ADDP: Learning General Representations for Image Recognition and Generation with Alternating Denoising Diffusion Process
2306.05423
0
0
🖼️
Abstract
Image recognition and generation have long been developed independently of each other. With the recent trend towards general-purpose representation learning, the development of general representations for both recognition and generation tasks is also promoted. However, preliminary attempts mainly focus on generation performance, but are still inferior on recognition tasks. These methods are modeled in the vector-quantized (VQ) space, whereas leading recognition methods use pixels as inputs. Our key insights are twofold: (1) pixels as inputs are crucial for recognition tasks; (2) VQ tokens as reconstruction targets are beneficial for generation tasks. These observations motivate us to propose an Alternating Denoising Diffusion Process (ADDP) that integrates these two spaces within a single representation learning framework. In each denoising step, our method first decodes pixels from previous VQ tokens, then generates new VQ tokens from the decoded pixels. The diffusion process gradually masks out a portion of VQ tokens to construct the training samples. The learned representations can be used to generate diverse high-fidelity images and also demonstrate excellent transfer performance on recognition tasks. Extensive experiments show that our method achieves competitive performance on unconditional generation, ImageNet classification, COCO detection, and ADE20k segmentation. Importantly, our method represents the first successful development of general representations applicable to both generation and dense recognition tasks. Code is released at url{https://github.com/ChangyaoTian/ADDP}.
Create account to get full access
Overview
- Image recognition and generation have historically been separate tasks, but recent trends have focused on developing general-purpose representation learning that can handle both.
- Existing methods that combine recognition and generation tend to perform better on generation tasks than recognition tasks.
- This paper proposes a new approach called the Alternating Denoising Diffusion Process (ADDP) that aims to learn representations suitable for both recognition and generation.
Plain English Explanation
Recognizing objects in images and creating new images from scratch are two very different skills that have traditionally been developed independently. However, researchers have become interested in finding a single approach that can handle both tasks well.
Previous attempts to develop a general-purpose representation have made progress on image generation, but still struggle with recognition performance. The key insight of this paper is that pixels are crucial for recognition, while vector-quantized (VQ) tokens are better suited for generation.
The Alternating Denoising Diffusion Process (ADDP) combines these two spaces in a single framework. In each training step, the model first decodes pixels from VQ tokens, then uses those pixels to generate new VQ tokens. This alternating process gradually masks out the VQ tokens, forcing the model to learn robust representations that work for both recognition and generation.
The benefit of this approach is that the learned representations can be used to create diverse, high-quality images, as well as perform well on tasks like image classification, object detection, and semantic segmentation. This is an important step towards developing AI systems that can understand and interact with the visual world in versatile ways.
Technical Explanation
The core of the ADDP model is an iterative process that alternates between decoding pixels from VQ tokens and then generating new VQ tokens from those pixels.
In each denoising step, the model first decodes pixels from the previous set of VQ tokens. It then uses those pixels to produce a new set of VQ tokens, gradually masking out more of the original tokens over the course of training. This forces the model to learn representations that can capture the essential visual information in a compact VQ form, while still preserving the pixel-level details needed for recognition tasks.
The VQ tokens serve as the interface between the recognition and generation components of the model. The VQ space is optimized for generation performance, while the pixel-level decoding enables strong transfer learning capabilities for recognition tasks like classification, detection, and segmentation.
Extensive experiments show that this approach achieves competitive results on a range of visual benchmarks, including unconditional image generation, ImageNet classification, COCO object detection, and ADE20k semantic segmentation. Importantly, this is the first method to successfully develop general representations that work well for both generation and dense recognition tasks.
Critical Analysis
A key contribution of this work is the insight that using pixels as inputs is crucial for recognition tasks, while VQ tokens are more suitable as reconstruction targets for generation. This observation underlies the design of the ADDP model and helps explain why previous approaches that focused solely on the VQ space struggled with recognition performance.
That said, the paper does not provide a deep analysis of why this split between pixels and VQ tokens is beneficial. More discussion of the complementary strengths and limitations of each representation could further illuminate the core principles behind the ADDP architecture.
Additionally, while the model achieves impressive results across a range of benchmarks, the paper does not explore potential tradeoffs or unexpected behaviors that may arise when using the same representation for both generation and recognition. Investigating such edge cases could uncover important limitations or areas for improvement.
Overall, the ADDP represents a promising step towards general-purpose visual understanding, but continued research is needed to fully understand the underlying mechanisms and potential issues with this approach.
