Additive-Effect Assisted Learning
2405.08235
0
0
📈
Abstract
It is quite popular nowadays for researchers and data analysts holding different datasets to seek assistance from each other to enhance their modeling performance. We consider a scenario where different learners hold datasets with potentially distinct variables, and their observations can be aligned by a nonprivate identifier. Their collaboration faces the following difficulties: First, learners may need to keep data values or even variable names undisclosed due to, e.g., commercial interest or privacy regulations; second, there are restrictions on the number of transmission rounds between them due to e.g., communication costs. To address these challenges, we develop a two-stage assisted learning architecture for an agent, Alice, to seek assistance from another agent, Bob. In the first stage, we propose a privacy-aware hypothesis testing-based screening method for Alice to decide on the usefulness of the data from Bob, in a way that only requires Bob to transmit sketchy data. Once Alice recognizes Bob's usefulness, Alice and Bob move to the second stage, where they jointly apply a synergistic iterative model training procedure. With limited transmissions of summary statistics, we show that Alice can achieve the oracle performance as if the training were from centralized data, both theoretically and numerically.
Create account to get full access
Overview
- Researchers and data analysts often seek assistance from each other to improve their modeling performance
- This paper addresses challenges faced in such collaborations, where data values or variable names may need to be kept private, and there are restrictions on the number of communication rounds
- The authors develop a two-stage assisted learning architecture to address these challenges
Plain English Explanation
The paper explores a scenario where different researchers or data analysts have datasets with potentially different variables, but their observations can be aligned using a shared identifier. This is similar to the problem addressed in the paper "Group Decision-Making Among Privacy-Aware Agents". The researchers may need to keep some data values or variable names private, perhaps due to commercial interests or privacy regulations. Additionally, there may be limits on the number of communication rounds between them, such as due to high communication costs.
To address these challenges, the authors propose a two-stage assisted learning approach. In the first stage, the agent Alice uses a privacy-aware hypothesis testing method to determine if the data from agent Bob is useful, without Bob having to share detailed data. This is similar to the approach of "Automating Data Annotation Under Strategic Human Agents". If Alice finds Bob's data useful, they move to the second stage, where they jointly train a model using an iterative approach that only requires sharing summary statistics, not the full data. This collaborative model training is analogous to the "Learning Multi-Agent Communication from Graph Modeling" and "Double Machine Learning Approach to Combining Experimental and Observational Studies"](https://aimodels.fyi/papers/arxiv/double-machine-learning-approach-to-combining-experimental) papers. The authors show that with this limited data sharing, Alice can achieve the same performance as if she had access to a centralized dataset.
Technical Explanation
The paper proposes a two-stage assisted learning architecture to address the challenges of privacy-preserving and communication-efficient collaboration between different learners (Alice and Bob) who hold datasets with potentially distinct variables.
In the first stage, the authors develop a privacy-aware hypothesis testing-based screening method to allow Alice to assess the usefulness of Bob's data. This method only requires Bob to transmit sketchy data summaries, without revealing the actual data values or variable names. This is similar to the "Blind Federated Learning Without Initial Model" approach.
If Alice recognizes Bob's data as useful, they proceed to the second stage, where they jointly apply a synergistic iterative model training procedure. This iterative process allows them to train a model using only limited transmissions of summary statistics, rather than the full datasets. The authors show that Alice can achieve the same performance as if she had access to a centralized dataset, both theoretically and through numerical experiments.
Critical Analysis
The paper presents a practical solution for privacy-preserving and communication-efficient collaboration between different learners. The authors acknowledge that their approach relies on the availability of a nonprivate identifier to align the observations across datasets, which may not always be the case in real-world scenarios.
Additionally, the authors do not extensively discuss potential issues around the reliability and robustness of the hypothesis testing-based screening method, nor do they explore the impact of different levels of data heterogeneity on the overall performance. Further research could investigate these areas and explore more sophisticated techniques for preserving data privacy while enabling effective collaboration.
