Adaptive Data Analysis for Growing Data
2405.13375
0
0
📊
Abstract
Reuse of data in adaptive workflows poses challenges regarding overfitting and the statistical validity of results. Previous work has demonstrated that interacting with data via differentially private algorithms can mitigate overfitting, achieving worst-case generalization guarantees with asymptotically optimal data requirements. However, such past work assumes data is static and cannot accommodate situations where data grows over time. In this paper we address this gap, presenting the first generalization bounds for adaptive analysis in the dynamic data setting. We allow the analyst to adaptively schedule their queries conditioned on the current size of the data, in addition to previous queries and responses. We also incorporate time-varying empirical accuracy bounds and mechanisms, allowing for tighter guarantees as data accumulates. In a batched query setting, the asymptotic data requirements of our bound grows with the square-root of the number of adaptive queries, matching prior works' improvement over data splitting for the static setting. We instantiate our bound for statistical queries with the clipped Gaussian mechanism, where it empirically outperforms baselines composed from static bounds.
Create account to get full access
Overview
- This paper addresses the challenge of reusing data in adaptive workflows, where data can grow over time, to mitigate overfitting and ensure statistical validity of results.
- It presents the first generalization bounds for adaptive analysis in the dynamic data setting, allowing the analyst to adaptively schedule queries based on the current data size as well as previous queries and responses.
- The bounds incorporate time-varying empirical accuracy bounds and mechanisms, enabling tighter guarantees as data accumulates.
- In a batched query setting, the asymptotic data requirements of the bound grow with the square-root of the number of adaptive queries, matching prior improvements over data splitting for the static setting.
Plain English Explanation
When researchers or analysts repeatedly interact with and make decisions based on a dataset, there's a risk of "overfitting" - where the results become tailored to the specific dataset and may not generalize well to new data. This is a significant challenge, especially when the dataset is growing over time.
The paper presents a new approach to mitigate this issue. It allows the analyst to dynamically adjust their queries based on the current size of the dataset, as well as their previous interactions. This helps ensure the results remain statistically valid and generalize better as the dataset expands.
The key innovation is a set of mathematical "bounds" that quantify how much the analyst can adapt their queries before the results start to overfit. These bounds get tighter as more data becomes available, allowing the analyst to be more confident in their findings.
Importantly, the asymptotic (long-term) data requirements of this approach scale with the square-root of the number of adaptive queries. This matches prior work's improvements over simpler techniques like "data splitting" in the static data setting, demonstrating the effectiveness of this new approach.
Technical Explanation
The paper tackles the problem of reusing data in adaptive workflows, where the dataset can grow over time. This is a challenge because repeatedly interacting with the data can lead to overfitting, undermining the statistical validity of the results.
The authors present the first generalization bounds for adaptive analysis in the dynamic data setting. This allows the analyst to adaptively schedule their queries based on the current data size, as well as the previous queries and responses. The bounds also incorporate time-varying empirical accuracy bounds and mechanisms, enabling tighter guarantees as more data accumulates.
In a batched query setting, the asymptotic data requirements of the bound grow with the square-root of the number of adaptive queries. This matches the improvement over data splitting techniques seen in prior work for the static data case.
The authors instantiate their bound for statistical queries using the clipped Gaussian mechanism, and show it empirically outperforms baselines composed from static bounds. This demonstrates the practical benefits of their approach compared to simpler methods like data-driven performance guarantees or online-to-batch conversion in the dynamic data setting.
Critical Analysis
The paper presents a well-designed and rigorous approach to addressing the challenge of adaptive data reuse in the face of growing datasets. The authors provide a strong theoretical foundation by deriving generalization bounds that account for the dynamic nature of the data and the adaptive querying process.
One potential limitation is that the analysis is focused on a batched query setting, which may not fully capture real-world scenarios where analysts interact with data in a more continuous and interactive manner. It would be valuable to see if the authors' techniques can be extended to handle such continuous adaptive workflows.
Additionally, the paper does not delve into the practical implementation details or the computational overhead associated with their approach. It would be helpful to understand the trade-offs between the statistical guarantees provided and the computational resources required.
Further research could also explore the interplay between the proposed techniques and other approaches, such as additive effect assisted learning or the use of Bayesian perspectives on generalization, to develop a more comprehensive understanding of adaptive data reuse in dynamic settings.
Conclusion
This paper presents a significant contribution to the field of adaptive data analysis, addressing the critical challenge of ensuring statistical validity and generalization in the face of growing datasets. The authors' novel generalization bounds for the dynamic data setting, with their ability to adapt to the current data size and provide tighter guarantees over time, represent an important step forward.
The theoretical insights and empirical results demonstrate the potential of this approach to enable more robust and reliable adaptive workflows, with broader implications for fields like machine learning, data science, and scientific research where data reuse is a common practice. Further development and real-world applications of these techniques could lead to more trustworthy and impactful data-driven decision making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
Generalization in the Face of Adaptivity: A Bayesian Perspective
Moshe Shenfeld, Katrina Ligett
0
0
Repeated use of a data sample via adaptively chosen queries can rapidly lead to overfitting, wherein the empirical evaluation of queries on the sample significantly deviates from their mean with respect to the underlying data distribution. It turns out that simple noise addition algorithms suffice to prevent this issue, and differential privacy-based analysis of these algorithms shows that they can handle an asymptotically optimal number of queries. However, differential privacy's worst-case nature entails scaling such noise to the range of the queries even for highly-concentrated queries, or introducing more complex algorithms. In this paper, we prove that straightforward noise-addition algorithms already provide variance-dependent guarantees that also extend to unbounded queries. This improvement stems from a novel characterization that illuminates the core problem of adaptive data analysis. We show that the harm of adaptivity results from the covariance between the new query and a Bayes factor-based measure of how much information about the data sample was encoded in the responses given to past queries. We then leverage this characterization to introduce a new data-dependent stability notion that can bound this covariance.
