ISAACS: Iterative Soft Adversarial Actor-Critic for Safety
2212.03228
0
0
🚀
Abstract
The deployment of robots in uncontrolled environments requires them to operate robustly under previously unseen scenarios, like irregular terrain and wind conditions. Unfortunately, while rigorous safety frameworks from robust optimal control theory scale poorly to high-dimensional nonlinear dynamics, control policies computed by more tractable deep methods lack guarantees and tend to exhibit little robustness to uncertain operating conditions. This work introduces a novel approach enabling scalable synthesis of robust safety-preserving controllers for robotic systems with general nonlinear dynamics subject to bounded modeling error by combining game-theoretic safety analysis with adversarial reinforcement learning in simulation. Following a soft actor-critic scheme, a safety-seeking fallback policy is co-trained with an adversarial disturbance agent that aims to invoke the worst-case realization of model error and training-to-deployment discrepancy allowed by the designer's uncertainty. While the learned control policy does not intrinsically guarantee safety, it is used to construct a real-time safety filter (or shield) with robust safety guarantees based on forward reachability rollouts. This shield can be used in conjunction with a safety-agnostic control policy, precluding any task-driven actions that could result in loss of safety. We evaluate our learning-based safety approach in a 5D race car simulator, compare the learned safety policy to the numerically obtained optimal solution, and empirically validate the robust safety guarantee of our proposed safety shield against worst-case model discrepancy.
Create account to get full access
Overview
- Robots deployed in uncontrolled environments need to operate robustly under previously unseen scenarios, like irregular terrain and wind conditions.
- Existing control methods either lack guarantees (deep learning) or don't scale well (robust optimal control).
- This paper introduces a novel approach to synthesize robust, safety-preserving controllers for robotic systems with general nonlinear dynamics and bounded modeling error.
Plain English Explanation
Robots are increasingly being used in real-world, uncontrolled environments, such as outdoor settings or manufacturing floors. To operate safely in these unpredictable conditions, robots need to be able to handle a wide range of scenarios, like navigating irregular terrain or dealing with changing wind conditions.
However, the current control methods used for these robots have significant limitations. Approaches from robust optimal control theory can provide strong safety guarantees, but they struggle to scale to the complex, high-dimensional dynamics of real-world robots. On the other hand, deep learning control policies are more tractable but lack those safety assurances and tend to be fragile in the face of uncertainty.
The researchers in this paper have developed a new method that aims to combine the best of both worlds. By using a game-theoretic safety analysis approach along with adversarial reinforcement learning in simulation, they can synthesize robust, safety-preserving control policies for robots with general nonlinear dynamics and bounded modeling errors.
Technical Explanation
The key idea is to co-train a "safety-seeking" control policy along with an adversarial "disturbance agent" that tries to find the worst-case realizations of model error and deployment discrepancy allowed by the designer's uncertainty. This follows a soft actor-critic reinforcement learning scheme.
While the learned control policy itself does not guarantee safety, the researchers then use it to construct a real-time "safety filter" or "shield" that can provably ensure safety based on forward reachability analysis. This shield can be used alongside a separate "task-driven" control policy, blocking any actions that could lead to unsafe states.
The researchers evaluate their approach in a 5D race car simulator, comparing the learned safety policy to the numerical optimal solution and empirically validating the robust safety guarantee of the proposed shield against worst-case model discrepancy.
Critical Analysis
The key strength of this work is its ability to synthesize safety-preserving controllers for complex robotic systems with general nonlinear dynamics, going beyond the limitations of either robust optimal control or standard deep reinforcement learning approaches.
That said, the paper does not provide a complete end-to-end solution. The safety filter still requires a separate task-driven controller, and the authors note that the adversarial training process can be computationally intensive. Additionally, the theoretical safety guarantees rely on assumptions about the modeling error bounds, which may be challenging to verify in practice.
Further research could explore ways to better integrate the safety and task-driven policies, reduce the computational burden of the adversarial training, and develop methods to more rigorously quantify and validate the modeling error bounds for real-world robotic systems.
