On the Embedding Collapse when Scaling up Recommendation Models

0

Sign in to get full access
Overview
- Discusses the phenomenon of "embedding collapse" in large-scale recommendation models
- Explores how the feature representations (embeddings) of items can become increasingly similar as model size increases
- Investigates the implications of this collapse on model performance and scalability
Plain English Explanation
As recommendation models grow larger and more complex, a curious thing can happen: the unique feature representations (known as "embeddings") of the items being recommended start to become more and more similar to each other. This "embedding collapse" can have significant consequences for the model's performance and ability to scale effectively.
At a high level, recommendation models work by learning distinct representations for each item (e.g. a product, video, or piece of content) that capture its unique features and properties. These learned embeddings are then used to make personalized recommendations by identifying items with similar representations to a user's preferences.
However, as these models grow larger and more powerful, there appears to be a tendency for the embeddings to converge and lose their distinctiveness. In other words, the model may struggle to maintain unique representations for a large and diverse catalog of items. This can degrade the model's ability to make accurate and diverse recommendations, as it becomes harder to differentiate between items.
The reasons behind this embedding collapse are not fully understood, but may be related to factors like the model's architecture, the training data and objectives, and the inherent complexity of large-scale recommendation problems. Addressing this challenge is crucial for developing recommendation systems that can scale effectively while maintaining high performance.
Technical Explanation
The paper investigates the phenomenon of "embedding collapse" in large-scale recommendation models. Specifically, the authors observe that as the size and complexity of these models increase, the feature representations (embeddings) of the items being recommended tend to become increasingly similar, losing their distinctiveness.
To study this effect, the authors conduct experiments on several popular recommendation model architectures, including matrix factorization, neural collaborative filtering, and transformer-based models. They systematically scale up the size of these models and measure the degree of embedding collapse, as well as the impact on overall recommendation performance.
The results show that as the model size increases, the embeddings do indeed become more and more entangled, with the average cosine similarity between embeddings rising significantly. This collapse in feature space has a negative impact on the models' ability to make accurate and diverse recommendations, as it becomes harder to differentiate between items.
The paper also explores potential causes of this embedding collapse, including the role of model architecture, optimization objectives, and the inherent complexity of large-scale recommendation problems. The authors discuss how these factors may contribute to the tendency for embeddings to converge, and they suggest potential strategies for mitigating this issue, such as dynamic embedding size search and improved regularization techniques.
Critical Analysis
The paper provides a valuable investigation into an important challenge facing large-scale recommendation systems: the phenomenon of embedding collapse. The authors present a thorough empirical analysis and offer insights into the potential drivers of this issue.
One limitation of the study is that it focuses primarily on the symptom of embedding collapse, without delving deeply into the underlying mechanisms that may be causing it. While the authors suggest potential contributing factors, more research is needed to fully understand the root causes and develop effective solutions.
Additionally, the paper does not address the potential implications of embedding collapse beyond recommendation performance, such as the impact on model interpretability and explainability. As recommendation systems become more prevalent and influential, it is important to consider the broader societal implications of these models' behavior.
Overall, the paper makes a valuable contribution by highlighting a significant challenge in the field of large-scale recommendation systems. The findings and insights provided can serve as a starting point for further research and development in this area, with the goal of creating more scalable, performant, and responsible recommendation technologies.
Conclusion
This paper sheds light on the important problem of "embedding collapse" in large-scale recommendation models. As these models grow in size and complexity, the feature representations (embeddings) of the items being recommended tend to become increasingly similar, leading to a degradation in the models' ability to make accurate and diverse recommendations.
The authors' systematic investigation of this phenomenon across multiple model architectures provides valuable empirical evidence and insights into the potential causes and implications of embedding collapse. While further research is needed to fully understand the underlying mechanisms and develop effective mitigation strategies, this paper represents an important step forward in addressing a critical challenge facing the field of large-scale recommendation systems.
