Large language models can be zero-shot anomaly detectors for time series?
2405.14755
0
0
💬
Abstract
Recent studies have shown the ability of large language models to perform a variety of tasks, including time series forecasting. The flexible nature of these models allows them to be used for many applications. In this paper, we present a novel study of large language models used for the challenging task of time series anomaly detection. This problem entails two aspects novel for LLMs: the need for the model to identify part of the input sequence (or multiple parts) as anomalous; and the need for it to work with time series data rather than the traditional text input. We introduce sigllm, a framework for time series anomaly detection using large language models. Our framework includes a time-series-to-text conversion module, as well as end-to-end pipelines that prompt language models to perform time series anomaly detection. We investigate two paradigms for testing the abilities of large language models to perform the detection task. First, we present a prompt-based detection method that directly asks a language model to indicate which elements of the input are anomalies. Second, we leverage the forecasting capability of a large language model to guide the anomaly detection process. We evaluated our framework on 11 datasets spanning various sources and 10 pipelines. We show that the forecasting method significantly outperformed the prompting method in all 11 datasets with respect to the F1 score. Moreover, while large language models are capable of finding anomalies, state-of-the-art deep learning models are still superior in performance, achieving results 30% better than large language models.
Create account to get full access
Overview
- Recent studies have shown that large language models (LLMs) can perform a variety of tasks, including time series forecasting.
- This paper presents a novel study on using LLMs for the challenging task of time series anomaly detection.
- The key aspects are the need for the model to identify anomalous parts of the input sequence, and the use of time series data rather than traditional text input.
- The authors introduce sigllm, a framework for time series anomaly detection using LLMs.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can understand and generate human-like text. Recent research has shown that these models are surprisingly capable at a wide range of tasks, including predicting future values in time series data.
In this study, the researchers explored using LLMs for a specific type of time series analysis: anomaly detection. Anomaly detection is the process of identifying unusual or abnormal patterns in data that may indicate something important, like a system failure or a security breach.
Applying LLMs to this problem is novel because it requires the model to do two things it hasn't traditionally been asked to do: 1) Identify specific parts of the input sequence as anomalous, rather than just classifying the entire sequence; and 2) Work with time series data, which has a temporal structure, rather than the more common text data.
To address these challenges, the researchers developed a framework called sigllm that includes tools for converting time series data into a format that LLMs can understand, as well as methods for prompting the LLMs to detect anomalies.
The researchers tested their framework on 11 different datasets and compared the performance of LLMs to state-of-the-art deep learning models. While the LLMs were able to detect anomalies, the deep learning models still outperformed them, achieving results that were about 30% better.
Technical Explanation
The researchers introduced a framework called sigllm for using large language models (LLMs) to perform time series anomaly detection. This task is novel for LLMs because it requires them to:
- Identify anomalous parts of the input sequence: Rather than just classifying the entire sequence as normal or anomalous, the model needs to pinpoint the specific elements that are unusual.
- Work with time series data: LLMs are typically trained on text data, which lacks the temporal structure of time series data.
To address these challenges, the sigllm framework includes a time-series-to-text conversion module, as well as end-to-end pipelines that prompt LLMs to perform the anomaly detection task.
The researchers investigated two main approaches:
- Prompt-based detection: Directly asking the LLM to indicate which parts of the input are anomalous.
- Forecasting-based detection: Leveraging the LLM's ability to forecast future time series values to guide the anomaly detection process.
They evaluated their framework on 11 datasets spanning various sources and 10 pipelines. The results showed that the forecasting-based method significantly outperformed the prompting method across all 11 datasets in terms of F1 score.
However, while the LLMs were able to identify anomalies, the researchers found that state-of-the-art deep learning models still achieved results that were about 30% better than the LLMs.
Critical Analysis
The researchers acknowledge several limitations and areas for further research in their paper:
- The sigllm framework relies on a time-series-to-text conversion module, which may introduce additional complexity and potential sources of error. Exploring more direct ways of using LLMs with time series data could be a fruitful area for future work.
- The study focused on a binary anomaly detection task (normal vs. anomalous), but real-world scenarios often involve more nuanced classifications of anomalies. Extending the framework to handle more complex anomaly types could be valuable.
- While the researchers compared LLMs to state-of-the-art deep learning models, it would be interesting to see how the LLMs perform relative to other time series anomaly detection techniques, such as statistical methods or hybrid approaches.