Conclusion
This paper presents a novel approach to enable scalable synthesis of robust, safety-preserving control policies for robots operating in uncontrolled environments. By combining game-theoretic safety analysis with adversarial reinforcement learning, the researchers have developed a method that can handle complex nonlinear dynamics while providing strong safety assurances.
While the approach still has some limitations, it represents an important step forward in ensuring the safe deployment of autonomous robots in the real world. As robots continue to take on increasingly complex and safety-critical tasks, research like this will be crucial for unlocking their full potential while prioritizing user safety.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Gameplay Filters: Safe Robot Walking through Adversarial Imagination
Duy P. Nguyen, Kai-Chieh Hsu, Wenhao Yu, Jie Tan, Jaime F. Fisac
0
0
Ensuring the safe operation of legged robots in uncertain, novel environments is crucial to their widespread adoption. Despite recent advances in safety filters that can keep arbitrary task-driven policies from incurring safety failures, existing solutions for legged robot locomotion still rely on simplified dynamics and may fail when the robot is perturbed away from predefined stable gaits. This paper presents a general approach that leverages offline game-theoretic reinforcement learning to synthesize a highly robust safety filter for high-order nonlinear dynamics. This gameplay filter then maintains runtime safety by continually simulating adversarial futures and precluding task-driven actions that would cause it to lose future games (and thereby violate safety). Validated on a 36-dimensional quadruped robot locomotion task, the gameplay safety filter exhibits inherent robustness to the sim-to-real gap without manual tuning or heuristic designs. Physical experiments demonstrate the effectiveness of the gameplay safety filter under perturbations, such as tugging and unmodeled irregular terrains, while simulation studies shed light on how to trade off computation and conservativeness without compromising safety.
6/3/2024
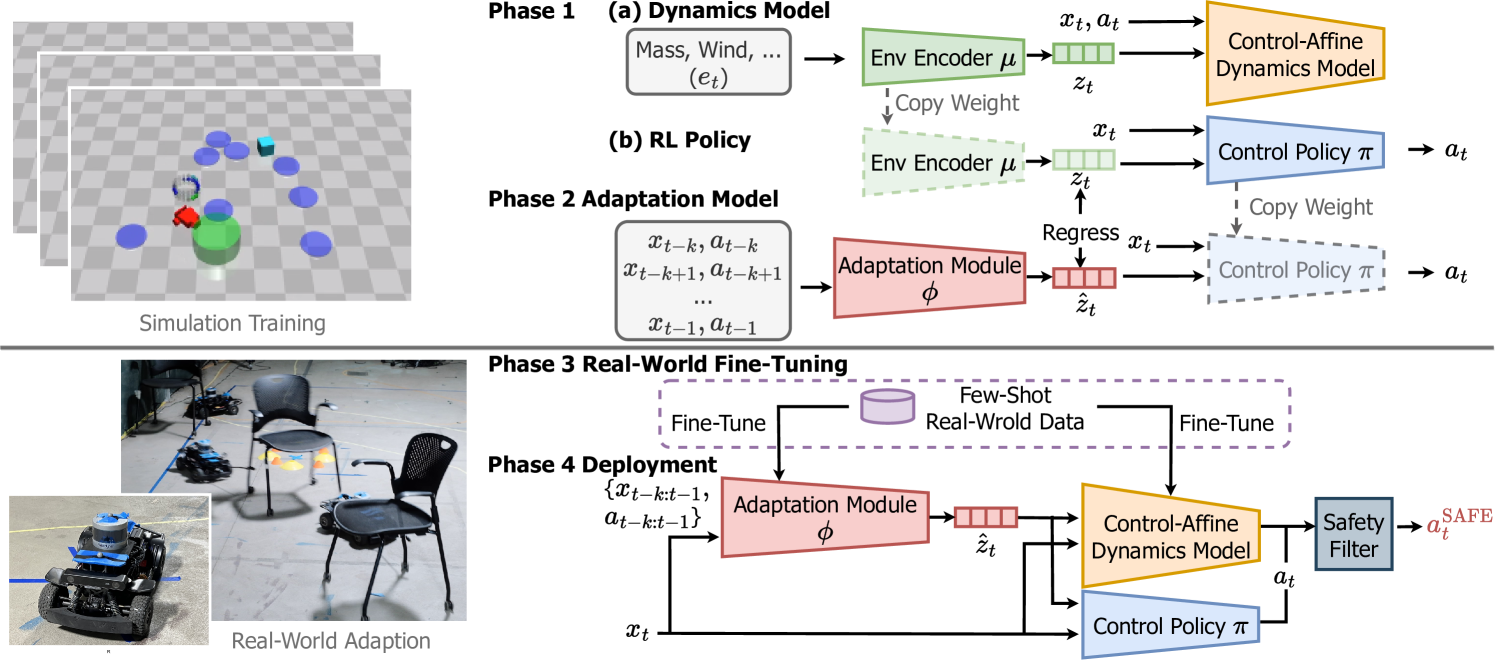
Safe Deep Policy Adaptation
Wenli Xiao, Tairan He, John Dolan, Guanya Shi
0
0
A critical goal of autonomy and artificial intelligence is enabling autonomous robots to rapidly adapt in dynamic and uncertain environments. Classic adaptive control and safe control provide stability and safety guarantees but are limited to specific system classes. In contrast, policy adaptation based on reinforcement learning (RL) offers versatility and generalizability but presents safety and robustness challenges. We propose SafeDPA, a novel RL and control framework that simultaneously tackles the problems of policy adaptation and safe reinforcement learning. SafeDPA jointly learns adaptive policy and dynamics models in simulation, predicts environment configurations, and fine-tunes dynamics models with few-shot real-world data. A safety filter based on the Control Barrier Function (CBF) on top of the RL policy is introduced to ensure safety during real-world