Advancing Anomaly Detection: Non-Semantic Financial Data Encoding with LLMs

0
❗
Sign in to get full access
Overview
- Detecting anomalies in financial data is crucial for ensuring the trustworthiness of financial records.
- This paper explores using Large Language Models (LLMs) to enhance anomaly detection in financial journal entries.
- The authors tested three pre-trained sentence-transformer models to encode non-semantic categorical data from real-world financial records.
- They then implemented and evaluated five optimized machine learning models for the downstream classification task.
Plain English Explanation
Keeping financial records accurate and reliable is extremely important. In this study, the researchers looked at using Large Language Models (LLMs) to help identify unusual or potentially fraudulent entries in financial data.
Financial data can be complex, with many different types of information (called "features") that describe each transaction. The researchers tested three different pre-trained language models to convert the non-numerical parts of the financial data into a format that machine learning algorithms could understand.
They then tried out five different machine learning models to actually detect the anomalies, or irregular entries, in the financial data. Their results showed that using the language model embeddings helped the machine learning models perform better at identifying suspicious transactions, especially when dealing with data that had a lot of different features.
The researchers believe this approach of using LLMs to encode non-semantic data could be useful not just for financial auditing, but for anomaly detection in other complex datasets as well.
Technical Explanation
The paper explores the use of Large Language Models (LLMs) to enhance anomaly detection in financial journal entries, which is a key task in ensuring the trustworthiness of financial records.
To encode the non-semantic categorical data from real-world financial records, the authors tested three pre-trained general purpose sentence-transformer models: SBERT, Roberta-base, and DistilBERT. These LLMs were used to generate embeddings that capture the semantic and contextual information in the financial data.
For the downstream classification task of detecting anomalies, the researchers implemented and evaluated five optimized machine learning models: Logistic Regression, Random Forest, Gradient Boosting Machines, Support Vector Machines, and Neural Networks. The performance of these models was assessed using the LLM embeddings as additional features.
The experimental results demonstrate that the LLM embeddings contribute valuable information to the anomaly detection task, as the models leveraging the embeddings outperformed the baselines, in some cases by a large margin. The findings underscore the effectiveness of LLMs in enhancing anomaly detection in financial journal entries, particularly by addressing the challenge of feature sparsity.
Critical Analysis
The paper presents a promising approach to leveraging LLMs for anomaly detection in financial data. However, the authors acknowledge some limitations and areas for further research:
- The study focuses on a single dataset of financial journal entries, and the generalizability of the findings to other financial datasets or domains is not yet established.
- The performance improvements provided by the LLM embeddings, while significant, may still not be sufficient for practical deployment in high-stakes financial auditing scenarios, where extremely low false positive rates are required.
- The paper does not explore the interpretability of the LLM-enhanced models, which is an important consideration for real-world applications where the reasoning behind anomaly detection needs to be transparent.
Future research could investigate the use of LLMs for anomaly detection in a broader range of financial data, as well as explore techniques to improve the reliability and interpretability of the models.
Conclusion
This study demonstrates the potential of using LLMs for anomaly detection in financial data. By leveraging the semantic and contextual information captured by pre-trained language models, the researchers were able to enhance the performance of various machine learning algorithms in identifying irregularities in financial journal entries.
The findings highlight the value of LLMs in tackling the challenge of feature sparsity and heterogeneity, which is a common issue in complex financial datasets. This approach could have important implications for improving the reliability and trustworthiness of financial records, contributing to more robust and transparent financial auditing practices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
0
Advancing Anomaly Detection: Non-Semantic Financial Data Encoding with LLMs
Alexander Bakumenko (Clemson University, USA), Katev{r}ina Hlav'av{c}kov'a-Schindler (University of Vienna, Austria), Claudia Plant (University of Vienna, Austria), Nina C. Hubig (Clemson University, USA)
Detecting anomalies in general ledger data is of utmost importance to ensure trustworthiness of financial records. Financial audits increasingly rely on machine learning (ML) algorithms to identify irregular or potentially fraudulent journal entries, each characterized by a varying number of transactions. In machine learning, heterogeneity in feature dimensions adds significant complexity to data analysis. In this paper, we introduce a novel approach to anomaly detection in financial data using Large Language Models (LLMs) embeddings. To encode non-semantic categorical data from real-world financial records, we tested 3 pre-trained general purpose sentence-transformer models. For the downstream classification task, we implemented and evaluated 5 optimized ML models including Logistic Regression, Random Forest, Gradient Boosting Machines, Support Vector Machines, and Neural Networks. Our experiments demonstrate that LLMs contribute valuable information to anomaly detection as our models outperform the baselines, in selected settings even by a large margin. The findings further underscore the effectiveness of LLMs in enhancing anomaly detection in financial journal entries, particularly by tackling feature sparsity. We discuss a promising perspective on using LLM embeddings for non-semantic data in the financial context and beyond.
