Automating Data Annotation under Strategic Human Agents: Risks and Potential Solutions
2405.08027
0
0

Abstract
As machine learning (ML) models are increasingly used in social domains to make consequential decisions about humans, they often have the power to reshape data distributions. Humans, as strategic agents, continuously adapt their behaviors in response to the learning system. As populations change dynamically, ML systems may need frequent updates to ensure high performance. However, acquiring high-quality human-annotated samples can be highly challenging and even infeasible in social domains. A common practice to address this issue is using the model itself to annotate unlabeled data samples. This paper investigates the long-term impacts when ML models are retrained with model-annotated samples when they incorporate human strategic responses. We first formalize the interactions between strategic agents and the model and then analyze how they evolve under such dynamic interactions. We find that agents are increasingly likely to receive positive decisions as the model gets retrained, whereas the proportion of agents with positive labels may decrease over time. We thus propose a refined retraining process to stabilize the dynamics. Last, we examine how algorithmic fairness can be affected by these retraining processes and find that enforcing common fairness constraints at every round may not benefit the disadvantaged group in the long run. Experiments on (semi-)synthetic and real data validate the theoretical findings.
Create account to get full access
Overview
- The paper explores the risks and potential solutions in automating data annotation under strategic human agents.
- It investigates the challenges that arise when human workers are incentivized to behave strategically during the data annotation process.
- The paper proposes various mitigation strategies to address these issues and ensure the reliability and integrity of the annotated data.
Plain English Explanation
The paper discusses the problems that can arise when you try to automate the process of labeling or annotating data, especially when the people doing the labeling are motivated to act in their own best interests rather than just trying to accurately label the data.
Imagine you're training a machine learning model to recognize different types of animals in images. You need a large dataset of images that have been labeled or annotated to show which parts of each image contain different animals. Typically, you would hire people to look at the images and provide those labels.
However, the paper points out that these human workers might not always be completely honest or objective. They might intentionally mislabel some images if they think it will benefit them, like getting paid more or finishing the job faster. This strategic behavior from the human workers can undermine the quality and reliability of the dataset, which in turn affects the performance of the machine learning model.
The paper explores various strategies to address this problem, such as designing better incentive structures, using techniques like strategic behavior in AI training data to detect and mitigate strategic behavior, and incorporating welfare-aware strategic learning approaches. The goal is to find ways to get accurate, unbiased data annotations even when the human workers have their own agendas.
Technical Explanation
The paper formulates the problem of automating data annotation under strategic human agents as a game-theoretic framework. It models the interaction between the data requester (e.g., the machine learning model trainer) and the human annotators as a multi-agent system, where the annotators can engage in strategic behavior to maximize their own utilities.
The paper analyzes the potential risks of such strategic behavior, including the introduction of biases and blind spots in the annotated data, the degradation of data quality, and the negative impact on the performance of the downstream machine learning models.
To mitigate these risks, the paper proposes several potential solutions, such as:
- Designing appropriate incentive structures and payment schemes to align the objectives of the human annotators with the data requester's goals.
- Developing techniques to detect and discourage strategic behavior during the annotation process.
- Incorporating welfare-aware strategic learning approaches that take into account the annotators' utilities and attempt to optimize for a balance between data quality and worker welfare.
- Leveraging large language models (LLMs) to assist and augment the human annotators, potentially mitigating the impact of their strategic behavior.
The paper discusses the trade-offs and challenges associated with each of these proposed solutions, highlighting the need for further research and experimentation to develop effective strategies for automating data annotation in the presence of strategic human agents.
Critical Analysis
The paper raises important concerns about the risks of automating data annotation when human workers may act strategically to maximize their own interests rather than provide accurate, unbiased labels. The game-theoretic framework and the analysis of potential risks, such as the introduction of biases and the degradation of data quality, are well-justified and relevant to the current state of machine learning and data-driven systems.
However, the paper could have delved deeper into the practical implications and challenges of implementing the proposed solutions. For example, the design of appropriate incentive structures and payment schemes may be highly context-dependent and require careful consideration of the specific task, worker demographics, and cultural factors. Additionally, the paper could have explored the potential limitations and unintended consequences of techniques like strategic behavior detection and welfare-aware strategic learning, which may introduce their own complexities and tradeoffs.