Conclusion
This paper introduces the Alternating Denoising Diffusion Process (ADDP), a new representation learning framework that can effectively handle both image recognition and generation tasks. By alternating between decoding pixels from VQ tokens and generating new VQ tokens from those pixels, the model learns a versatile representation that excels at both tasks.
The key insight of separating the pixel and VQ spaces, with pixels as the input for recognition and VQ tokens as the targets for generation, is a crucial innovation that allows ADDP to outperform previous attempts at general-purpose visual understanding. This work represents an important step towards developing AI systems that can truly comprehend and interact with the visual world in flexible and powerful ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
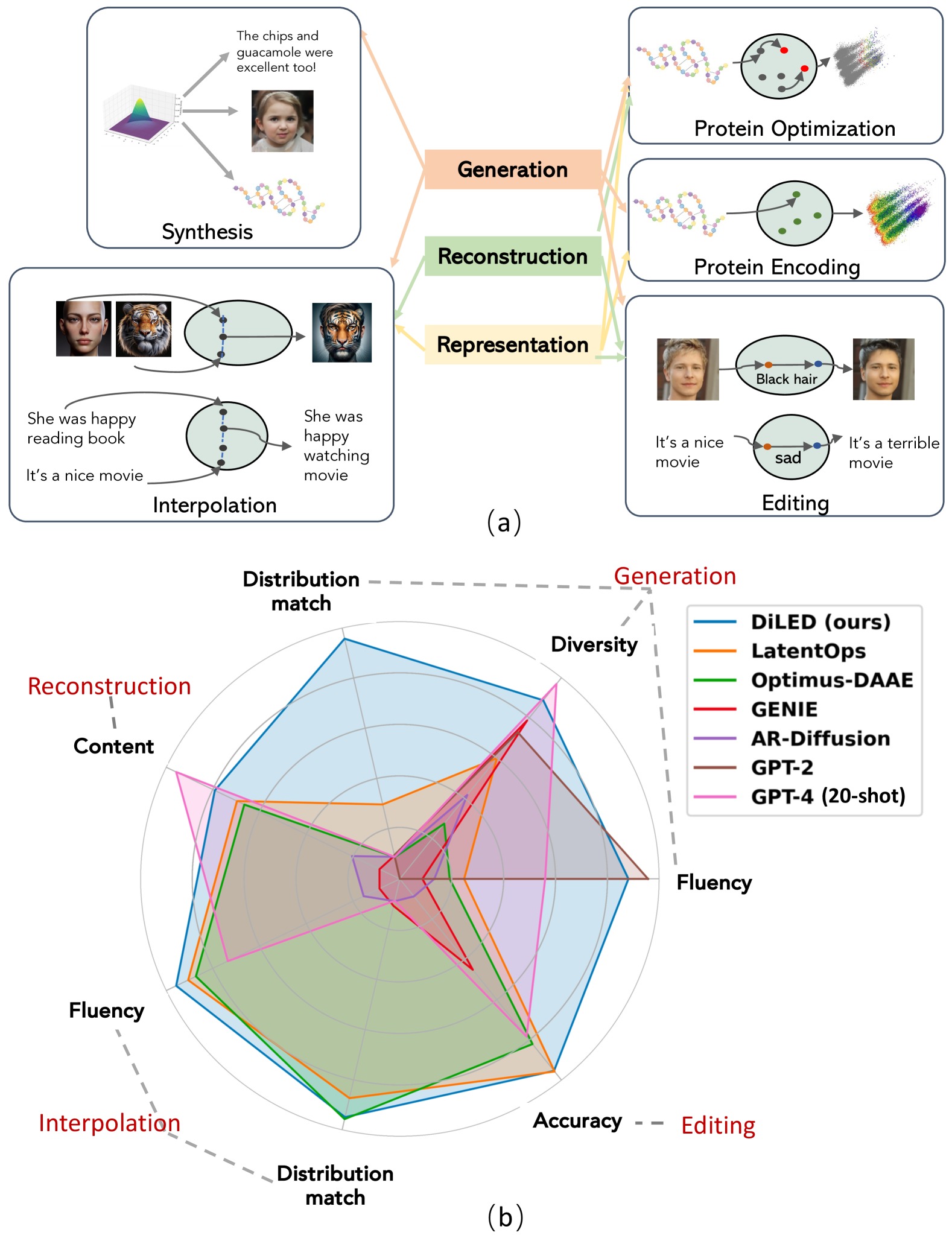
Unified Generation, Reconstruction, and Representation: Generalized Diffusion with Adaptive Latent Encoding-Decoding
Guangyi Liu, Yu Wang, Zeyu Feng, Qiyu Wu, Liping Tang, Yuan Gao, Zhen Li, Shuguang Cui, Julian McAuley, Zichao Yang, Eric P. Xing, Zhiting Hu
0
0
The vast applications of deep generative models are anchored in three core capabilities -- generating new instances, reconstructing inputs, and learning compact representations -- across various data types, such as discrete text/protein sequences and continuous images. Existing model families, like variational autoencoders (VAEs), generative adversarial networks (GANs), autoregressive models, and (latent) diffusion models, generally excel in specific capabilities and data types but fall short in others. We introduce Generalized Encoding-Decoding Diffusion Probabilistic Models (EDDPMs) which integrate the core capabilities for broad applicability and enhanced performance. EDDPMs generalize the Gaussian noising-denoising in standard diffusion by introducing parameterized encoding-decoding. Crucially, EDDPMs are compatible with the well-established diffusion model objective and training recipes, allowing effective learning of the encoder-decoder parameters jointly with diffusion. By choosing appropriate encoder/decoder (e.g., large language models), EDDPMs naturally apply to different data types. Extensive experiments on text, proteins, and images demonstrate the flexibility to handle diverse data and tasks and the strong improvement over various existing models.