4/5/2024
📊
A New Analysis of Differential Privacy's Generalization Guarantees
Christopher Jung, Katrina Ligett, Seth Neel, Aaron Roth, Saeed Sharifi-Malvajerdi, Moshe Shenfeld
0
0
We give a new proof of the transfer theorem underlying adaptive data analysis: that any mechanism for answering adaptively chosen statistical queries that is differentially private and sample-accurate is also accurate out-of-sample. Our new proof is elementary and gives structural insights that we expect will be useful elsewhere. We show: 1) that differential privacy ensures that the expectation of any query on the posterior distribution on datasets induced by the transcript of the interaction is close to its true value on the data distribution, and 2) sample accuracy on its own ensures that any query answer produced by the mechanism is close to its posterior expectation with high probability. This second claim follows from a thought experiment in which we imagine that the dataset is resampled from the posterior distribution after the mechanism has committed to its answers. The transfer theorem then follows by summing these two bounds, and in particular, avoids the monitor argument used to derive high probability bounds in prior work. An upshot of our new proof technique is that the concrete bounds we obtain are substantially better than the best previously known bounds, even though the improvements are in the constants, rather than the asymptotics (which are known to be tight). As we show, our new bounds outperform the naive sample-splitting baseline at dramatically smaller dataset sizes compared to the previous state of the art, bringing techniques from this literature closer to practicality.
6/5/2024

Adaptive debiased SGD in high-dimensional GLMs with steaming data
Ruijian Han, Lan Luo, Yuanhang Luo, Yuanyuan Lin, Jian Huang
0
0
Online statistical inference facilitates real-time analysis of sequentially collected data, making it different from traditional methods that rely on static datasets. This paper introduces a novel approach to online inference in high-dimensional generalized linear models, where we update regression coefficient estimates and their standard errors upon each new data arrival. In contrast to existing methods that either require full dataset access or large-dimensional summary statistics storage, our method operates in a single-pass mode, significantly reducing both time and space complexity. The core of our methodological innovation lies in an adaptive stochastic gradient descent algorithm tailored for dynamic objective functions, coupled with a novel online debiasing procedure. This allows us to maintain low-dimensional summary statistics while effectively controlling optimization errors introduced by the dynamically changing loss functions. We demonstrate that our method, termed the Approximated Debiased Lasso (ADL), not only mitigates the need for the bounded individual probability condition but also significantly improves numerical performance. Numerical experiments demonstrate that the proposed ADL method consistently exhibits robust performance across various covariance matrix structures.
6/4/2024
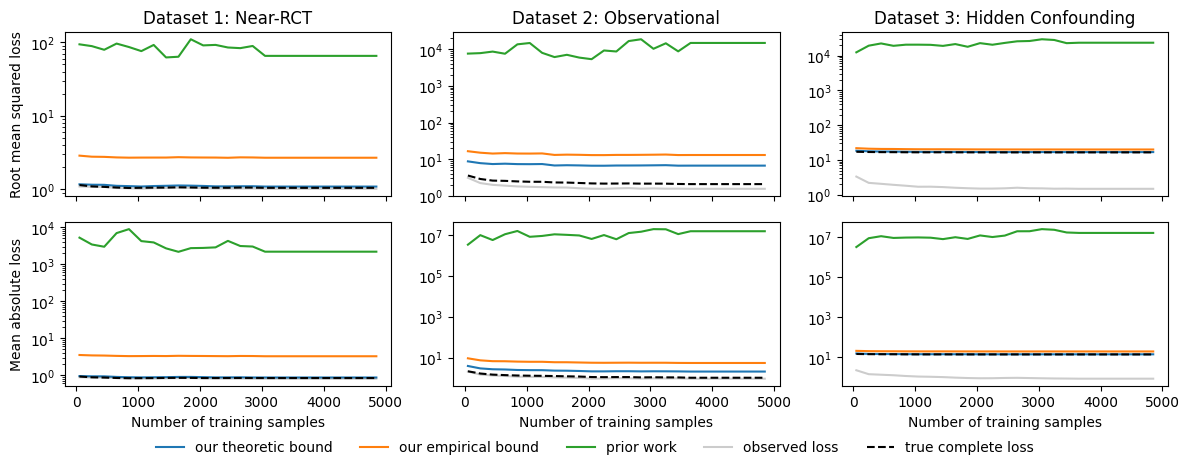
Generalization Bounds for Causal Regression: Insights, Guarantees and Sensitivity Analysis
Daniel Csillag, Claudio Jos'e Struchiner, Guilherme Tegoni Goedert
0
0
Many algorithms have been recently proposed for causal machine learning. Yet, there is little to no theory on their quality, especially considering finite samples. In this work, we propose a theory based on generalization bounds that provides such guarantees. By introducing a novel change-of-measure inequality, we are able to tightly bound the model loss in terms of the deviation of the treatment propensities over the population, which we show can be empirically limited. Our theory is fully rigorous and holds even in the face of hidden confounding and violations of positivity. We demonstrate our bounds on semi-synthetic and real data, showcasing their remarkable tightness and practical utility.
5/16/2024