Furthermore, the paper could have discussed the broader societal implications of automating data annotation, particularly regarding the potential exploitation of human workers and the ethical considerations around the use of strategic behavior in such systems. Addressing these issues would provide a more comprehensive understanding of the risks and potential solutions presented in the paper.
Overall, the paper provides a solid foundation for understanding the challenges and risks of automating data annotation under strategic human agents, but further research and discussion are needed to develop effective and ethically-sound solutions.
Conclusion
The paper highlights the critical problem of strategic behavior among human annotators in the context of automated data annotation for machine learning systems. It presents a game-theoretic framework for modeling this issue and proposes several mitigation strategies, such as designing appropriate incentive structures, detecting and discouraging strategic behavior, and leveraging large language models to support the annotation process.
The insights from this research are significant, as they underscore the need to consider the human element and potential biases in the development of reliable and unbiased datasets for training machine learning models. By addressing these challenges, the research can contribute to the broader goal of building trustworthy and responsible AI systems that are aligned with societal values and objectives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Leveraging Large Language Models (LLMs) to Support Collaborative Human-AI Online Risk Data Annotation
Jinkyung Park, Pamela Wisniewski, Vivek Singh
0
0
In this position paper, we discuss the potential for leveraging LLMs as interactive research tools to facilitate collaboration between human coders and AI to effectively annotate online risk data at scale. Collaborative human-AI labeling is a promising approach to annotating large-scale and complex data for various tasks. Yet, tools and methods to support effective human-AI collaboration for data annotation are under-studied. This gap is pertinent because co-labeling tasks need to support a two-way interactive discussion that can add nuance and context, particularly in the context of online risk, which is highly subjective and contextualized. Therefore, we provide some of the early benefits and challenges of using LLMs-based tools for risk annotation and suggest future directions for the HCI research community to leverage LLMs as research tools to facilitate human-AI collaboration in contextualized online data annotation. Our research interests align very well with the purposes of the LLMs as Research Tools workshop to identify ongoing applications and challenges of using LLMs to work with data in HCI research. We anticipate learning valuable insights from organizers and participants into how LLMs can help reshape the HCI community's methods for working with data.
4/12/2024
📈
A Dynamic Model of Performative Human-ML Collaboration: Theory and Empirical Evidence
Tom Suhr, Samira Samadi, Chiara Farronato
0
0
Machine learning (ML) models are increasingly used in various applications, from recommendation systems in e-commerce to diagnosis prediction in healthcare. In this paper, we present a novel dynamic framework for thinking about the deployment of ML models in a performative, human-ML collaborative system. In our framework, the introduction of ML recommendations changes the data generating process of human decisions, which are only a proxy to the ground truth and which are then used to train future versions of the model. We show that this dynamic process in principle can converge to different stable points, i.e. where the ML model and the Human+ML system have the same performance. Some of these stable points are suboptimal with respect to the actual ground truth. We conduct an empirical user study with 1,408 participants to showcase this process. In the study, humans solve instances of the knapsack problem with the help of machine learning predictions. This is an ideal setting because we can see how ML models learn to imitate human decisions and how this learning process converges to a stable point. We find that for many levels of ML performance, humans can improve the ML predictions to dynamically reach an equilibrium performance that is around 92% of the maximum knapsack value. We also find that the equilibrium performance could be even higher if humans rationally followed the ML recommendations. Finally, we test whether monetary incentives can increase the quality of human decisions, but we fail to find any positive effect. Our results have practical implications for the deployment of ML models in contexts where human decisions may deviate from the indisputable ground truth.
