Advancing Annotation of Stance in Social Media Posts: A Comparative Analysis of Large Language Models and Crowd Sourcing
2406.07483
0
0
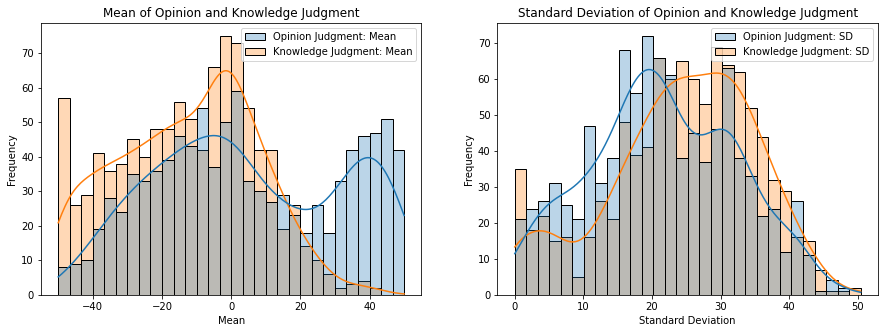
Abstract
In the rapidly evolving landscape of Natural Language Processing (NLP), the use of Large Language Models (LLMs) for automated text annotation in social media posts has garnered significant interest. Despite the impressive innovations in developing LLMs like ChatGPT, their efficacy, and accuracy as annotation tools are not well understood. In this paper, we analyze the performance of eight open-source and proprietary LLMs for annotating the stance expressed in social media posts, benchmarking their performance against human annotators' (i.e., crowd-sourced) judgments. Additionally, we investigate the conditions under which LLMs are likely to disagree with human judgment. A significant finding of our study is that the explicitness of text expressing a stance plays a critical role in how faithfully LLMs' stance judgments match humans'. We argue that LLMs perform well when human annotators do, and when LLMs fail, it often corresponds to situations in which human annotators struggle to reach an agreement. We conclude with recommendations for a comprehensive approach that combines the precision of human expertise with the scalability of LLM predictions. This study highlights the importance of improving the accuracy and comprehensiveness of automated stance detection, aiming to advance these technologies for more efficient and unbiased analysis of social media.
Create account to get full access
Overview
- Examines the effectiveness of large language models (LLMs) and crowd-sourcing for annotating stance in social media posts
- Compares the performance of fine-tuned LLMs and crowd-sourced human annotators on a stance detection task
- Explores the potential for collaborative models that leverage both LLMs and human annotators
Plain English Explanation
This research paper investigates different approaches to annotating the stance or perspective expressed in social media posts. Stance detection is the process of identifying whether a piece of text expresses support, opposition, or neutrality towards a particular topic or issue.
The researchers compare two main methods for stance annotation: using fine-tuned large language models (LLMs) and crowd-sourcing human annotators. LLMs are advanced AI systems that can understand and generate human-like text. The researchers trained LLMs on stance detection tasks and evaluated their performance. They also looked at how well a group of human workers, recruited online, could annotate the stance in social media posts.
By analyzing the results, the researchers aim to understand the relative strengths and weaknesses of these two approaches. They explore the potential for combining LLMs and human annotators in a collaborative system to leverage the benefits of both. The research also provides insights into making LLMs more effective as annotators and using open-source LLMs for text annotation tasks.
Technical Explanation
The researchers conducted experiments using a dataset of social media posts related to various controversial topics, such as gun control and abortion. They fine-tuned several large language models, including BERT, RoBERTa, and GPT-3, on the task of stance detection in social media posts. The performance of these fine-tuned LLMs was then compared to the annotations provided by a crowd of human workers recruited through an online platform.
The results showed that the LLMs generally outperformed the crowd-sourced human annotators in terms of accuracy, consistency, and efficiency. However, the human annotators provided more nuanced and context-sensitive annotations in some cases. The researchers conclude that a collaborative approach leveraging both LLMs and human annotators could be a promising direction for future research.
Critical Analysis
The paper acknowledges some limitations of the study, such as the potential bias in the dataset and the difficulty of defining "ground truth" stance annotations. Additionally, the researchers note that the performance of the LLMs may be influenced by factors like the quality and size of the training data, the specific fine-tuning approach, and the choice of language model architecture.
One concern that the paper does not address is the potential for LLMs to perpetuate or amplify societal biases, which could be problematic in the context of stance detection on sensitive topics. Further research is needed to understand and mitigate these issues.
Additionally, the paper does not provide a detailed analysis of the qualitative differences between the LLM and human annotations, nor does it explore the potential trade-offs between accuracy, efficiency, and nuance in real-world applications of stance detection systems.
Conclusion
This research demonstrates the potential for using fine-tuned large language models as a tool for annotating stance in social media posts, with potential advantages in terms of accuracy, consistency, and scalability. However, it also highlights the value of human annotators and the need for a collaborative approach that leverages the strengths of both LLMs and crowd-sourced annotations.
