Adaptive Patching for High-resolution Image Segmentation with Transformers
2404.09707
0
0
Abstract
Attention-based models are proliferating in the space of image analytics, including segmentation. The standard method of feeding images to transformer encoders is to divide the images into patches and then feed the patches to the model as a linear sequence of tokens. For high-resolution images, e.g. microscopic pathology images, the quadratic compute and memory cost prohibits the use of an attention-based model, if we are to use smaller patch sizes that are favorable in segmentation. The solution is to either use custom complex multi-resolution models or approximate attention schemes. We take inspiration from Adapative Mesh Refinement (AMR) methods in HPC by adaptively patching the images, as a pre-processing step, based on the image details to reduce the number of patches being fed to the model, by orders of magnitude. This method has a negligible overhead, and works seamlessly with any attention-based model, i.e. it is a pre-processing step that can be adopted by any attention-based model without friction. We demonstrate superior segmentation quality over SoTA segmentation models for real-world pathology datasets while gaining a geomean speedup of $6.9times$ for resolutions up to $64K^2$, on up to $2,048$ GPUs.
Create account to get full access
Overview
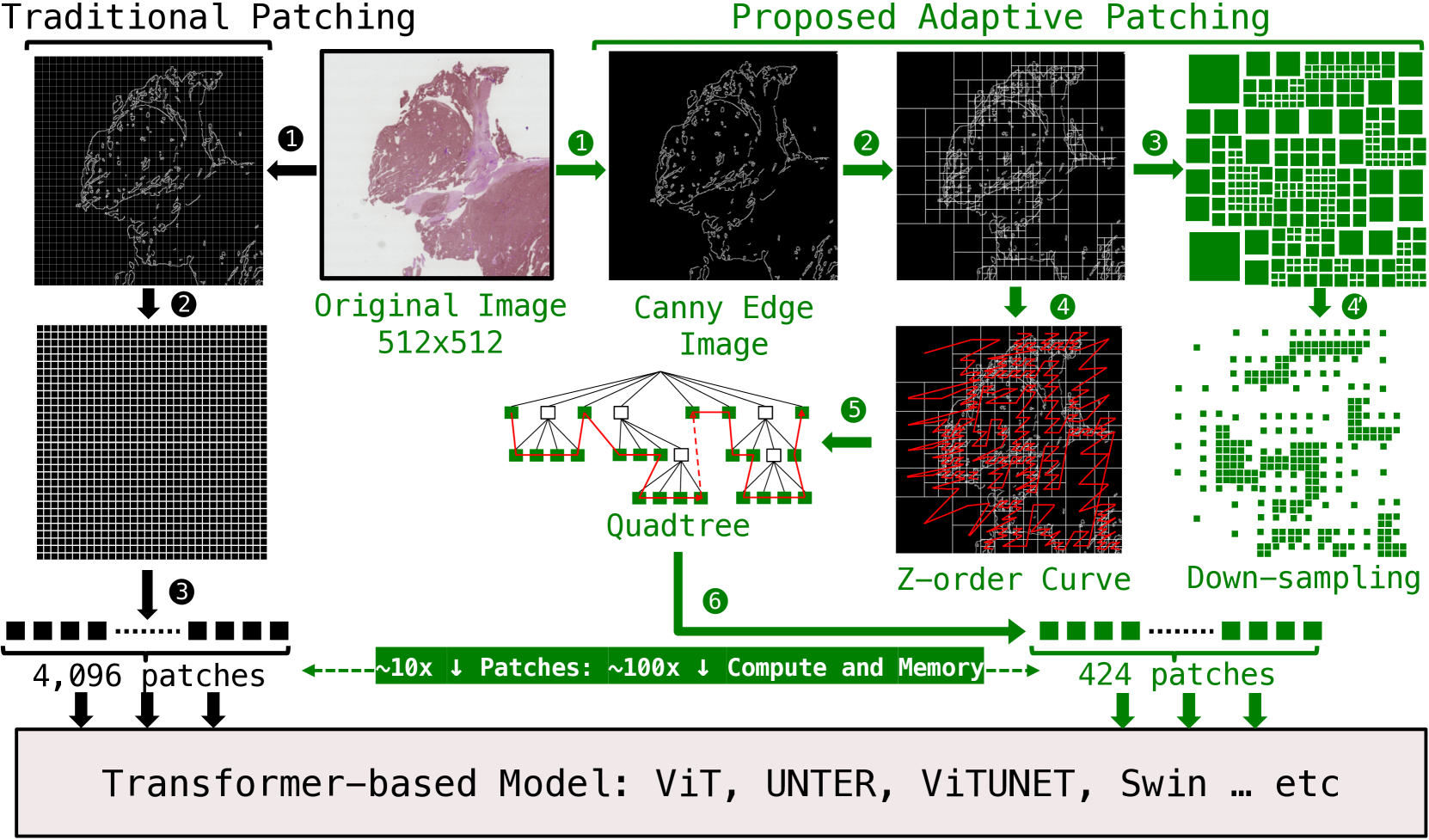
- This paper introduces a novel approach called "Adaptive Patching" for high-resolution image segmentation using Transformer models.
