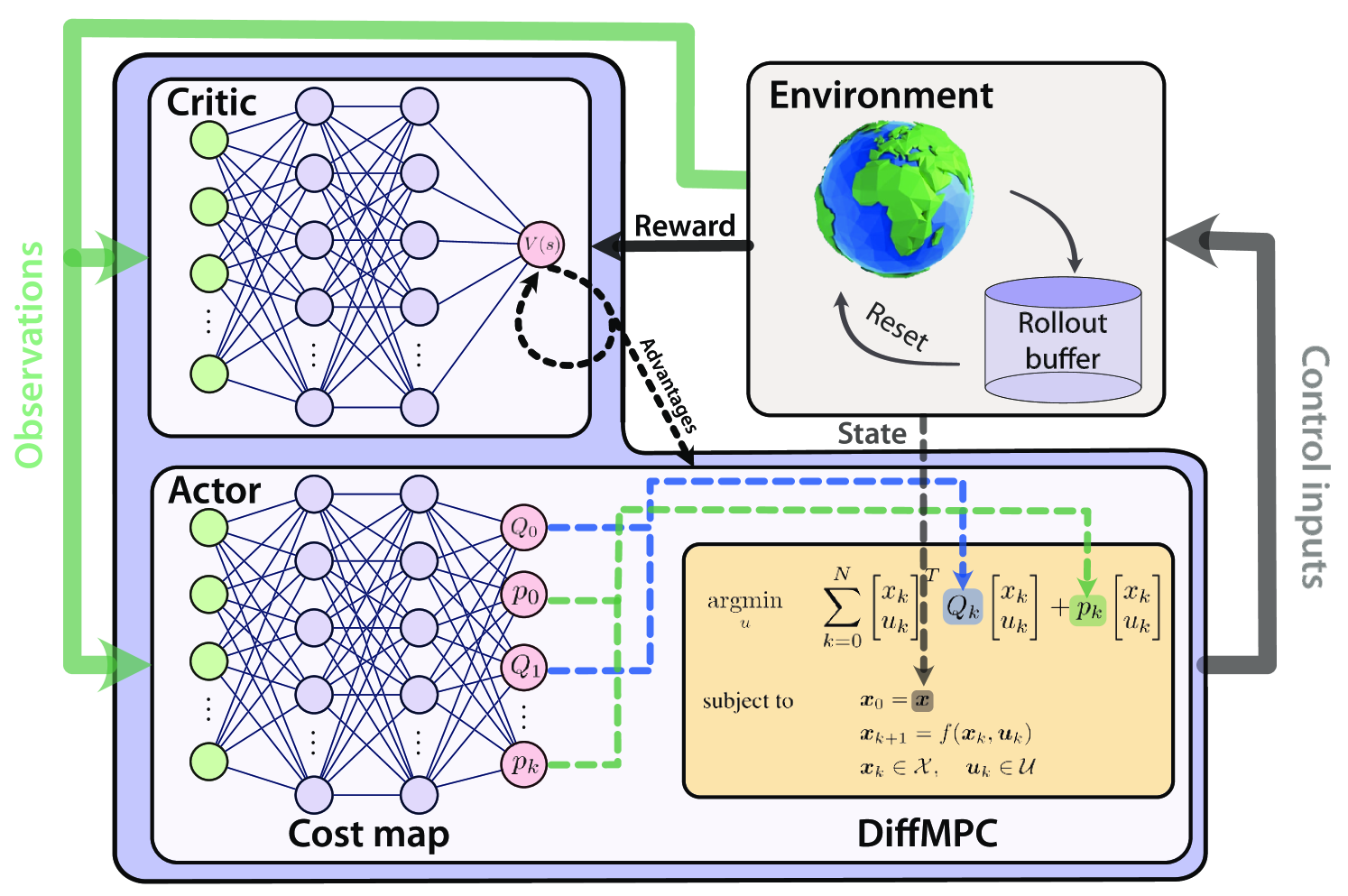
Actor-Critic Model Predictive Control
Angel Romero, Yunlong Song, Davide Scaramuzza
0
0
An open research question in robotics is how to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC). This paper provides an answer by introducing a new framework called Actor-Critic Model Predictive Control. The key idea is to embed a differentiable MPC within an actor-critic RL framework. The proposed approach leverages the short-term predictive optimization capabilities of MPC with the exploratory and end-to-end training properties of RL. The resulting policy effectively manages both short-term decisions through the MPC-based actor and long-term prediction via the critic network, unifying the benefits of both model-based control and end-to-end learning. We validate our method in both simulation and the real world with a quadcopter platform across various high-level tasks. We show that the proposed architecture can achieve real-time control performance, learn complex behaviors via trial and error, and retain the predictive properties of the MPC to better handle out of distribution behaviour.