As the role of recommendation technologies continues to grow, it will be crucial for researchers and practitioners to tackle issues like embedding collapse in order to create recommendation systems that are scalable, performant, and responsible. The findings and insights from this paper can serve as a foundation for these ongoing efforts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the Embedding Collapse when Scaling up Recommendation Models
Xingzhuo Guo, Junwei Pan, Ximei Wang, Baixu Chen, Jie Jiang, Mingsheng Long
Recent advances in foundation models have led to a promising trend of developing large recommendation models to leverage vast amounts of available data. Still, mainstream models remain embarrassingly small in size and naive enlarging does not lead to sufficient performance gain, suggesting a deficiency in the model scalability. In this paper, we identify the embedding collapse phenomenon as the inhibition of scalability, wherein the embedding matrix tends to occupy a low-dimensional subspace. Through empirical and theoretical analysis, we demonstrate a emph{two-sided effect} of feature interaction specific to recommendation models. On the one hand, interacting with collapsed embeddings restricts embedding learning and exacerbates the collapse issue. On the other hand, interaction is crucial in mitigating the fitting of spurious features as a scalability guarantee. Based on our analysis, we propose a simple yet effective multi-embedding design incorporating embedding-set-specific interaction modules to learn embedding sets with large diversity and thus reduce collapse. Extensive experiments demonstrate that this proposed design provides consistent scalability and effective collapse mitigation for various recommendation models. Code is available at this repository: https://github.com/thuml/Multi-Embedding.
Read more6/7/2024
0
Ads Recommendation in a Collapsed and Entangled World
Junwei Pan, Wei Xue, Ximei Wang, Haibin Yu, Xun Liu, Shijie Quan, Xueming Qiu, Dapeng Liu, Lei Xiao, Jie Jiang
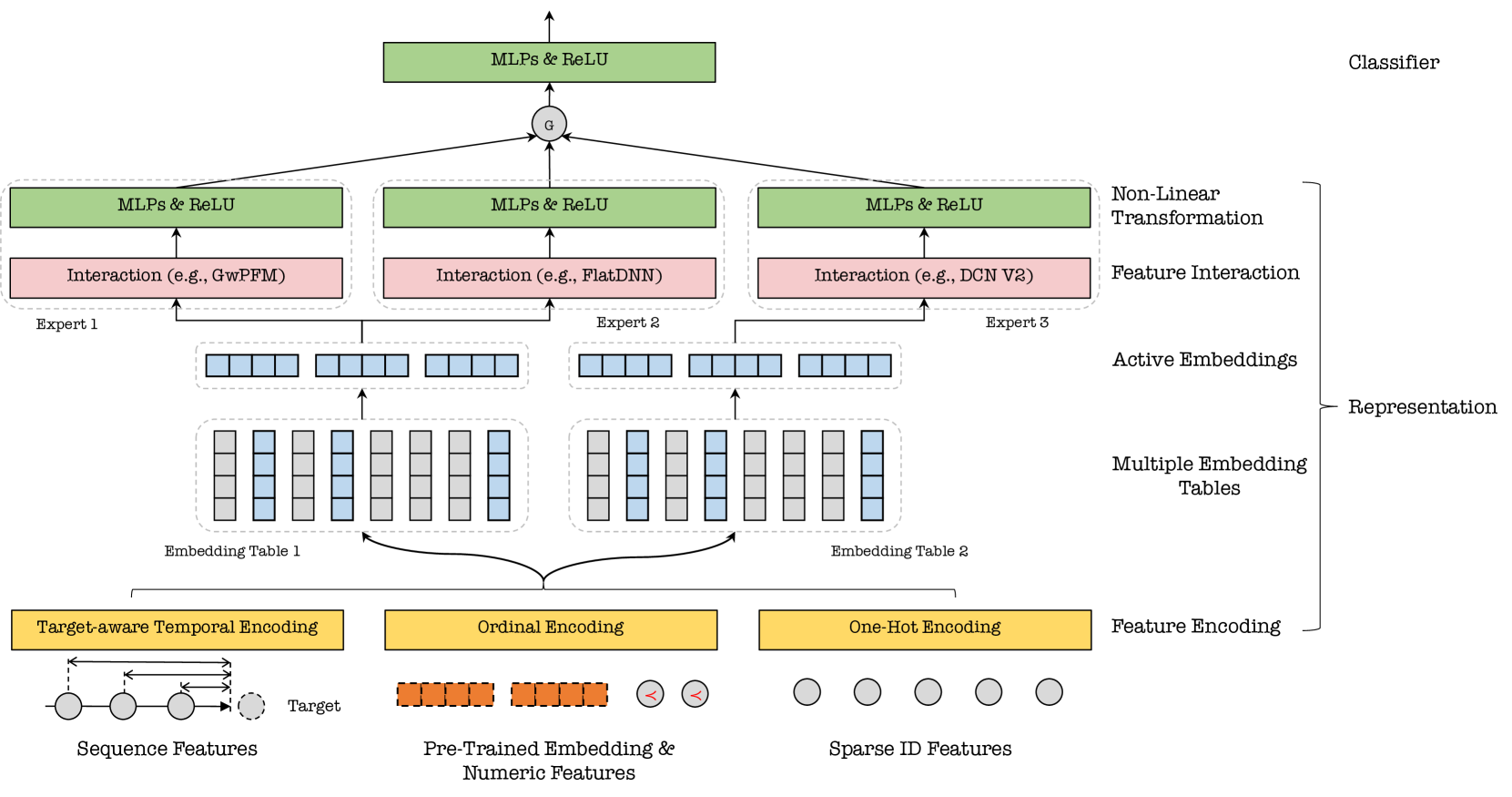