- The method adaptively divides the input image into variable-sized patches based on the complexity of the image content, allowing for efficient processing of high-resolution images.
- The authors demonstrate the effectiveness of their approach on various high-resolution image segmentation tasks, achieving state-of-the-art performance while maintaining computational efficiency.
Plain English Explanation
The paper presents a new technique called "Adaptive Patching" that aims to improve the way Transformer models (a type of deep learning algorithm) handle high-resolution images for the task of image segmentation. Image segmentation is the process of dividing an image into different parts or "segments" based on the characteristics of the objects or regions in the image.
Traditionally, Transformer models have struggled with high-resolution images because they process the entire image at once, which can be computationally expensive. The Adaptive Patching approach addresses this by dynamically dividing the input image into patches of variable size, depending on the complexity of the content in each region. This allows the model to focus more processing power on the complex areas of the image while using fewer resources on simpler regions.
The authors demonstrate that their Adaptive Patching method outperforms other state-of-the-art techniques for high-resolution image segmentation, while still being computationally efficient. This means the model can process large, detailed images quickly and accurately, which could be beneficial for applications like medical imaging, satellite imagery analysis, and autonomous driving.
Technical Explanation
The paper introduces an "Adaptive Patching" approach to improve the efficiency of Transformer models for high-resolution image segmentation. Traditionally, Transformer models process the entire input image at once, which can be computationally expensive for large, high-resolution images. The Adaptive Patching method addresses this by dynamically dividing the input image into variable-sized patches based on the complexity of the image content.
The authors propose an adaptive patch division algorithm that recursively splits the input image into smaller patches until a target patch size is reached. The algorithm considers factors like edge density and texture complexity to determine the appropriate patch size for each region of the image. This allows the Transformer model to focus more computational resources on the complex regions of the image while using fewer resources on simpler areas.
The Adaptive Patching approach is integrated into a Transformer-based segmentation model, and the authors evaluate its performance on several high-resolution image segmentation datasets. The results show that the Adaptive Patching method outperforms other state-of-the-art techniques, including MansFormer, EMPower, and ARENA, while maintaining computational efficiency. The authors also demonstrate the model's ability to handle variable-sized input images, which is particularly useful for real-world applications.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the Adaptive Patching approach, considering various high-resolution image segmentation tasks and comparing it to other state-of-the-art methods. The authors have also addressed potential limitations, such as the sensitivity of the adaptive patch division algorithm to hyperparameter settings, and have suggested areas for future research.
One potential area for further investigation is the generalization of the Adaptive Patching method to other Transformer-based tasks beyond image segmentation, such as image completion or HDR imaging. Additionally, the authors could explore the integration of the Adaptive Patching approach with other recent advancements in Transformer architectures and efficient inference techniques.
Overall, the paper presents a valuable contribution to the field of high-resolution image processing with Transformer models, and the Adaptive Patching method could have significant implications for a wide range of real-world applications.
Conclusion
The "Adaptive Patching" approach introduced in this paper represents an important advancement in the field of high-resolution image segmentation using Transformer models. By adaptively dividing the input image into variable-sized patches based on content complexity, the method is able to maintain high segmentation accuracy while improving computational efficiency.
The authors' experimental results demonstrate the effectiveness of their approach, with the Adaptive Patching model outperforming other state-of-the-art techniques on several challenging high-resolution image segmentation tasks. This innovative technique could have far-reaching implications for applications that require the processing of large, detailed images, such as medical imaging, satellite imagery analysis, and autonomous driving.
