Advancing Cultural Inclusivity: Optimizing Embedding Spaces for Balanced Music Recommendations
2405.17607
0
0
Abstract
Popularity bias in music recommendation systems -- where artists and tracks with the highest listen counts are recommended more often -- can also propagate biases along demographic and cultural axes. In this work, we identify these biases in recommendations for artists from underrepresented cultural groups in prototype-based matrix factorization methods. Unlike traditional matrix factorization methods, prototype-based approaches are interpretable. This allows us to directly link the observed bias in recommendations for minority artists (the effect) to specific properties of the embedding space (the cause). We mitigate popularity bias in music recommendation through capturing both users' and songs' cultural nuances in the embedding space. To address these challenges while maintaining recommendation quality, we propose two novel enhancements to the embedding space: i) we propose an approach to filter-out the irrelevant prototypes used to represent each user and item to improve generalizability, and ii) we introduce regularization techniques to reinforce a more uniform distribution of prototypes within the embedding space. Our results demonstrate significant improvements in reducing popularity bias and enhancing demographic and cultural fairness in music recommendations while achieving competitive -- if not better -- overall performance.
Create account to get full access
Overview
- This paper proposes a new approach to optimize embedding spaces for more balanced and inclusive music recommendations.
- The authors address the problem of popularity bias in music recommendation systems, where popular artists and songs dominate the recommendations.
- They introduce a prototype-based matrix factorization method that aims to improve demographic and cultural fairness in music recommendations.
Plain English Explanation
Music recommendation systems are algorithms that suggest new songs or artists for users to listen to. However, these systems often suffer from popularity bias, where they tend to recommend the most popular and well-known music, rather than a diverse range of artists and genres.
This can lead to certain artists and cultural backgrounds being underrepresented in the recommendations, which can have negative societal impacts. The authors of this paper wanted to address this problem and create a more inclusive and balanced music recommendation system.
They developed a new approach called prototype-based matrix factorization. This method learns embeddings, or numerical representations, of music that capture not just popularity, but also demographic and cultural factors. By optimizing these embeddings, the recommendation system can suggest a more diverse range of music that better reflects the cultural diversity of listeners.
The authors tested their approach on real-world music data and found that it was able to improve demographic and cultural fairness in the music recommendations, without sacrificing overall recommendation quality. This is an important step towards building more equitable and inclusive music recommendation systems.
Technical Explanation
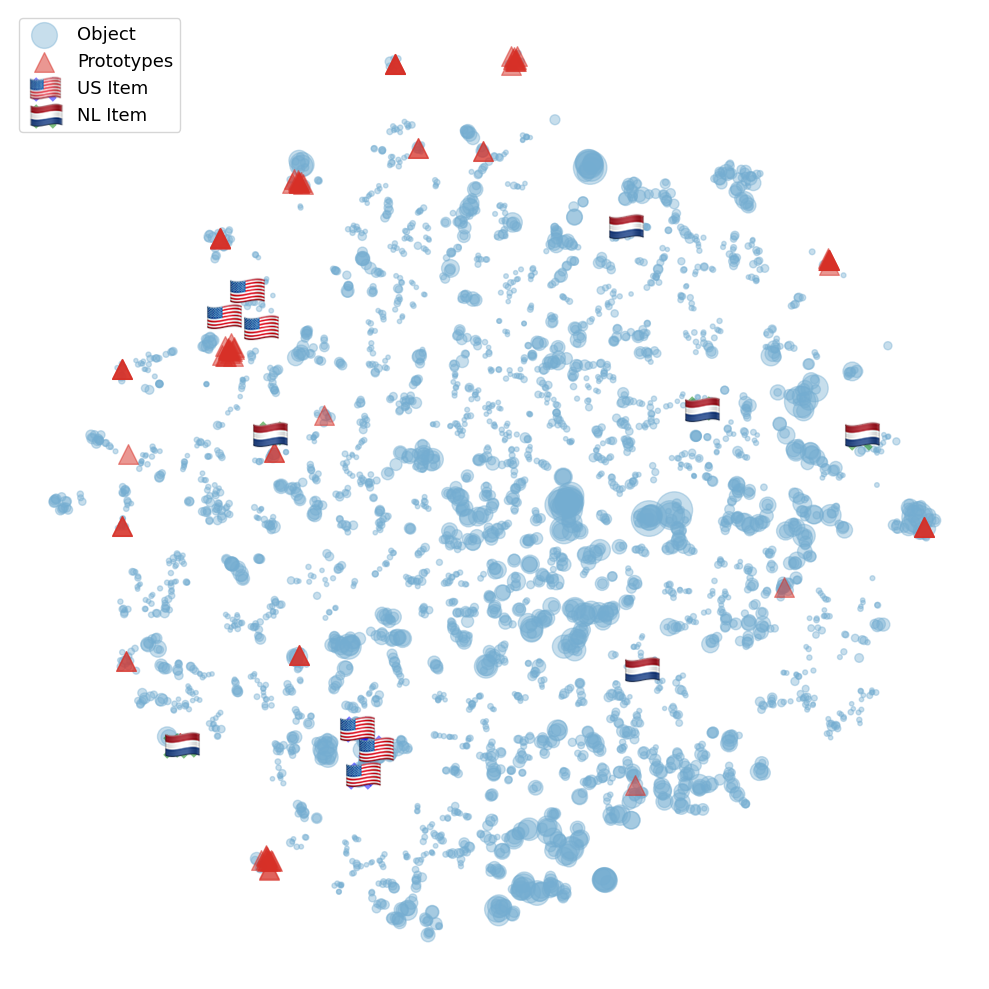
The paper presents a new approach called prototype-based matrix factorization (PBMF) to address the popularity bias in music recommendation systems. The key idea is to learn music embeddings that capture not just popularity, but also demographic and cultural factors.
