Token-Specific Watermarking with Enhanced Detectability and Semantic Coherence for Large Language Models
2402.18059
0
0
Abstract
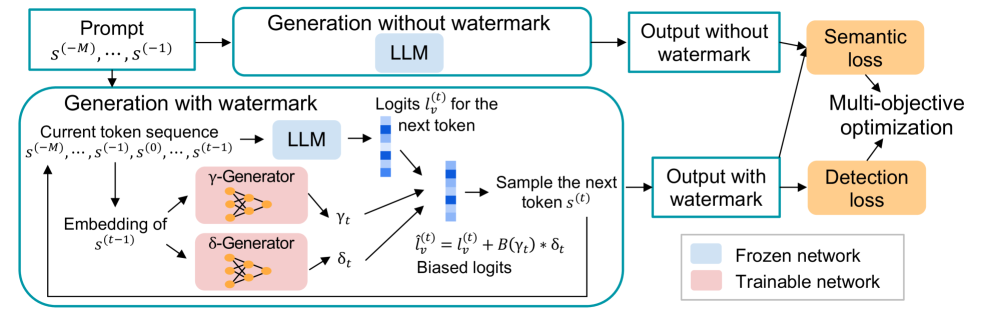
Large language models generate high-quality responses with potential misinformation, underscoring the need for regulation by distinguishing AI-generated and human-written texts. Watermarking is pivotal in this context, which involves embedding hidden markers in texts during the LLM inference phase, which is imperceptible to humans. Achieving both the detectability of inserted watermarks and the semantic quality of generated texts is challenging. While current watermarking algorithms have made promising progress in this direction, there remains significant scope for improvement. To address these challenges, we introduce a novel multi-objective optimization (MOO) approach for watermarking that utilizes lightweight networks to generate token-specific watermarking logits and splitting ratios. By leveraging MOO to optimize for both detection and semantic objective functions, our method simultaneously achieves detectability and semantic integrity. Experimental results show that our method outperforms current watermarking techniques in enhancing the detectability of texts generated by LLMs while maintaining their semantic coherence. Our code is available at https://github.com/mignonjia/TS_watermark.
Create account to get full access
Overview
- Introduces a new method for watermarking large language models (LLMs) that enhances detectability and semantic coherence
- Aims to address limitations of previous watermarking techniques for LLMs
- Proposes a token-specific watermarking approach that is more robust and less disruptive to the model's language generation capabilities
Plain English Explanation
Watermarking is a technique used to identify the source of a large language model (LLM), like GPT-3 or DALL-E. This helps protect against unauthorized use or copying of the model. However, previous watermarking methods have had issues - they were either easy to detect but disrupted the model's language, or were hard to detect but didn't preserve the model's meaning.
This new method tries to solve those problems. It embeds a watermark into the individual tokens (words) produced by the LLM, rather than the overall text. This makes the watermark harder to remove without severely degrading the model's performance. The watermark is also designed to maintain the natural flow and meaning of the generated text, so it doesn't stand out as unnatural.
The key idea is to carefully craft the watermark so it blends seamlessly into the model's language, while still being detectable by the model's owner. This allows the owner to identify if the model has been misused, without sacrificing the quality of the text the model produces.
Technical Explanation
The paper introduces a token-specific watermarking technique for LLMs that aims to address the limitations of previous approaches. The proposed method embeds the watermark into individual tokens, rather than the overall text, to enhance detectability and maintain semantic coherence.
The key components of the approach are:
-
Watermark Embedding: The watermark is embedded into the token representations within the LLM, rather than the final output text. This makes the watermark harder to remove without significantly degrading the model's performance.
-
Semantic Coherence: The watermark is designed to be semantically coherent with the token's context, preserving the natural flow and meaning of the generated text.
-
Watermark Detectability: The watermark can be reliably detected by the model's owner, even in the presence of various masking or removal attempts, through a dedicated detection model.