We present Tencent's ads recommendation system and examine the challenges and practices of learning appropriate recommendation representations. Our study begins by showcasing our approaches to preserving prior knowledge when encoding features of diverse types into embedding representations. We specifically address sequence features, numeric features, and pre-trained embedding features. Subsequently, we delve into two crucial challenges related to feature representation: the dimensional collapse of embeddings and the interest entanglement across different tasks or scenarios. We propose several practical approaches to address these challenges that result in robust and disentangled recommendation representations. We then explore several training techniques to facilitate model optimization, reduce bias, and enhance exploration. Additionally, we introduce three analysis tools that enable us to study feature correlation, dimensional collapse, and interest entanglement. This work builds upon the continuous efforts of Tencent's ads recommendation team over the past decade. It summarizes general design principles and presents a series of readily applicable solutions and analysis tools. The reported performance is based on our online advertising platform, which handles hundreds of billions of requests daily and serves millions of ads to billions of users.
Read more7/9/2024
0
Scalable Dynamic Embedding Size Search for Streaming Recommendation
Yunke Qu, Liang Qu, Tong Chen, Xiangyu Zhao, Quoc Viet Hung Nguyen, Hongzhi Yin
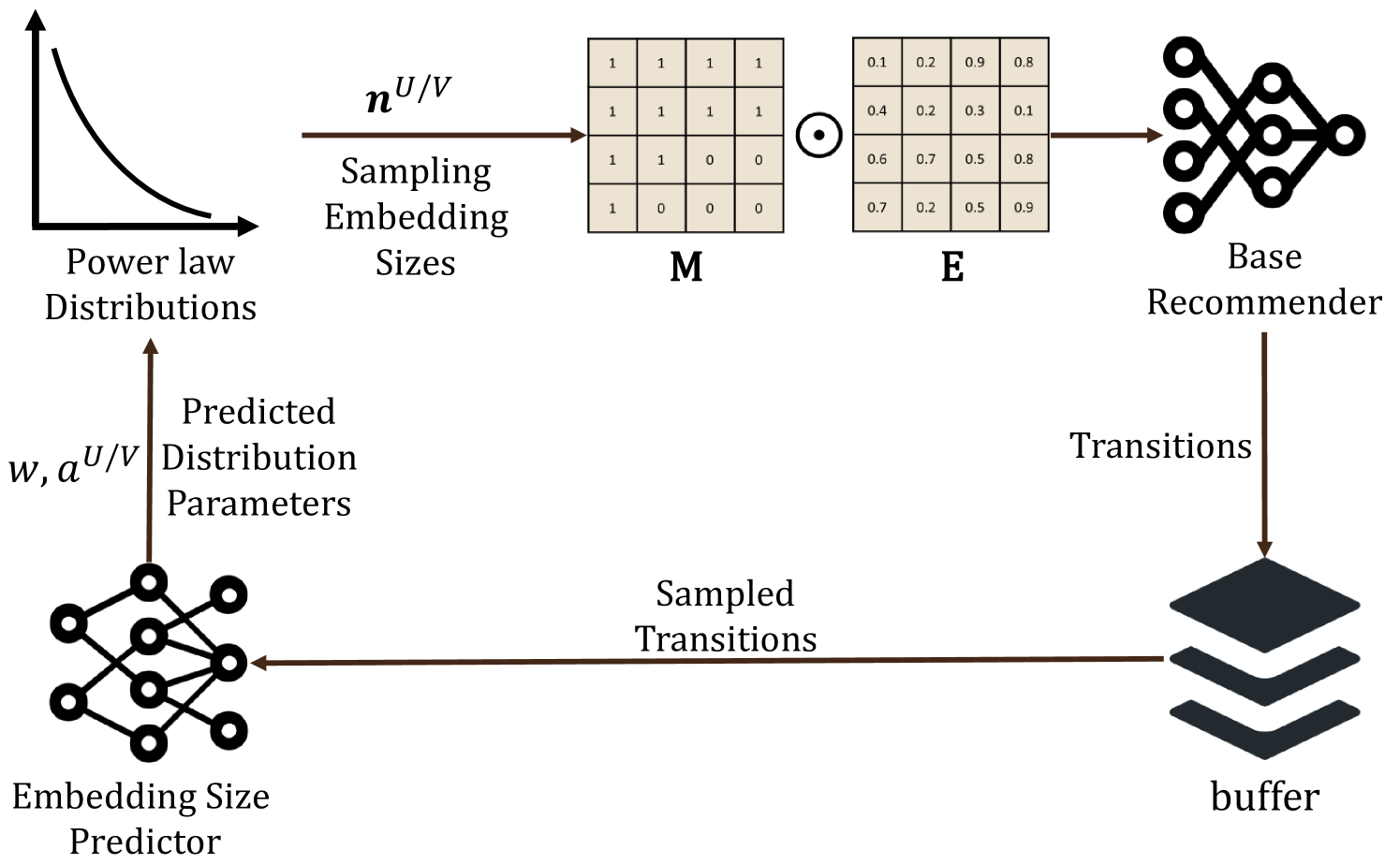
Recommender systems typically represent users and items by learning their embeddings, which are usually set to uniform dimensions and dominate the model parameters. However, real-world recommender systems often operate in streaming recommendation scenarios, where the number of users and items continues to grow, leading to substantial storage resource consumption for these embeddings. Although a few methods attempt to mitigate this by employing embedding size search strategies to assign different embedding dimensions in streaming recommendations, they assume that the embedding size grows with the frequency of users/items, which eventually still exceeds the predefined memory budget over time. To address this issue, this paper proposes to learn Scalable Lightweight Embeddings for streaming recommendation, called SCALL, which can adaptively adjust the embedding sizes of users/items within a given memory budget over time. Specifically, we propose to sample embedding sizes from a probabilistic distribution, with the guarantee to meet any predefined memory budget. By fixing the memory budget, the proposed embedding size sampling strategy can