Read more6/7/2024

0
Anomaly Detection of Tabular Data Using LLMs
Aodong Li, Yunhan Zhao, Chen Qiu, Marius Kloft, Padhraic Smyth, Maja Rudolph, Stephan Mandt
Large language models (LLMs) have shown their potential in long-context understanding and mathematical reasoning. In this paper, we study the problem of using LLMs to detect tabular anomalies and show that pre-trained LLMs are zero-shot batch-level anomaly detectors. That is, without extra distribution-specific model fitting, they can discover hidden outliers in a batch of data, demonstrating their ability to identify low-density data regions. For LLMs that are not well aligned with anomaly detection and frequently output factual errors, we apply simple yet effective data-generating processes to simulate synthetic batch-level anomaly detection datasets and propose an end-to-end fine-tuning strategy to bring out the potential of LLMs in detecting real anomalies. Experiments on a large anomaly detection benchmark (ODDS) showcase i) GPT-4 has on-par performance with the state-of-the-art transductive learning-based anomaly detection methods and ii) the efficacy of our synthetic dataset and fine-tuning strategy in aligning LLMs to this task.
Read more6/26/2024
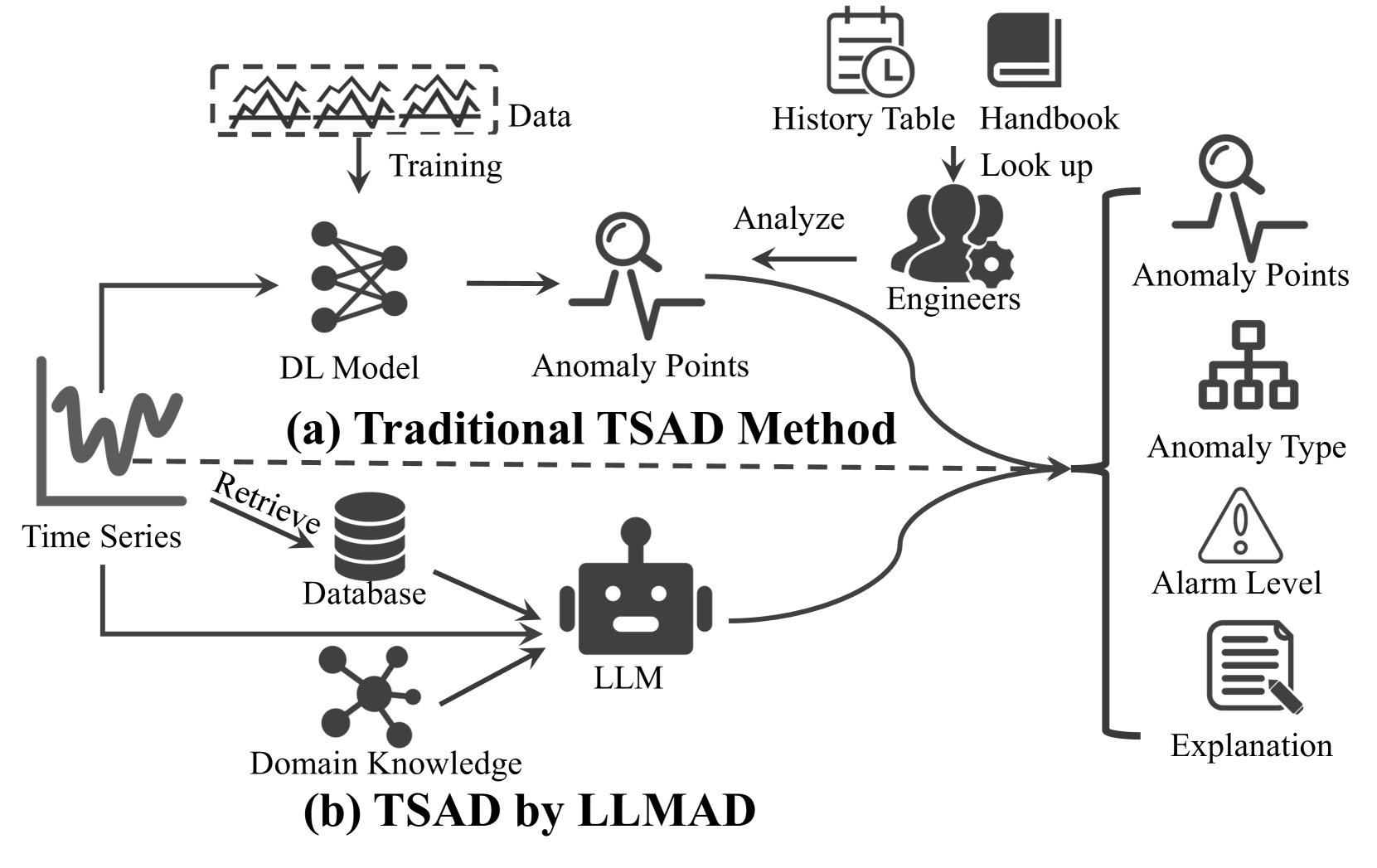
0
Large Language Models can Deliver Accurate and Interpretable Time Series Anomaly Detection
Jun Liu, Chaoyun Zhang, Jiaxu Qian, Minghua Ma, Si Qin, Chetan Bansal, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang
Time series anomaly detection (TSAD) plays a crucial role in various industries by identifying atypical patterns that deviate from standard trends, thereby maintaining system integrity and enabling prompt response measures. Traditional TSAD models, which often rely on deep learning, require extensive training data and operate as black boxes, lacking interpretability for detected anomalies. To address these challenges, we propose LLMAD, a novel TSAD method that employs Large Language Models (LLMs) to deliver accurate and interpretable TSAD results. LLMAD innovatively applies LLMs for in-context anomaly detection by retrieving both positive and negative similar time