deployment. We provide theoretical safety guarantees of SafeDPA and show the robustness of SafeDPA against learning errors and extra perturbations. Comprehensive experiments on (1) classic control problems (Inverted Pendulum), (2) simulation benchmarks (Safety Gym), and (3) a real-world agile robotics platform (RC Car) demonstrate great superiority of SafeDPA in both safety and task performance, over state-of-the-art baselines. Particularly, SafeDPA demonstrates notable generalizability, achieving a 300% increase in safety rate compared to the baselines, under unseen disturbances in real-world experiments.
4/30/2024
Adaptive Actor-Critic Based Optimal Regulation for Drift-Free Uncertain Nonlinear Systems
Ashwin P. Dani, Shubhendu Bhasin
0
0
In this paper, a continuous-time adaptive actor-critic reinforcement learning (RL) controller is developed for drift-free nonlinear systems. Practical examples of such systems are image-based visual servoing (IBVS) and wheeled mobile robots (WMR), where the system dynamics includes a parametric uncertainty in the control effectiveness matrix with no drift term. The uncertainty in the input term poses a challenge for developing a continuous-time RL controller using existing methods. In this paper, an actor-critic or synchronous policy iteration (PI)-based RL controller is presented with a concurrent learning (CL)-based parameter update law for estimating the unknown parameters of the control effectiveness matrix. An infinite-horizon value function minimization objective is achieved by regulating the current states to the desired with near-optimal control efforts. The proposed controller guarantees closed-loop stability and simulation results validate the proposed theory using IBVS and WMR examples.
6/14/2024
🏅
Verified Safe Reinforcement Learning for Neural Network Dynamic Models
Junlin Wu, Huan Zhang, Yevgeniy Vorobeychik
0
0
Learning reliably safe autonomous control is one of the core problems in trustworthy autonomy. However, training a controller that can be formally verified to be safe remains a major challenge. We introduce a novel approach for learning verified safe control policies in nonlinear neural dynamical systems while maximizing overall performance. Our approach aims to achieve safety in the sense of finite-horizon reachability proofs, and is comprised of three key parts. The first is a novel curriculum learning scheme that iteratively increases the verified safe horizon. The second leverages the iterative nature of gradient-based learning to leverage incremental verification, reusing information from prior verification runs. Finally, we learn multiple verified initial-state-dependent controllers, an idea that is especially valuable for more complex domains where learning a single universal verified safe controller is extremely challenging. Our experiments on five safe control problems demonstrate that our trained controllers can achieve verified safety over horizons that are as much as an order of magnitude longer than state-of-the-art baselines, while maintaining high reward, as well as a perfect safety record over entire episodes.
5/28/2024