4/15/2024
Efficient model predictive control for nonlinear systems modelled by deep neural networks
Jianglin Lan
0
0
This paper presents a model predictive control (MPC) for dynamic systems whose nonlinearity and uncertainty are modelled by deep neural networks (NNs), under input and state constraints. Since the NN output contains a high-order complex nonlinearity of the system state and control input, the MPC problem is nonlinear and challenging to solve for real-time control. This paper proposes two types of methods for solving the MPC problem: the mixed integer programming (MIP) method which produces an exact solution to the nonlinear MPC, and linear relaxation (LR) methods which generally give suboptimal solutions but are much computationally cheaper. Extensive numerical simulation for an inverted pendulum system modelled by ReLU NNs of various sizes is used to demonstrate and compare performance of the MIP and LR methods.
5/20/2024

Model Predictive Control and Reinforcement Learning: A Unified Framework Based on Dynamic Programming
Dimitri P. Bertsekas
0
0
In this paper we describe a new conceptual framework that connects approximate Dynamic Programming (DP), Model Predictive Control (MPC), and Reinforcement Learning (RL). This framework centers around two algorithms, which are designed largely independently of each other and operate in synergy through the powerful mechanism of Newton's method. We call them the off-line training and the on-line play algorithms. The names are borrowed from some of the major successes of RL involving games; primary examples are the recent (2017) AlphaZero program (which plays chess, [SHS17], [SSS17]), and the similarly structured and earlier (1990s) TD-Gammon program (which plays backgammon, [Tes94], [Tes95], [TeG96]). In these game contexts, the off-line training algorithm is the method used to teach the program how to evaluate positions and to generate good moves at any given position, while the on-line play algorithm is the method used to play in real time against human or computer opponents. Significantly, the synergy between off-line training and on-line play also underlies MPC (as well as other major classes of sequential decision problems), and indeed the MPC design architecture is very similar to the one of AlphaZero and TD-Gammon. This conceptual insight provides a vehicle for bridging the cultural gap between RL and MPC, and sheds new light on some fundamental issues in MPC. These include the enhancement of stability properties through rollout, the treatment of uncertainty through the use of certainty equivalence, the resilience of MPC in adaptive control settings that involve changing system parameters, and the insights provided by the superlinear performance bounds implied by Newton's method.
7/2/2024
📈
Reinforced Model Predictive Control via Trust-Region Quasi-Newton Policy Optimization
Dean Brandner, Sergio Lucia
0
0
Model predictive control can optimally deal with nonlinear systems under consideration of constraints. The control performance depends on the model accuracy and the prediction horizon. Recent advances propose to use reinforcement learning applied to a parameterized model predictive controller to recover the optimal control performance even if an imperfect model or short prediction horizons are used. However, common reinforcement learning algorithms rely on first order updates, which only have a linear convergence rate and hence need an excessive amount of dynamic data. Higher order updates are typically intractable if the policy is approximated with neural networks due to the large number of parameters. In this work, we use a parameterized model predictive controller as policy, and leverage the small amount of necessary parameters to propose a trust-region constrained Quasi-Newton training algorithm for policy optimization with a superlinear convergence rate. We show that the required second order derivative information can be calculated by the solution of a linear system of equations. A simulation study illustrates that the proposed training algorithm outperforms other algorithms in terms of data efficiency and accuracy.
5/29/2024