series segments, significantly enhancing LLMs' effectiveness. Furthermore, LLMAD employs the Anomaly Detection Chain-of-Thought (AnoCoT) approach to mimic expert logic for its decision-making process. This method further enhances its performance and enables LLMAD to provide explanations for their detections through versatile perspectives, which are particularly important for user decision-making. Experiments on three datasets indicate that our LLMAD achieves detection performance comparable to state-of-the-art deep learning methods while offering remarkable interpretability for detections. To the best of our knowledge, this is the first work that directly employs LLMs for TSAD.
Read more5/27/2024
❗
0
AnomalyLLM: Few-shot Anomaly Edge Detection for Dynamic Graphs using Large Language Models
Shuo Liu, Di Yao, Lanting Fang, Zhetao Li, Wenbin Li, Kaiyu Feng, XiaoWen Ji, Jingping Bi
Detecting anomaly edges for dynamic graphs aims to identify edges significantly deviating from the normal pattern and can be applied in various domains, such as cybersecurity, financial transactions and AIOps. With the evolving of time, the types of anomaly edges are emerging and the labeled anomaly samples are few for each type. Current methods are either designed to detect randomly inserted edges or require sufficient labeled data for model training, which harms their applicability for real-world applications. In this paper, we study this problem by cooperating with the rich knowledge encoded in large language models(LLMs) and propose a method, namely AnomalyLLM. To align the dynamic graph with LLMs, AnomalyLLM pre-trains a dynamic-aware encoder to generate the representations of edges and reprograms the edges using the prototypes of word embeddings. Along with the encoder, we design an in-context learning framework that integrates the information of a few labeled samples to achieve few-shot anomaly detection. Experiments on four datasets reveal that AnomalyLLM can not only significantly improve the performance of few-shot anomaly detection, but also achieve superior results on new anomalies without any update of model parameters.
Read more8/29/2024