Additionally, the paper does not address the interpretability of the LLM-based anomaly detection process. Providing explanations for the model's decisions could be important for certain applications, such as medical diagnostics or fraud detection, where transparency is crucial.
Conclusion
This paper presents a novel framework, sigllm, for using large language models (LLMs) to perform time series anomaly detection. The key innovations are the ability to identify anomalous parts of the input sequence and the use of time series data, which is a departure from the traditional text data that LLMs are typically trained on.
While the researchers found that LLMs can successfully detect anomalies, state-of-the-art deep learning models still outperform them by a significant margin. The paper also highlights several areas for future research, such as exploring more direct ways of using LLMs with time series data and extending the framework to handle more complex anomaly types.
Overall, this study contributes to the growing body of research on the capabilities and limitations of LLMs, particularly in the context of time series analysis tasks. As these models continue to evolve, they may become increasingly useful tools for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
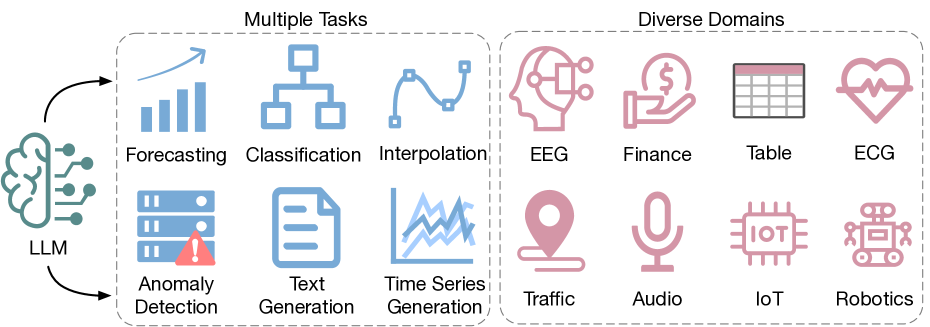
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024

Large Language Models Are Zero-Shot Time Series Forecasters
Nate Gruver, Marc Finzi, Shikai Qiu, Andrew Gordon Wilson
0
0
By encoding time series as a string of numerical digits, we can frame time series forecasting as next-token prediction in text. Developing this approach, we find that large language models (LLMs) such as GPT-3 and LLaMA-2 can surprisingly zero-shot extrapolate time series at a level comparable to or exceeding the performance of purpose-built time series models trained on the downstream tasks. To facilitate this performance, we propose procedures for effectively tokenizing time series data and converting discrete distributions over tokens into highly flexible densities over continuous values. We argue the success of LLMs for time series stems from their ability to naturally represent multimodal distributions, in conjunction