The paper also highlights potential areas for future research, such as expanding the Adaptive Patching method to other Transformer-based tasks and integrating it with other recent advancements in efficient deep learning architectures. Overall, this work represents an important step forward in making high-resolution image processing more practical and accessible for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Towards Robust Semantic Segmentation against Patch-based Attack via Attention Refinement
Zheng Yuan, Jie Zhang, Yude Wang, Shiguang Shan, Xilin Chen
0
0
The attention mechanism has been proven effective on various visual tasks in recent years. In the semantic segmentation task, the attention mechanism is applied in various methods, including the case of both Convolution Neural Networks (CNN) and Vision Transformer (ViT) as backbones. However, we observe that the attention mechanism is vulnerable to patch-based adversarial attacks. Through the analysis of the effective receptive field, we attribute it to the fact that the wide receptive field brought by global attention may lead to the spread of the adversarial patch. To address this issue, in this paper, we propose a Robust Attention Mechanism (RAM) to improve the robustness of the semantic segmentation model, which can notably relieve the vulnerability against patch-based attacks. Compared to the vallina attention mechanism, RAM introduces two novel modules called Max Attention Suppression and Random Attention Dropout, both of which aim to refine the attention matrix and limit the influence of a single adversarial patch on the semantic segmentation results of other positions. Extensive experiments demonstrate the effectiveness of our RAM to improve the robustness of semantic segmentation models against various patch-based attack methods under different attack settings.
5/10/2024
🖼️
Harnessing The Power of Attention For Patch-Based Biomedical Image Classification
Gousia Habib, Shaima Qureshi, Malik ishfaq
0
0
Biomedical image analysis is of paramount importance for the advancement of healthcare and medical research. Although conventional convolutional neural networks (CNNs) are frequently employed in this domain, facing limitations in capturing intricate spatial and temporal relationships at the pixel level due to their reliance on fixed-sized windows and immutable filter weights post-training. These constraints impede their ability to adapt to input fluctuations and comprehend extensive long-range contextual information. To overcome these challenges, a novel architecture based on self-attention mechanisms as an alternative to conventional CNNs.The proposed model utilizes attention-based mechanisms to surpass the limitations of CNNs. The key component of our strategy is the combination of non-overlapping (vanilla patching) and novel overlapped Shifted Patching Techniques (S.P.T.s), which enhances the model's capacity to capture local context and improves generalization. Additionally, we introduce the Lancoz5 interpolation technique, which adapts variable image sizes to higher resolutions, facilitating better analysis of high-resolution biomedical images. Our methods address critical challenges faced by attention-based vision models, including inductive bias, weight sharing, receptive field limitations, and efficient data handling. Experimental evidence shows the effectiveness of proposed model in generalizing to various biomedical imaging tasks. The attention-based model, combined with advanced data augmentation methodologies, exhibits robust modeling capabilities and superior performance compared to existing approaches. The integration of S.P.T.s significantly enhances the model's ability to capture local context, while the Lancoz5 interpolation technique ensures efficient handling of high-resolution images.
6/11/2024
👀
Masked Attention as a Mechanism for Improving Interpretability of Vision Transformers
Cl'ement Grisi, Geert Litjens, Jeroen van der Laak
0
0
Vision Transformers are at the heart of the current surge of interest in foundation models for histopathology. They process images by breaking them into smaller patches following a regular grid, regardless of their content. Yet, not all parts of an image are equally relevant for its understanding. This is particularly true in computational pathology where background is completely non-informative and may introduce artefacts that could mislead predictions. To address this issue, we propose a novel method that explicitly masks background in Vision Transformers' attention mechanism. This ensures tokens corresponding to background patches do not contribute to the final image representation, thereby improving model robustness and interpretability. We validate our approach using prostate cancer grading from whole-slide images as a case study. Our results demonstrate that it achieves comparable performance with plain self-attention while providing more accurate and clinically meaningful attention heatmaps.
4/30/2024
🖼️
Multi-dimension Transformer with Attention-based Filtering for Medical Image Segmentation
Wentao Wang, Xi Xiao, Mingjie Liu, Qing Tian, Xuanyao Huang, Qizhen Lan, Swalpa Kumar Roy, Tianyang Wang
0
0
The accurate segmentation of medical images is crucial for diagnosing and treating diseases. Recent studies demonstrate that vision transformer-based methods have significantly improved performance in medical image segmentation, primarily due to their superior ability to establish global relationships among features and adaptability to various inputs. However, these methods struggle with the low signal-to-noise ratio inherent to medical images. Additionally, the effective utilization of channel and spatial information, which are essential for medical image segmentation, is limited by the representation capacity of self-attention. To address these challenges, we propose a multi-dimension transformer with attention-based filtering (MDT-AF), which redesigns the patch embedding and self-attention mechanism for medical image segmentation. MDT-AF incorporates an attention-based feature filtering mechanism into the patch embedding blocks and employs a coarse-to-fine process to mitigate the impact of low signal-to-noise ratio. To better capture complex structures in medical images, MDT-AF extends the self-attention mechanism to incorporate spatial and channel dimensions, enriching feature representation. Moreover, we introduce an interaction mechanism to improve the feature aggregation between spatial and channel dimensions. Experimental results on three public medical image segmentation benchmarks show that MDT-AF achieves state-of-the-art (SOTA) performance.
5/22/2024