Conclusion
This paper introduces a two-stage assisted learning architecture that allows different learners to collaborate and leverage each other's data, even when there are constraints on data sharing due to privacy concerns or communication costs. The authors demonstrate that their approach can enable learners to achieve the same performance as if they had access to a centralized dataset, without compromising data privacy or incurring high communication overhead. This work highlights the potential for privacy-preserving and communication-efficient collaboration in the field of data analysis and machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Group Decision-Making among Privacy-Aware Agents
Marios Papachristou, M. Amin Rahimian
0
0
How can individuals exchange information to learn from each other despite their privacy needs and security concerns? For example, consider individuals deliberating a contentious topic and being concerned about divulging their private experiences. Preserving individual privacy and enabling efficient social learning are both important desiderata but seem fundamentally at odds with each other and very hard to reconcile. We do so by controlling information leakage using rigorous statistical guarantees that are based on differential privacy (DP). Our agents use log-linear rules to update their beliefs after communicating with their neighbors. Adding DP randomization noise to beliefs provides communicating agents with plausible deniability with regard to their private information and their network neighborhoods. We consider two learning environments one for distributed maximum-likelihood estimation given a finite number of private signals and another for online learning from an infinite, intermittent signal stream. Noisy information aggregation in the finite case leads to interesting tradeoffs between rejecting low-quality states and making sure all high-quality states are accepted in the algorithm output. Our results flesh out the nature of the trade-offs in both cases between the quality of the group decision outcomes, learning accuracy, communication cost, and the level of privacy protections that the agents are afforded.
4/12/2024
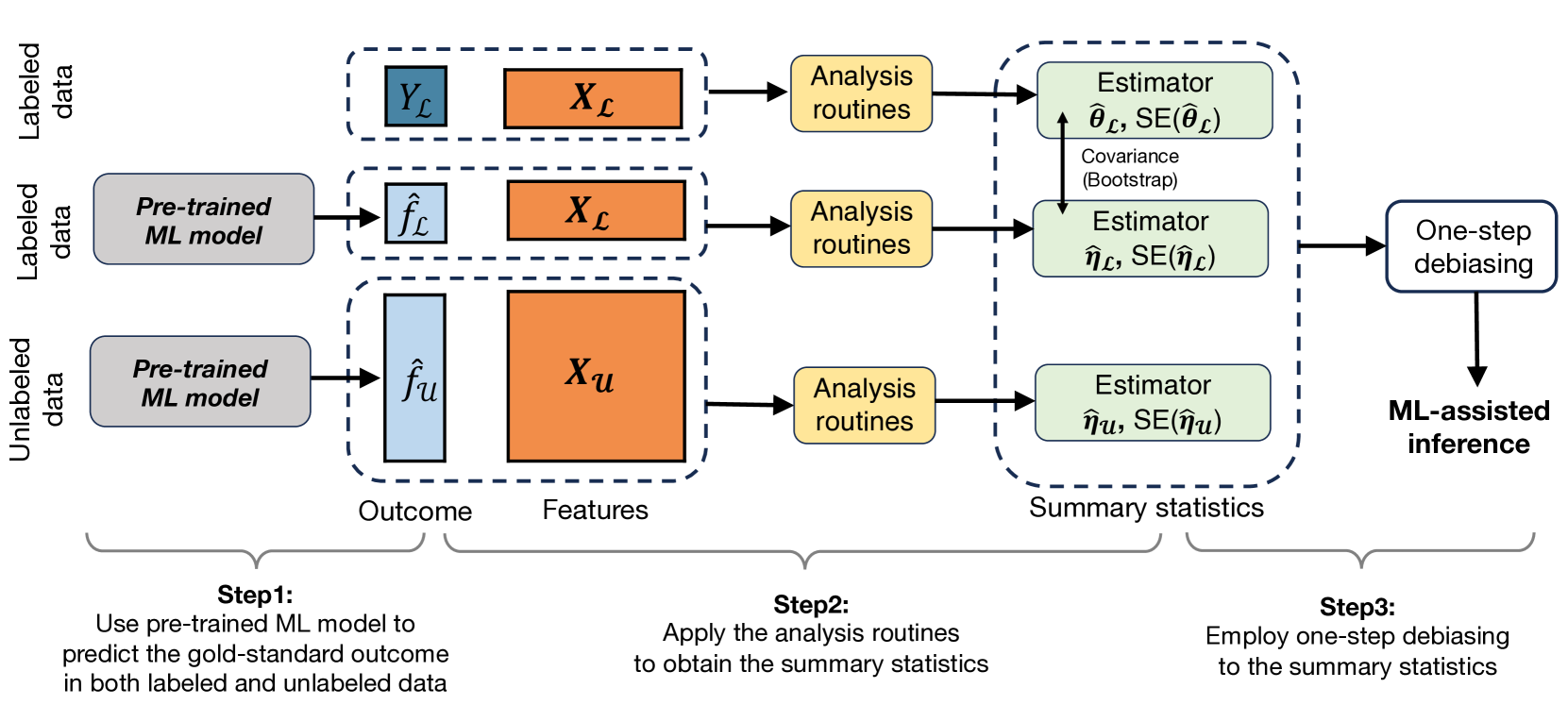
Task-Agnostic Machine Learning-Assisted Inference
Jiacheng Miao, Qiongshi Lu
0
0
Machine learning (ML) is playing an increasingly important role in scientific research. In conjunction with classical statistical approaches, ML-assisted analytical strategies have shown great promise in accelerating research findings. This has also opened up a whole new field of methodological research focusing on integrative approaches that leverage both ML and statistics to tackle data science challenges. One type of study that has quickly gained popularity employs ML to predict unobserved outcomes in massive samples and then uses the predicted outcomes in downstream statistical inference. However, existing methods designed to ensure the validity of this type of post-prediction inference are limited to very basic tasks such as linear regression analysis. This is because any extension of these approaches to new, more sophisticated statistical tasks requires task-specific algebraic derivations and software implementations, which