The PBMF method works by first identifying a set of prototypes, which represent different demographic and cultural groups in the music data. The model then learns embeddings for each music item that are close to the prototypes corresponding to the item's associated demographic and cultural attributes.
This is achieved by modifying the traditional matrix factorization objective function to include a term that encourages the learned embeddings to be close to their assigned prototypes. The authors also introduce a fairness-aware sampling strategy during training to ensure that the model is exposed to a diverse range of music items during the optimization process.
The authors evaluate their approach on two real-world music datasets and show that it can achieve better demographic and cultural fairness in music recommendations compared to baseline methods, without sacrificing overall recommendation performance. They also demonstrate that the learned music embeddings capture meaningful demographic and cultural attributes, which can be useful for understanding and promoting diverse music content.
Critical Analysis
The authors present a compelling approach to address the important problem of popularity bias in music recommendation systems. By incorporating demographic and cultural factors into the embedding learning process, the proposed PBMF method can generate more balanced and inclusive recommendations.
However, the paper does not discuss some potential limitations of the approach. For example, the reliance on predefined prototypes to represent demographic and cultural groups may not fully capture the nuances and intersectionality of real-world music preferences. Additionally, the fairness-aware sampling strategy employed during training may introduce its own biases, which could affect the generalization of the model.
Furthermore, the paper does not provide a deeper analysis of the learned music embeddings and how they relate to specific demographic and cultural attributes. A more detailed exploration of these embeddings and their interpretability could further strengthen the claims about the model's ability to capture meaningful cultural factors.
Despite these caveats, the overall approach presented in the paper is a valuable contribution to the field of music recommendation and demonstrates the importance of addressing fairness and inclusivity in these systems.
Conclusion
This paper proposes a novel prototype-based matrix factorization method to optimize embedding spaces for more balanced and culturally inclusive music recommendations. The key innovation is the incorporation of demographic and cultural factors into the embedding learning process, which helps to address the popularity bias inherent in many music recommendation systems.
The authors demonstrate the effectiveness of their approach on real-world datasets, showing improvements in demographic and cultural fairness without sacrificing overall recommendation performance. This work represents an important step towards building more equitable and diverse music recommendation systems that better serve the needs of all listeners.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

How Do Recommendation Models Amplify Popularity Bias? An Analysis from the Spectral Perspective
Siyi Lin, Chongming Gao, Jiawei Chen, Sheng Zhou, Binbin Hu, Yan Feng, Chun Chen, Can Wang
0
0
Recommendation Systems (RS) are often plagued by popularity bias. When training a recommendation model on a typically long-tailed dataset, the model tends to not only inherit this bias but often exacerbate it, resulting in over-representation of popular items in the recommendation lists. This study conducts comprehensive empirical and theoretical analyses to expose the root causes of this phenomenon, yielding two core insights: 1) Item popularity is memorized in the principal spectrum of the score matrix predicted by the recommendation model; 2) The dimension collapse phenomenon amplifies the relative prominence of the principal spectrum, thereby intensifying the popularity bias. Building on these insights, we propose a novel debiasing strategy that leverages a spectral norm regularizer to penalize the magnitude of the principal singular value. We have developed an efficient algorithm to expedite the calculation of the spectral norm by exploiting the spectral property of the score matrix. Extensive experiments across seven real-world datasets and three testing paradigms have been conducted to validate the superiority of the proposed method.