6/7/2024
Social Choice for AI Alignment: Dealing with Diverse Human Feedback
Vincent Conitzer, Rachel Freedman, Jobst Heitzig, Wesley H. Holliday, Bob M. Jacobs, Nathan Lambert, Milan Moss'e, Eric Pacuit, Stuart Russell, Hailey Schoelkopf, Emanuel Tewolde, William S. Zwicker
0
0
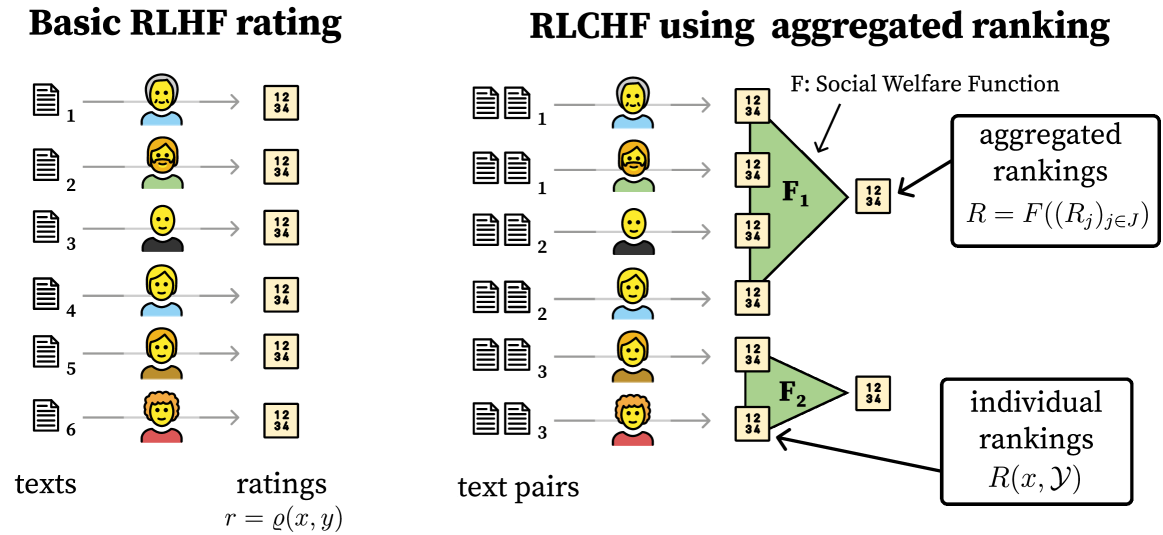
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, such as helping to commit crimes or producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about collective preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
6/5/2024
Enhancing Text Classification through LLM-Driven Active Learning and Human Annotation
Hamidreza Rouzegar, Masoud Makrehchi
0
0
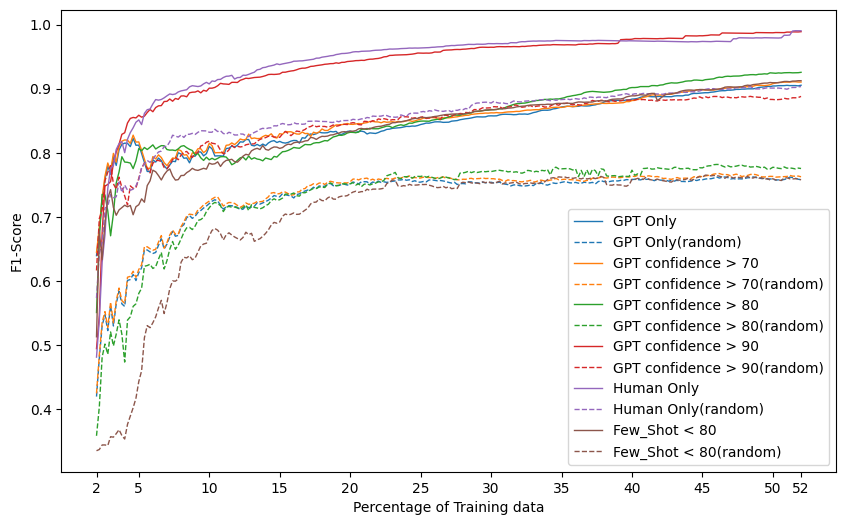
In the context of text classification, the financial burden of annotation exercises for creating training data is a critical issue. Active learning techniques, particularly those rooted in uncertainty sampling, offer a cost-effective solution by pinpointing the most instructive samples for manual annotation. Similarly, Large Language Models (LLMs) such as GPT-3.5 provide an alternative for automated annotation but come with concerns regarding their reliability. This study introduces a novel methodology that integrates human annotators and LLMs within an Active Learning framework. We conducted evaluations on three public datasets. IMDB for sentiment analysis, a Fake News dataset for authenticity discernment, and a Movie Genres dataset for multi-label classification.The proposed framework integrates human annotation with the output of LLMs, depending on the model uncertainty levels. This strategy achieves an optimal balance between cost efficiency and classification performance. The empirical results show a substantial decrease in the costs associated with data annotation while either maintaining or improving model accuracy.
6/19/2024