ignores the massive library of existing software tools already developed for complex inference tasks and severely constrains the scope of post-prediction inference in real applications. To address this challenge, we propose a novel statistical framework for task-agnostic ML-assisted inference. It provides a post-prediction inference solution that can be easily plugged into almost any established data analysis routine. It delivers valid and efficient inference that is robust to arbitrary choices of ML models, while allowing nearly all existing analytical frameworks to be incorporated into the analysis of ML-predicted outcomes. Through extensive experiments, we showcase the validity, versatility, and superiority of our method compared to existing approaches.
5/31/2024

Teaching-Assistant-in-the-Loop: Improving Knowledge Distillation from Imperfect Teacher Models in Low-Budget Scenarios
Yuhang Zhou, Wei Ai
0
0
There is increasing interest in distilling task-specific knowledge from large language models (LLM) to smaller student models. Nonetheless, LLM distillation presents a dual challenge: 1) there is a high cost associated with querying the teacher LLM, such as GPT-4, for gathering an ample number of demonstrations; 2) the teacher LLM might provide imperfect outputs with a negative impact on the student's learning process. To enhance sample efficiency within resource-constrained, imperfect teacher scenarios, we propose a three-component framework leveraging three signal types. The first signal is the student's self-consistency (consistency of student multiple outputs), which is a proxy of the student's confidence. Specifically, we introduce a ``teaching assistant'' (TA) model to assess the uncertainty of both the student's and the teacher's outputs via confidence scoring, which serves as another two signals for student training. Furthermore, we propose a two-stage training schema to first warm up the student with a small proportion of data to better utilize student's signal. Experiments have shown the superiority of our proposed framework for four complex reasoning tasks. On average, our proposed two-stage framework brings a relative improvement of up to 20.79% compared to fine-tuning without any signals across datasets.
6/11/2024
📊
LIA: Privacy-Preserving Data Quality Evaluation in Federated Learning Using a Lazy Influence Approximation
Ljubomir Rokvic, Panayiotis Danassis, Sai Praneeth Karimireddy, Boi Faltings
0
0
In Federated Learning, it is crucial to handle low-quality, corrupted, or malicious data. However, traditional data valuation methods are not suitable due to privacy concerns. To address this, we propose a simple yet effective approach that utilizes a new influence approximation called lazy influence to filter and score data while preserving privacy. To do this, each participant uses their own data to estimate the influence of another participant's batch and sends a differentially private obfuscated score to the central coordinator. Our method has been shown to successfully filter out biased and corrupted data in various simulated and real-world settings, achieving a recall rate of over $>90%$ (sometimes up to $100%$) while maintaining strong differential privacy guarantees with $varepsilon leq 1$.
6/3/2024