The findings of this study could have important implications for the development of more effective and nuanced stance detection systems, which could be useful in a variety of applications, such as social media analysis, political discourse monitoring, and online content moderation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Stance Detection on Social Media with Fine-Tuned Large Language Models
.Ilker Gul, R'emi Lebret, Karl Aberer
0
0
Stance detection, a key task in natural language processing, determines an author's viewpoint based on textual analysis. This study evaluates the evolution of stance detection methods, transitioning from early machine learning approaches to the groundbreaking BERT model, and eventually to modern Large Language Models (LLMs) such as ChatGPT, LLaMa-2, and Mistral-7B. While ChatGPT's closed-source nature and associated costs present challenges, the open-source models like LLaMa-2 and Mistral-7B offers an encouraging alternative. Initially, our research focused on fine-tuning ChatGPT, LLaMa-2, and Mistral-7B using several publicly available datasets. Subsequently, to provide a comprehensive comparison, we assess the performance of these models in zero-shot and few-shot learning scenarios. The results underscore the exceptional ability of LLMs in accurately detecting stance, with all tested models surpassing existing benchmarks. Notably, LLaMa-2 and Mistral-7B demonstrate remarkable efficiency and potential for stance detection, despite their smaller sizes compared to ChatGPT. This study emphasizes the potential of LLMs in stance detection and calls for more extensive research in this field.
4/19/2024

The Effectiveness of LLMs as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation
Maja Pavlovic, Massimo Poesio
0
0
Large Language Models (LLMs) have emerged as powerful support tools across various natural language tasks and a range of application domains. Recent studies focus on exploring their capabilities for data annotation. This paper provides a comparative overview of twelve studies investigating the potential of LLMs in labelling data. While the models demonstrate promising cost and time-saving benefits, there exist considerable limitations, such as representativeness, bias, sensitivity to prompt variations and English language preference. Leveraging insights from these studies, our empirical analysis further examines the alignment between human and GPT-generated opinion distributions across four subjective datasets. In contrast to the studies examining representation, our methodology directly obtains the opinion distribution from GPT. Our analysis thereby supports the minority of studies that are considering diverse perspectives when evaluating data annotation tasks and highlights the need for further research in this direction.
5/3/2024
🔎
Stance Detection with Collaborative Role-Infused LLM-Based Agents
Xiaochong Lan, Chen Gao, Depeng Jin, Yong Li
0
0
Stance detection automatically detects the stance in a text towards a target, vital for content analysis in web and social media research. Despite their promising capabilities, LLMs encounter challenges when directly applied to stance detection. First, stance detection demands multi-aspect knowledge, from deciphering event-related terminologies to understanding the expression styles in social media platforms. Second, stance detection requires advanced reasoning to infer authors' implicit viewpoints, as stance are often subtly embedded rather than overtly stated in the text. To address these challenges, we design a three-stage framework COLA (short for Collaborative rOle-infused LLM-based Agents) in which LLMs are designated distinct roles, creating a collaborative system where each role contributes uniquely. Initially, in the multidimensional text analysis stage, we configure the LLMs to act as a linguistic expert, a domain specialist, and a social media veteran to get a multifaceted analysis of texts, thus overcoming the first challenge. Next, in the reasoning-enhanced debating stage, for each potential stance, we designate a specific LLM-based agent to advocate for it, guiding the LLM to detect logical connections between text features and stance, tackling the second challenge. Finally, in the stance conclusion stage, a final decision maker agent consolidates prior insights to determine the stance. Our approach avoids extra annotated data and model training and is highly usable. We achieve state-of-the-art performance across multiple datasets. Ablation studies validate the effectiveness of each design role in handling stance detection. Further experiments have demonstrated the explainability and the versatility of our approach. Our approach excels in usability, accuracy, effectiveness, explainability and versatility, highlighting its value.
4/17/2024
💬
AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
Xingwei He, Zhenghao Lin, Yeyun Gong, A-Long Jin, Hang Zhang, Chen Lin, Jian Jiao, Siu Ming Yiu, Nan Duan, Weizhu Chen
0
0
Many natural language processing (NLP) tasks rely on labeled data to train machine learning models with high performance. However, data annotation is time-consuming and expensive, especially when the task involves a large amount of data or requires specialized domains. Recently, GPT-3.5 series models have demonstrated remarkable few-shot and zero-shot ability across various NLP tasks. In this paper, we first claim that large language models (LLMs), such as GPT-3.5, can serve as an excellent crowdsourced annotator when provided with sufficient guidance and demonstrated examples. Accordingly, we propose AnnoLLM, an annotation system powered by LLMs, which adopts a two-step approach, explain-then-annotate. Concretely, we first prompt LLMs to provide explanations for why the specific ground truth answer/label was assigned for a given example. Then, we construct the few-shot chain-of-thought prompt with the self-generated explanation and employ it to annotate the unlabeled data with LLMs. Our experiment results on three tasks, including user input and keyword relevance assessment, BoolQ, and WiC, demonstrate that AnnoLLM surpasses or performs on par with crowdsourced annotators. Furthermore, we build the first conversation-based information retrieval dataset employing AnnoLLM. This dataset is designed to facilitate the development of retrieval models capable of retrieving pertinent documents for conversational text. Human evaluation has validated the dataset's high quality.
4/8/2024