with biases for simplicity, and repetition, which align with the salient features in many time series, such as repeated seasonal trends. We also show how LLMs can naturally handle missing data without imputation through non-numerical text, accommodate textual side information, and answer questions to help explain predictions. While we find that increasing model size generally improves performance on time series, we show GPT-4 can perform worse than GPT-3 because of how it tokenizes numbers, and poor uncertainty calibration, which is likely the result of alignment interventions such as RLHF.
6/19/2024
Large Language Models can Deliver Accurate and Interpretable Time Series Anomaly Detection
Jun Liu, Chaoyun Zhang, Jiaxu Qian, Minghua Ma, Si Qin, Chetan Bansal, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang
0
0
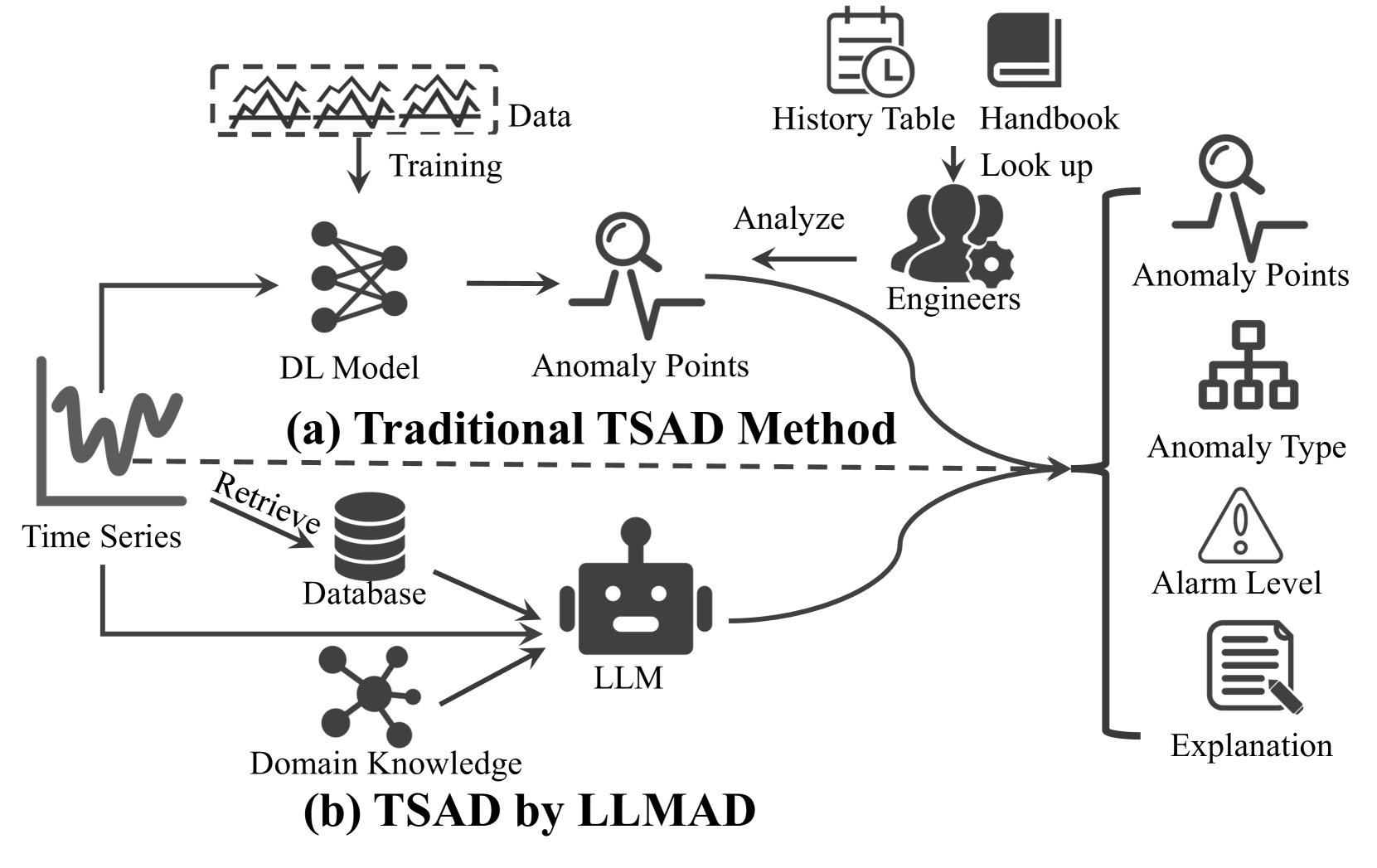
Time series anomaly detection (TSAD) plays a crucial role in various industries by identifying atypical patterns that deviate from standard trends, thereby maintaining system integrity and enabling prompt response measures. Traditional TSAD models, which often rely on deep learning, require extensive training data and operate as black boxes, lacking interpretability for detected anomalies. To address these challenges, we propose LLMAD, a novel TSAD method that employs Large Language Models (LLMs) to deliver accurate and interpretable TSAD results. LLMAD innovatively applies LLMs for in-context anomaly detection by retrieving both positive and negative similar time series segments, significantly enhancing LLMs' effectiveness. Furthermore, LLMAD employs the Anomaly Detection Chain-of-Thought (AnoCoT) approach to mimic expert logic for its decision-making process. This method further enhances its performance and enables LLMAD to provide explanations for their detections through versatile perspectives, which are particularly important for user decision-making. Experiments on three datasets indicate that our LLMAD achieves detection performance comparable to state-of-the-art deep learning methods while offering remarkable interpretability for detections. To the best of our knowledge, this is the first work that directly employs LLMs for TSAD.