The paper evaluates the proposed method on several LLMs, including GPT-2 and GPT-3, and compares it to previous watermarking techniques for LLMs. The results demonstrate improved detectability and semantic coherence, while maintaining the models' language generation capabilities.
Critical Analysis
The paper presents a compelling approach to watermarking LLMs, addressing several limitations of prior techniques. The token-specific watermarking method offers enhanced detectability and semantic coherence, which are important for practical deployment and real-world applications.
However, the paper acknowledges that the watermark may still be vulnerable to more advanced removal techniques, such as fine-tuning or adversarial attacks. Additionally, the impact of the watermarking on the model's performance, particularly in terms of sample quality and diversity, could be further explored.
Further research is also needed to understand the potential for linguistic watermarks to be used as a tracer for model extraction attacks, and to explore topic-based watermarking approaches that may provide additional benefits.
Conclusion
This paper introduces a novel token-specific watermarking technique for LLMs that addresses the limitations of previous approaches. By embedding the watermark into individual tokens while preserving semantic coherence, the method enhances detectability and maintains the models' language generation capabilities.
The proposed approach represents an important advancement in the field of LLM watermarking, with potential applications in intellectual property protection, model provenance, and responsible AI development. As the use of LLMs continues to grow, techniques like this will become increasingly valuable for ensuring the integrity and accountability of these powerful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Semantic Invariant Robust Watermark for Large Language Models
Aiwei Liu, Leyi Pan, Xuming Hu, Shiao Meng, Lijie Wen
0
0
Watermark algorithms for large language models (LLMs) have achieved extremely high accuracy in detecting text generated by LLMs. Such algorithms typically involve adding extra watermark logits to the LLM's logits at each generation step. However, prior algorithms face a trade-off between attack robustness and security robustness. This is because the watermark logits for a token are determined by a certain number of preceding tokens; a small number leads to low security robustness, while a large number results in insufficient attack robustness. In this work, we propose a semantic invariant watermarking method for LLMs that provides both attack robustness and security robustness. The watermark logits in our work are determined by the semantics of all preceding tokens. Specifically, we utilize another embedding LLM to generate semantic embeddings for all preceding tokens, and then these semantic embeddings are transformed into the watermark logits through our trained watermark model. Subsequent analyses and experiments demonstrated the attack robustness of our method in semantically invariant settings: synonym substitution and text paraphrasing settings. Finally, we also show that our watermark possesses adequate security robustness. Our code and data are available at href{https://github.com/THU-BPM/Robust_Watermark}{https://github.com/THU-BPM/Robust_Watermark}. Additionally, our algorithm could also be accessed through MarkLLM citep{pan2024markllm} footnote{https://github.com/THU-BPM/MarkLLM}.
5/21/2024
💬
A Watermark for Large Language Models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein
0
0
Potential harms of large language models can be mitigated by watermarking model output, i.e., embedding signals into generated text that are invisible to humans but algorithmically detectable from a short span of tokens. We propose a watermarking framework for proprietary language models. The watermark can be embedded with negligible impact on text quality, and can be detected using an efficient open-source algorithm without access to the language model API or parameters. The watermark works by selecting a randomized set of green tokens before a word is generated, and then softly promoting use of green tokens during sampling. We propose a statistical test for detecting the watermark with interpretable p-values, and derive an information-theoretic framework for analyzing the sensitivity of the watermark. We test the watermark using a multi-billion parameter model from the Open Pretrained Transformer (OPT) family, and discuss robustness and security.
