Adaptive Class Emergence Training: Enhancing Neural Network Stability and Generalization through Progressive Target Evolution

0
🧠
Sign in to get full access
Overview
- Recent advancements in deep neural networks have pushed the boundaries of what can be achieved in complex tasks.
- Traditional training methods for neural networks in classification problems often rely on static target outputs, which can lead to unstable optimization and difficulties handling non-linearities.
- This paper proposes a novel training methodology that progressively evolves the target outputs from a null vector to one-hot encoded vectors throughout the training process.
Plain English Explanation
The paper describes a new way to train deep neural networks for classification problems. Traditionally, these networks are trained using static target outputs, like one-hot encoded vectors, which can cause issues. The proposed method instead gradually transitions the target outputs from a null (blank) vector to one-hot encoded vectors over the course of training.
This gradual transition allows the network to adapt more smoothly to the increasing complexity of the classification task. It helps the network maintain an equilibrium state, reducing the risk of overfitting and enhancing generalization. The approach is inspired by concepts from structural equilibrium in finite element analysis.
The researchers validate this progressive training framework through extensive experiments on both synthetic and real-world datasets. The results show that it achieves faster convergence, improved accuracy, and better generalization, especially in scenarios with high data complexity and noise. This offers a more robust alternative to classical training methods for neural networks.
Technical Explanation
The paper introduces a novel training methodology for deep neural networks in classification problems. Traditional approaches often use static target outputs, such as one-hot encoded vectors, to train the network. However, this can lead to unstable optimization and difficulties handling non-linearities within the data.
The proposed method, inspired by concepts from structural equilibrium in finite element analysis, progressively evolves the target outputs from a null vector to one-hot encoded vectors throughout the training process. This gradual transition allows the network to adapt more smoothly to the increasing complexity of the classification task, maintaining an equilibrium state that reduces the risk of overfitting and enhances generalization.
The researchers validate this progressive training framework through extensive experiments on both synthetic and real-world datasets, including scenarios with high data complexity and noise. The results demonstrate that the proposed method achieves faster convergence, improved accuracy, and better generalization compared to classical training approaches.
Critical Analysis
The paper provides a novel and promising approach to training deep neural networks for classification tasks. By gradually transitioning the target outputs during training, the method helps the network adapt more effectively to the increasing complexity of the problem, leading to improved performance and generalization.
However, the paper does not discuss the computational overhead or training time implications of the proposed method compared to traditional approaches. Additionally, the researchers acknowledge that further investigation is needed to understand the underlying mechanisms and dynamics of the progressive training framework.
It would be interesting to see the method applied to a wider range of datasets and problem domains to assess its robustness and generalizability. Exploring the method's performance in the presence of adversarial attacks or dynamical instability could also provide valuable insights.
Conclusion
The paper presents a novel training methodology for deep neural networks that progressively evolves the target outputs from a null vector to one-hot encoded vectors. This gradual transition allows the network to adapt more smoothly to the increasing complexity of the classification task, leading to faster convergence, improved accuracy, and better generalization.
The progressive training framework offers a robust alternative to classical methods, particularly in scenarios with high data complexity and noise. This research opens new perspectives for more efficient and stable neural network training, with potential applications across a wide range of generalist AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Adaptive Class Emergence Training: Enhancing Neural Network Stability and Generalization through Progressive Target Evolution
Jaouad Dabounou
Recent advancements in artificial intelligence, particularly deep neural networks, have pushed the boundaries of what is achievable in complex tasks. Traditional methods for training neural networks in classification problems often rely on static target outputs, such as one-hot encoded vectors, which can lead to unstable optimization and difficulties in handling non-linearities within data. In this paper, we propose a novel training methodology that progressively evolves the target outputs from a null vector to one-hot encoded vectors throughout the training process. This gradual transition allows the network to adapt more smoothly to the increasing complexity of the classification task, maintaining an equilibrium state that reduces the risk of overfitting and enhances generalization. Our approach, inspired by concepts from structural equilibrium in finite element analysis, has been validated through extensive experiments on both synthetic and real-world datasets. The results demonstrate that our method achieves faster convergence, improved accuracy, and better generalization, especially in scenarios with high data complexity and noise. This progressive training framework offers a robust alternative to classical methods, opening new perspectives for more efficient and stable neural network training.
Read more9/10/2024
🤿
0
Improving Generalization of Deep Neural Networks by Optimum Shifting
Yuyan Zhou, Ye Li, Lei Feng, Sheng-Jun Huang
Recent studies showed that the generalization of neural networks is correlated with the sharpness of the loss landscape, and flat minima suggests a better generalization ability than sharp minima. In this paper, we propose a novel method called emph{optimum shifting}, which changes the parameters of a neural network from a sharp minimum to a flatter one while maintaining the same training loss value. Our method is based on the observation that when the input and output of a neural network are fixed, the matrix multiplications within the network can be treated as systems of under-determined linear equations, enabling adjustment of parameters in the solution space, which can be simply accomplished by solving a constrained optimization problem. Furthermore, we introduce a practical stochastic optimum shifting technique utilizing the Neural Collapse theory to reduce computational costs and provide more degrees of freedom for optimum shifting. Extensive experiments (including classification and detection) with various deep neural network architectures on benchmark datasets demonstrate the effectiveness of our method.