6/6/2024
🎯
Generalization in diffusion models arises from geometry-adaptive harmonic representations
Zahra Kadkhodaie, Florentin Guth, Eero P. Simoncelli, St'ephane Mallat
0
0
Deep neural networks (DNNs) trained for image denoising are able to generate high-quality samples with score-based reverse diffusion algorithms. These impressive capabilities seem to imply an escape from the curse of dimensionality, but recent reports of memorization of the training set raise the question of whether these networks are learning the true continuous density of the data. Here, we show that two DNNs trained on non-overlapping subsets of a dataset learn nearly the same score function, and thus the same density, when the number of training images is large enough. In this regime of strong generalization, diffusion-generated images are distinct from the training set, and are of high visual quality, suggesting that the inductive biases of the DNNs are well-aligned with the data density. We analyze the learned denoising functions and show that the inductive biases give rise to a shrinkage operation in a basis adapted to the underlying image. Examination of these bases reveals oscillating harmonic structures along contours and in homogeneous regions. We demonstrate that trained denoisers are inductively biased towards these geometry-adaptive harmonic bases since they arise not only when the network is trained on photographic images, but also when it is trained on image classes supported on low-dimensional manifolds for which the harmonic basis is suboptimal. Finally, we show that when trained on regular image classes for which the optimal basis is known to be geometry-adaptive and harmonic, the denoising performance of the networks is near-optimal.
4/15/2024
➖
Masked Diffusion as Self-supervised Representation Learner
Zixuan Pan, Jianxu Chen, Yiyu Shi
0
0
Denoising diffusion probabilistic models have recently demonstrated state-of-the-art generative performance and have been used as strong pixel-level representation learners. This paper decomposes the interrelation between the generative capability and representation learning ability inherent in diffusion models. We present the masked diffusion model (MDM), a scalable self-supervised representation learner for semantic segmentation, substituting the conventional additive Gaussian noise of traditional diffusion with a masking mechanism. Our proposed approach convincingly surpasses prior benchmarks, demonstrating remarkable advancements in both medical and natural image semantic segmentation tasks, particularly in few-shot scenarios.
4/16/2024

Adv-KD: Adversarial Knowledge Distillation for Faster Diffusion Sampling
Kidist Amde Mekonnen, Nicola Dall'Asen, Paolo Rota
0
0
Diffusion Probabilistic Models (DPMs) have emerged as a powerful class of deep generative models, achieving remarkable performance in image synthesis tasks. However, these models face challenges in terms of widespread adoption due to their reliance on sequential denoising steps during sample generation. This dependence leads to substantial computational requirements, making them unsuitable for resource-constrained or real-time processing systems. To address these challenges, we propose a novel method that integrates denoising phases directly into the model's architecture, thereby reducing the need for resource-intensive computations. Our approach combines diffusion models with generative adversarial networks (GANs) through knowledge distillation, enabling more efficient training and evaluation. By utilizing a pre-trained diffusion model as a teacher model, we train a student model through adversarial learning, employing layerwise transformations for denoising and submodules for predicting the teacher model's output at various points in time. This integration significantly reduces the number of parameters and denoising steps required, leading to improved sampling speed at test time. We validate our method with extensive experiments, demonstrating comparable performance with reduced computational requirements compared to existing approaches. By enabling the deployment of diffusion models on resource-constrained devices, our research mitigates their computational burden and paves the way for wider accessibility and practical use across the research community and end-users. Our code is publicly available at https://github.com/kidist-amde/Adv-KD
6/3/2024