increase and decrease the embedding sizes in accordance to the frequency of the corresponding users or items. Furthermore, we develop a reinforcement learning-based search paradigm that models each state with mean pooling to keep the length of the state vectors fixed, invariant to the changing number of users and items. As a result, the proposed method can provide embedding sizes to unseen users and items. Comprehensive empirical evaluations on two public datasets affirm the advantageous effectiveness of our proposed method.
Read more8/1/2024

0
Towards Fundamentally Scalable Model Selection: Asymptotically Fast Update and Selection
Wenxiao Wang, Weiming Zhuang, Lingjuan Lyu
The advancement of deep learning technologies is bringing new models every day, motivating the study of scalable model selection. An ideal model selection scheme should minimally support two operations efficiently over a large pool of candidate models: update, which involves either adding a new candidate model or removing an existing candidate model, and selection, which involves locating highly performing models for a given task. However, previous solutions to model selection require high computational complexity for at least one of these two operations. In this work, we target fundamentally (more) scalable model selection that supports asymptotically fast update and asymptotically fast selection at the same time. Firstly, we define isolated model embedding, a family of model selection schemes supporting asymptotically fast update and selection: With respect to the number of candidate models $m$, the update complexity is O(1) and the selection consists of a single sweep over $m$ vectors in addition to O(1) model operations. Isolated model embedding also implies several desirable properties for applications. Secondly, we present Standardized Embedder, an empirical realization of isolated model embedding. We assess its effectiveness by using it to select representations from a pool of 100 pre-trained vision models for classification tasks and measuring the performance gaps between the selected models and the best candidates with a linear probing protocol. Experiments suggest our realization is effective in selecting models with competitive performances and highlight isolated model embedding as a promising direction towards model selection that is fundamentally (more) scalable.
Read more6/12/2024