Read more5/24/2024

0
Maintaining Adversarial Robustness in Continuous Learning
Xiaolei Ru, Xiaowei Cao, Zijia Liu, Jack Murdoch Moore, Xin-Ya Zhang, Xia Zhu, Wenjia Wei, Gang Yan
Adversarial robustness is essential for security and reliability of machine learning systems. However, adversarial robustness enhanced by defense algorithms is easily erased as the neural network's weights update to learn new tasks. To address this vulnerability, it is essential to improve the capability of neural networks in terms of robust continual learning. Specially, we propose a novel gradient projection technique that effectively stabilizes sample gradients from previous data by orthogonally projecting back-propagation gradients onto a crucial subspace before using them for weight updates. This technique can maintaining robustness by collaborating with a class of defense algorithms through sample gradient smoothing. The experimental results on four benchmarks including Split-CIFAR100 and Split-miniImageNet, demonstrate that the superiority of the proposed approach in mitigating rapidly degradation of robustness during continual learning even when facing strong adversarial attacks.
Read more8/14/2024
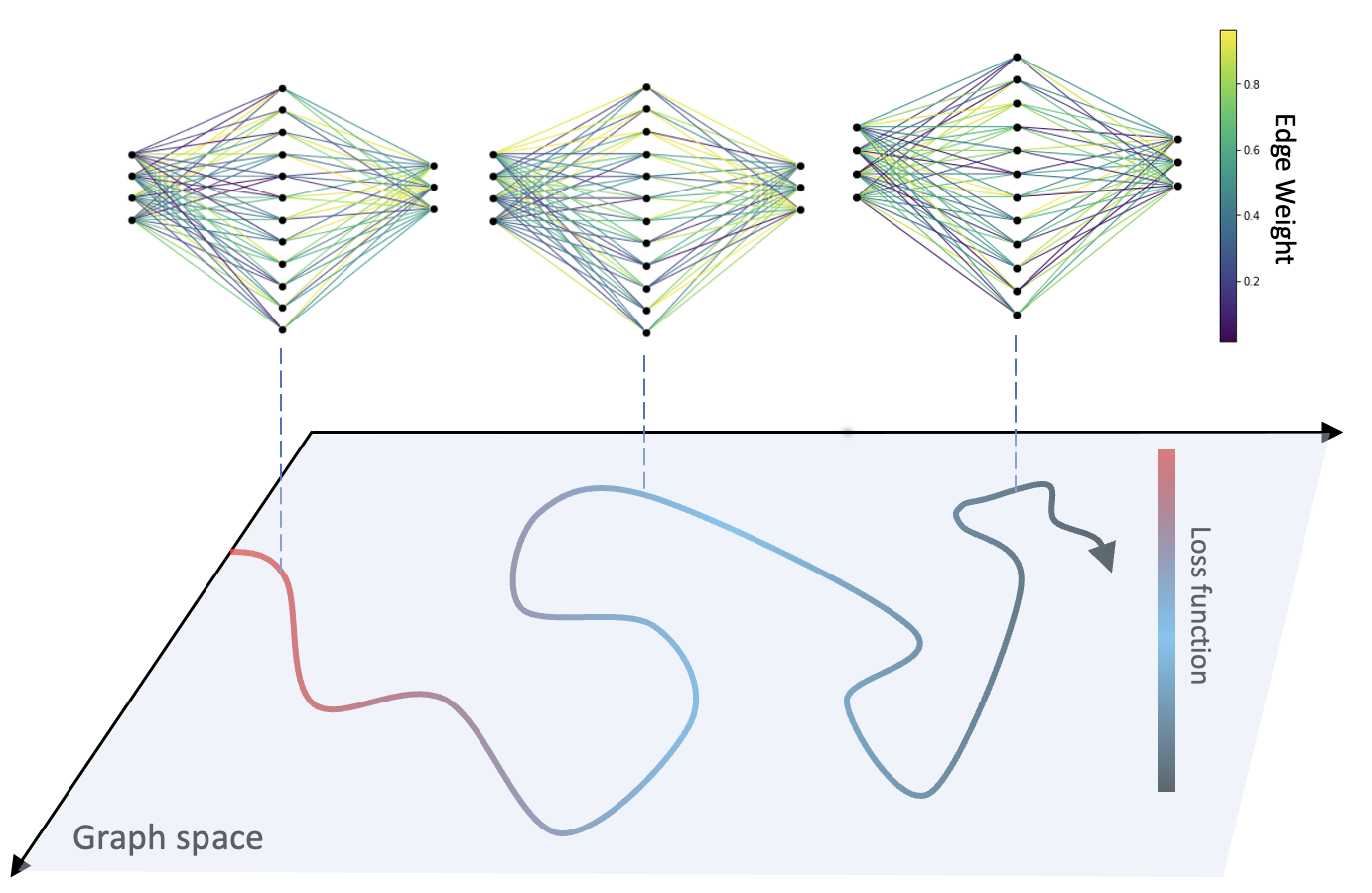
0
Dynamical stability and chaos in artificial neural network trajectories along training
Kaloyan Danovski, Miguel C. Soriano, Lucas Lacasa
The process of training an artificial neural network involves iteratively adapting its parameters so as to minimize the error of the network's prediction, when confronted with a learning task. This iterative change can be naturally interpreted as a trajectory in network space -- a time series of networks -- and thus the training algorithm (e.g. gradient descent optimization of a suitable loss function) can be interpreted as a dynamical system in graph space. In order to illustrate this interpretation, here we study the dynamical properties of this process by analyzing through this lens the network trajectories of a shallow neural network, and its evolution through learning a simple classification task. We systematically consider different ranges of the learning rate and explore both the dynamical and orbital stability of the resulting network trajectories, finding hints of regular and chaotic behavior depending on the learning rate regime. Our findings are put in contrast to common wisdom on convergence properties of neural networks and dynamical systems theory. This work also contributes to the cross-fertilization of ideas between dynamical systems theory, network theory and machine learning
Read more4/10/2024