5/27/2024
Position: What Can Large Language Models Tell Us about Time Series Analysis
Ming Jin, Yifan Zhang, Wei Chen, Kexin Zhang, Yuxuan Liang, Bin Yang, Jindong Wang, Shirui Pan, Qingsong Wen
0
0
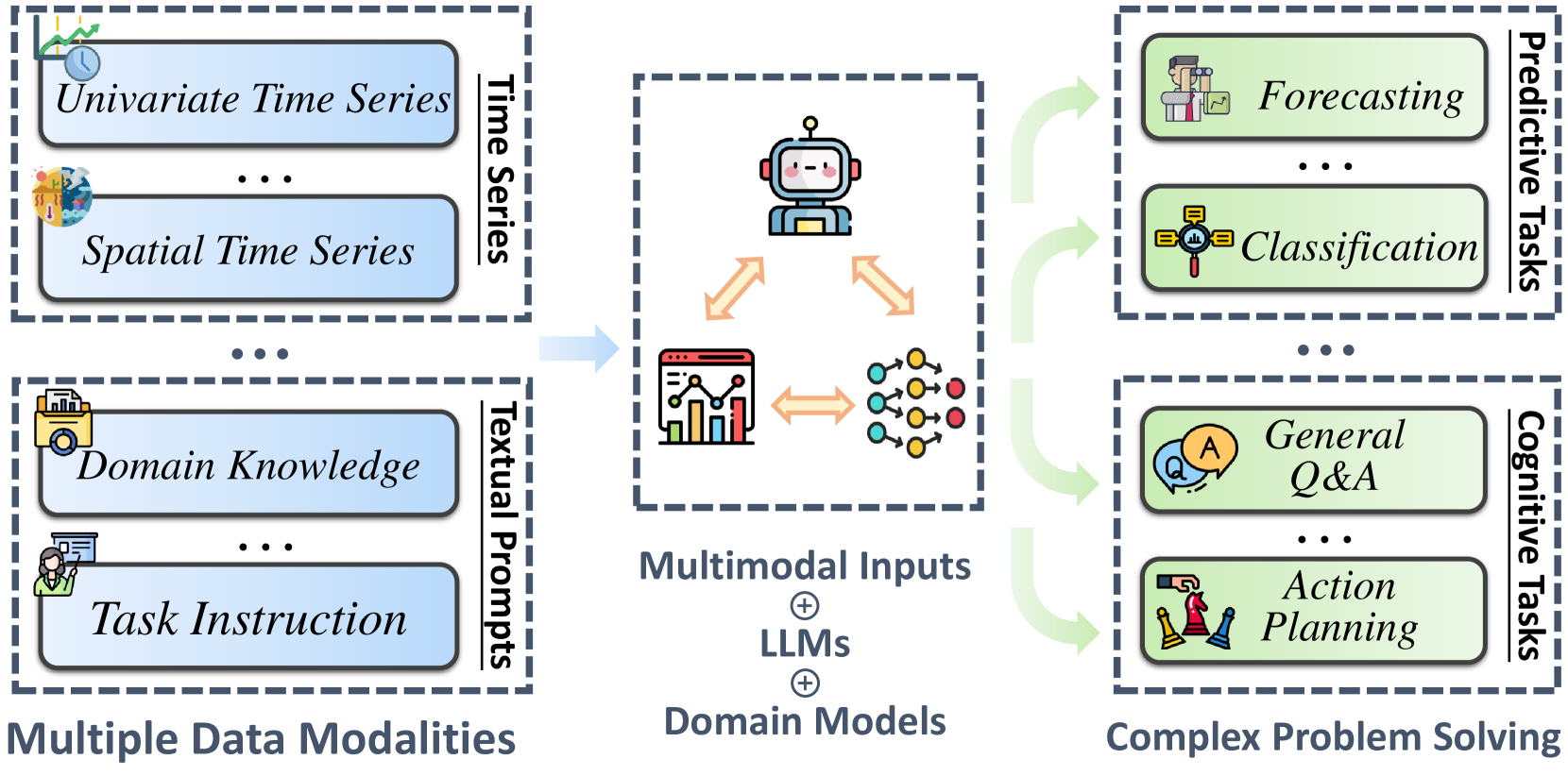
Time series analysis is essential for comprehending the complexities inherent in various realworld systems and applications. Although large language models (LLMs) have recently made significant strides, the development of artificial general intelligence (AGI) equipped with time series analysis capabilities remains in its nascent phase. Most existing time series models heavily rely on domain knowledge and extensive model tuning, predominantly focusing on prediction tasks. In this paper, we argue that current LLMs have the potential to revolutionize time series analysis, thereby promoting efficient decision-making and advancing towards a more universal form of time series analytical intelligence. Such advancement could unlock a wide range of possibilities, including time series modality switching and question answering. We encourage researchers and practitioners to recognize the potential of LLMs in advancing time series analysis and emphasize the need for trust in these related efforts. Furthermore, we detail the seamless integration of time series analysis with existing LLM technologies and outline promising avenues for future research.
6/4/2024