6/14/2024

On the Embedding Collapse when Scaling up Recommendation Models
Xingzhuo Guo, Junwei Pan, Ximei Wang, Baixu Chen, Jie Jiang, Mingsheng Long
0
0
Recent advances in foundation models have led to a promising trend of developing large recommendation models to leverage vast amounts of available data. Still, mainstream models remain embarrassingly small in size and naive enlarging does not lead to sufficient performance gain, suggesting a deficiency in the model scalability. In this paper, we identify the embedding collapse phenomenon as the inhibition of scalability, wherein the embedding matrix tends to occupy a low-dimensional subspace. Through empirical and theoretical analysis, we demonstrate a emph{two-sided effect} of feature interaction specific to recommendation models. On the one hand, interacting with collapsed embeddings restricts embedding learning and exacerbates the collapse issue. On the other hand, interaction is crucial in mitigating the fitting of spurious features as a scalability guarantee. Based on our analysis, we propose a simple yet effective multi-embedding design incorporating embedding-set-specific interaction modules to learn embedding sets with large diversity and thus reduce collapse. Extensive experiments demonstrate that this proposed design provides consistent scalability and effective collapse mitigation for various recommendation models. Code is available at this repository: https://github.com/thuml/Multi-Embedding.
6/7/2024

Balancing Embedding Spectrum for Recommendation
Shaowen Peng, Kazunari Sugiyama, Xin Liu, Tsunenori Mine
0
0
Modern recommender systems heavily rely on high-quality representations learned from high-dimensional sparse data. While significant efforts have been invested in designing powerful algorithms for extracting user preferences, the factors contributing to good representations have remained relatively unexplored. In this work, we shed light on an issue in the existing pair-wise learning paradigm (i.e., the embedding collapse problem), that the representations tend to span a subspace of the whole embedding space, leading to a suboptimal solution and reducing the model capacity. Specifically, optimization on observed interactions is equivalent to a low pass filter causing users/items to have the same representations and resulting in a complete collapse. While negative sampling acts as a high pass filter to alleviate the collapse by balancing the embedding spectrum, its effectiveness is only limited to certain losses, which still leads to an incomplete collapse. To tackle this issue, we propose a novel method called DirectSpec, acting as a reliable all pass filter to balance the spectrum distribution of the embeddings during training, ensuring that users/items effectively span the entire embedding space. Additionally, we provide a thorough analysis of DirectSpec from a decorrelation perspective and propose an enhanced variant, DirectSpec+, which employs self-paced gradients to optimize irrelevant samples more effectively. Moreover, we establish a close connection between DirectSpec+ and uniformity, demonstrating that contrastive learning (CL) can alleviate the collapse issue by indirectly balancing the spectrum. Finally, we implement DirectSpec and DirectSpec+ on two popular recommender models: MF and LightGCN. Our experimental results demonstrate its effectiveness and efficiency over competitive baselines.
6/19/2024

Knowledge Graph Context-Enhanced Diversified Recommendation
Xiaolong Liu, Liangwei Yang, Zhiwei Liu, Mingdai Yang, Chen Wang, Hao Peng, Philip S. Yu
0
0
The field of Recommender Systems (RecSys) has been extensively studied to enhance accuracy by leveraging users' historical interactions. Nonetheless, this persistent pursuit of accuracy frequently engenders diminished diversity, culminating in the well-recognized echo chamber phenomenon. Diversified RecSys has emerged as a countermeasure, placing diversity on par with accuracy and garnering noteworthy attention from academic circles and industry practitioners. This research explores the realm of diversified RecSys within the intricate context of knowledge graphs (KG). These KGs act as repositories of interconnected information concerning entities and items, offering a propitious avenue to amplify recommendation diversity through the incorporation of insightful contextual information. Our contributions include introducing an innovative metric, Entity Coverage, and Relation Coverage, which effectively quantifies diversity within the KG domain. Additionally, we introduce the Diversified Embedding Learning (DEL) module, meticulously designed to formulate user representations that possess an innate awareness of diversity. In tandem with this, we introduce a novel technique named Conditional Alignment and Uniformity (CAU). It adeptly encodes KG item embeddings while preserving contextual integrity. Collectively, our contributions signify a substantial stride towards augmenting the panorama of recommendation diversity within the realm of KG-informed RecSys paradigms.
4/23/2024