5/3/2024
Adaptive Text Watermark for Large Language Models
Yepeng Liu, Yuheng Bu
0
0
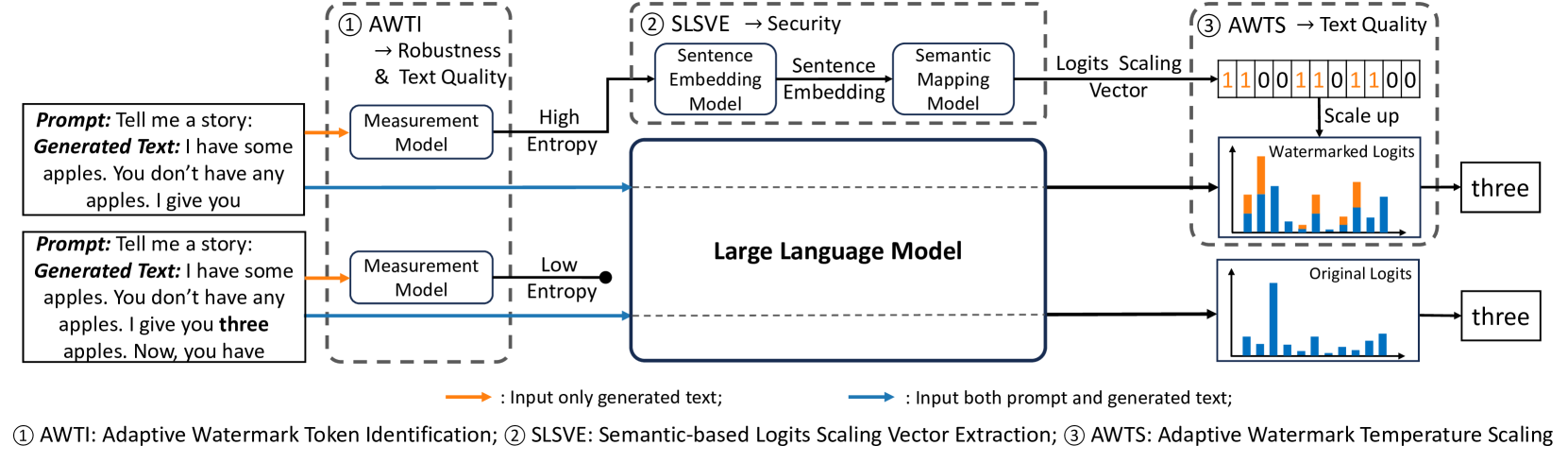
The advancement of Large Language Models (LLMs) has led to increasing concerns about the misuse of AI-generated text, and watermarking for LLM-generated text has emerged as a potential solution. However, it is challenging to generate high-quality watermarked text while maintaining strong security, robustness, and the ability to detect watermarks without prior knowledge of the prompt or model. This paper proposes an adaptive watermarking strategy to address this problem. To improve the text quality and maintain robustness, we adaptively add watermarking to token distributions with high entropy measured using an auxiliary model and keep the low entropy token distributions untouched. For the sake of security and to further minimize the watermark's impact on text quality, instead of using a fixed green/red list generated from a random secret key, which can be vulnerable to decryption and forgery, we adaptively scale up the output logits in proportion based on the semantic embedding of previously generated text using a well designed semantic mapping model. Our experiments involving various LLMs demonstrate that our approach achieves comparable robustness performance to existing watermark methods. Additionally, the text generated by our method has perplexity comparable to that of emph{un-watermarked} LLMs while maintaining security even under various attacks.
6/11/2024
💬
Publicly-Detectable Watermarking for Language Models
Jaiden Fairoze, Sanjam Garg, Somesh Jha, Saeed Mahloujifar, Mohammad Mahmoody, Mingyuan Wang
0
0
We present a highly detectable, trustless watermarking scheme for LLMs: the detection algorithm contains no secret information, and it is executable by anyone. We embed a publicly-verifiable cryptographic signature into LLM output using rejection sampling. We prove that our scheme is cryptographically correct, sound, and distortion-free. We make novel uses of error-correction techniques to overcome periods of low entropy, a barrier for all prior watermarking schemes. We implement our scheme and make empirical measurements over open models in the 2.7B to 70B parameter range. Our experiments suggest that our formal claims are met in practice.
5/29/2024